
DeepSpeed
@DeepSpeedAI
Official account for DeepSpeed, a library that enables unprecedented scale and speed for deep learning training + inference. 日本語 : @DeepSpeedAI_JP
Bạn có thể thích















UIUC, AnyScale, and Snowflake significantly enhanced LLM offloading for the Superchip era!

🚀 SuperOffload: Unleashing the Power of Large-Scale LLM Training on Superchips Superchips like the NVIDIA GH200 offer tightly coupled GPU-CPU architectures for AI workloads. But most existing offloading techniques were designed for traditional PCIe-based systems. Are we truly…

It's nice to share the most recent updates from the DeepSpeed project at #PyTorchCon, we will continue pushing the boundary of LLM distributed training for the OSS community.

🎙️ Mic check: Tunji Ruwase, Lead, DeepSpeed Project & Principal Engineer at Snowflake, is bringing the 🔥 to the keynote stage at #PyTorchCon! Get ready for big ideas and deeper learning October 22–23 in San Francisco. 👀 Speakers: hubs.la/Q03GPYFn0 🎟️…


🚨Meetup Alert🚨 Join us for @raydistributed × @DeepSpeedAI Meetup: AI at Scale, including talks from researchers and engineers at @LinkedIn, @anyscalecompute and @Snowflake. Learn how leading AI teams are scaling efficiently with Ray’s distributed framework and DeepSpeed’s…

Step into the future of AI at #PyTorchCon 2025, Oct 22–23 in San Francisco 🔥 Join the DeepSpeed keynote and technical talks. Register: events.linuxfoundation.org/pytorch-confer… + Oct 21 co-located events: Measuring Intelligence, Open Agent & AI Infra Summits / Startup Showcase & PyTorch Training


The @DeepSpeedAI would like to thank @modal for sponsoring our gpus for CI. This is an amazing contribution to our AI-democratizing open source project. github.com/deepspeedai/De… The Modal team is outstanding in their amazing support - speed, expertise and a human experience!

ZenFlow is a massive improvement to DeepSpeed Offloading. Courtesy of an excellent collaboration among University of Virginia, UC Merced, Argonne National Laboratory, Microsoft, and Snowflake.
Introducing #ZenFlow: No Compromising Speed for #LLM Training w/ Offloading 5× faster LLM training with offloading 85% less GPU stalls 2× lower I/O overhead 🚀 Blog: hubs.la/Q03DJ6GJ0 🚀 Try ZenFlow and experience 5× faster training with offloading: hubs.la/Q03DJ6Vb0

Kudos to Xinyu for giving an excellent presentation of DeepSpeed Universal Checkpointing (UCP) paper at USENIX ATC 2015.
📢 Yesterday at USENIX ATC 2025, Xinyu Lian from UIUC SSAIL Lab presented our paper on Universal Checkpointing (UCP). UCP is a new distributed checkpointing system designed for today's large-scale DNN training, where models often use complex forms of parallelism, including data,…

My first project at @Snowflake AI Research is complete! I present to you Arctic Long Sequence Training (ALST) Paper: arxiv.org/abs/2506.13996 Blog: snowflake.com/en/engineering… ALST is a set of modular, open-source techniques that enable training on sequences up to 15 million…

Improved DeepNVMe: Affordable I/O Scaling for AI - Faster I/O with PCIe Gen5 - 20x faster model checkpointing - Low-budget SGLang inference via NVMe offloading - Pinned memory for CPU-only workloads - Zero-copy tensor type casting Blog: tinyurl.com/yanbrjy9



PyTorch Foundation has