
You might like














Our paper "MaskControl: Spatio-Temporal Control for Masked Motion Synthesis" has been selected as an 🏆 Award Candidate at ICCV 2025! 🌺✨ It’s a huge honor to see our work recognized among the top papers this year.

framework for domain-specific knowledge extraction and reasoning with LLMs




New APPLE paper says a small base model plus fetched memories can act like a bigger one. With about 10% extra fetched parameters, a 160M model matches models over 2x its size. Packing all facts into fixed weights wastes memory and compute because each query needs very little.…

Import 3D models, auto-rig and export animations in your browser

The paper links Kolmogorov complexity to Transformers and proposes loss functions that become provably best as model resources grow. It treats learning as compression, minimize bits to describe the model plus bits to describe the labels. Provides a single training target that…


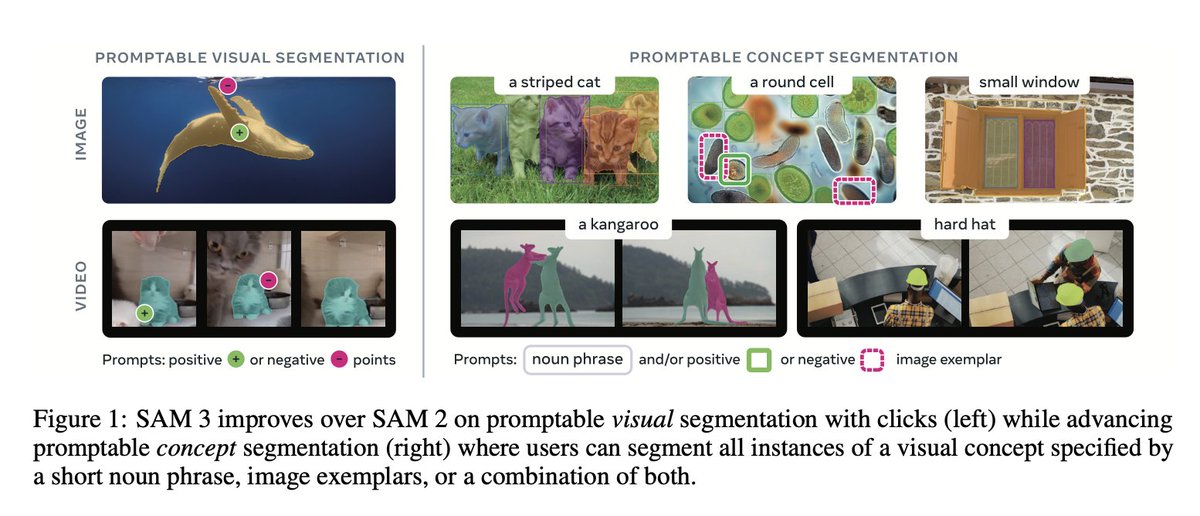
Segment Anything 3 just silently dropped on ICLR 🤯 The first SAM let you click on an object to segment it. SAM 2 added video and memory. Now SAM 3 says: just describe what you want — “yellow school bus”, “striped cat”, “red apple” — and it will find and segment every instance…



Just a bit of weekend coding fun: A memory estimator to calculate the savings when using grouped-query attention vs multi-head attention (+ code implementations of course). 🔗 github.com/rasbt/LLMs-fro… Will add this for multi-head latent, sliding, and sparse attention as well.


🎬 Introducing: Character Mixing for Video Generation Imagine Mr. Bean stepping into Tom & Jerry's world 🐭✨ Now it's possible! ✨ Our framework first enables natural cross-character interactions in text-to-video generation while preserving identity and style fidelity.

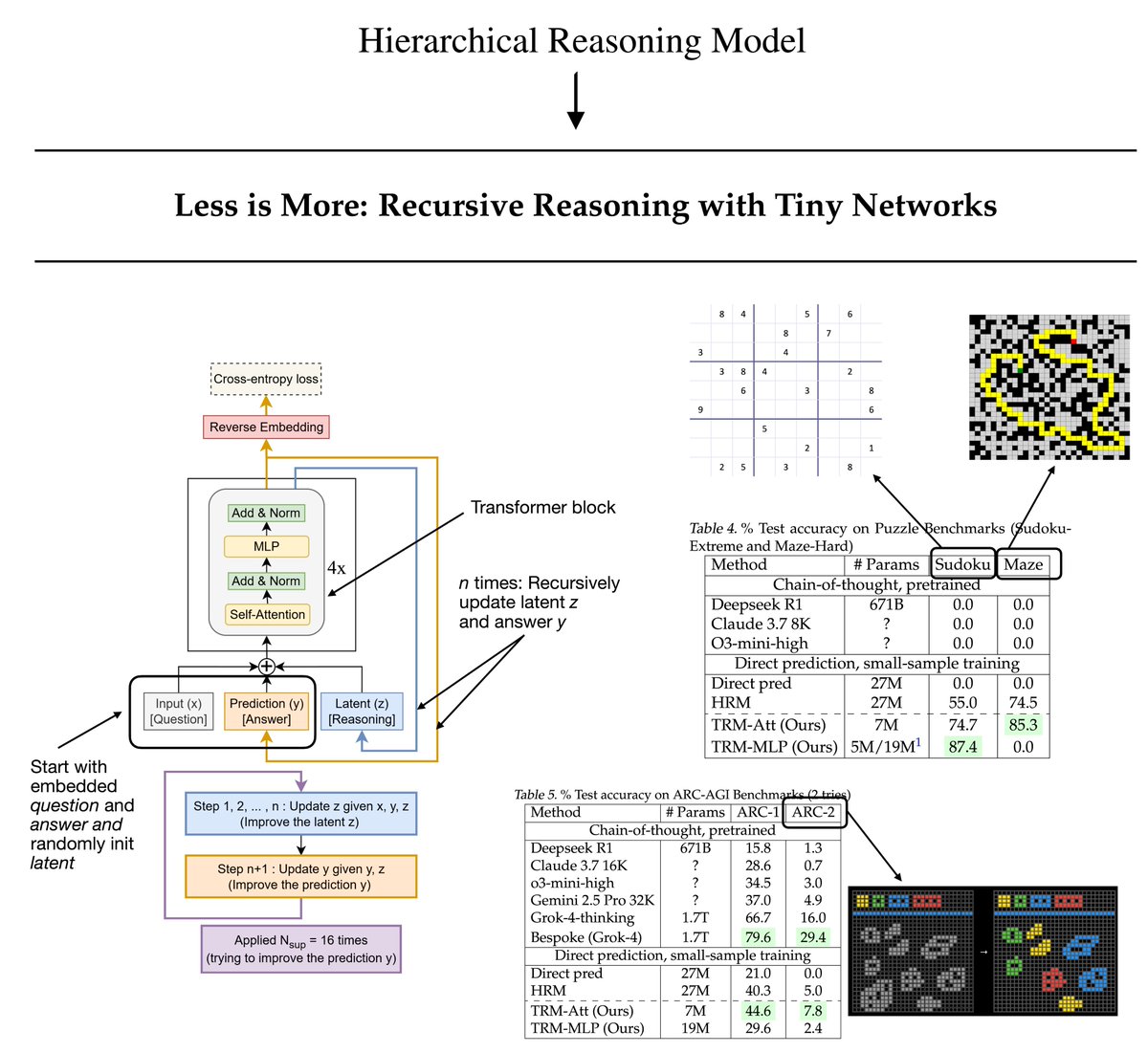
Samsung's Tiny Recursive Model (TRM) masters complex reasoning With just 7M parameters, TRM outperforms large LLMs on hard puzzles like Sudoku & ARC-AGI. This "Less is More" approach redefines efficiency in AI, using less than 0.01% of competitors' parameters!


Ever wondered what CAN'T be transformed by Transformers? 🪨 I wrote a fun blog post on finding "fixed points" of your LLMs. If you prompt it with a fixed point token, the LLM is gonna decode it repeatedly forever, guaranteed. There's some connection with LLMs' repetition issue.

From the Hierarchical Reasoning Model (HRM) to a new Tiny Recursive Model (TRM). A few months ago, the HRM made big waves in the AI research community as it showed really good performance on the ARC challenge despite its small 27M size. (That's about 22x smaller than the…

Excited to share Equilibrium Matching (EqM)! EqM simplifies and outperforms flow matching, enabling strong generative performance of FID 1.96 on ImageNet 256x256. EqM learns a single static EBM landscape for generation, enabling a simple gradient-based generation procedure.

Flow Autoencoders Are Effective Protein Tokenizers 1. The article introduces Kanzi, a novel flow-based tokenizer for protein structures that simplifies the training process and achieves state-of-the-art performance in protein structure tokenization and generation. 2. Kanzi uses…


An intriguing paper from Apple. MoEs Are Stronger than You Think: Hyper-Parallel Inference Scaling with RoE Paper: arxiv.org/abs/2509.17238

⏱️ New Time series research from @GoogleResearch Shows a new approach to time-series forecasting that uses continued pre-training to teach a time-series foundation model to adapt to in-context examples at inference time. The big deal is that time series forecasting finally…

Google research publishes on a better way for AI health assistant. Wayfinding AI shows that asking a few targeted questions first produces more helpful and more tailored health info than a one-shot answer. The idea is to make online health conversations more natural and useful,…


You can teach a Transformer to execute a simple algorithm if you provide the exact step by step algorithm during training via CoT tokens. This is interesting, but the point of machine learning should be to *find* the algorithm during training, from input/output pairs only -- not…
A beautiful paper from MIT+Harvard+ @GoogleDeepMind 👏 Explains why Transformers miss multi digit multiplication and shows a simple bias that fixes it. The researchers trained two small Transformer models on 4-digit-by-4-digit multiplication. One used a special training method…




Negative Log-Likelihood (NLL) has long been the go-to objective for classification and SFT, but is it universally optimal? We explore when alternative objectives outperform NLL and when they don't, based on two key factors: the objective's prior-leaningness and the model's…

































































































United States Trends
- 1. Jets 73.8K posts
- 2. Jets 73.8K posts
- 3. Aaron Glenn 3,769 posts
- 4. Justin Fields 5,585 posts
- 5. #HardRockBet 2,892 posts
- 6. Garrett Wilson 2,668 posts
- 7. London 206K posts
- 8. HAPPY BIRTHDAY JIMIN 108K posts
- 9. #OurMuseJimin 155K posts
- 10. #JetUp 1,679 posts
- 11. #DENvsNYJ 1,770 posts
- 12. Sean Payton N/A
- 13. Peart 1,778 posts
- 14. Tyrod N/A
- 15. Bo Nix 2,355 posts
- 16. #30YearsofLove 140K posts
- 17. Bam Knight N/A
- 18. Sherwood 1,179 posts
- 19. Kurt Warner N/A
- 20. Hail Mary 2,486 posts
You might like
-
 MetaverseAIGC Films
MetaverseAIGC Films
@MetaverseAIGC -
 Kaká
Kaká
@firqaaaa -
 ismail TG
ismail TG
@ismailTG3 -
 Paul Ships ⚡
Paul Ships ⚡
@paulshipfast -
 Krunoslav Lehman Pavasovic
Krunoslav Lehman Pavasovic
@KrunoLehman -
 Polo M (slow/steady)
Polo M (slow/steady)
@traintest_split -
 Mellen Y. Pu
Mellen Y. Pu
@CassielYM -
 Raj Gupta
Raj Gupta
@the_perceptron -
 Atena G. Mohammadi
Atena G. Mohammadi
@AtenaGMohammadi -
 bharadwaj
bharadwaj
@bharadwajymg -
 Mohit Nihalani
Mohit Nihalani
@MohitNihalani9 -
 jums
jums
@devjumzzz -
 thekeeper
thekeeper
@thekeeper33
Something went wrong.
Something went wrong.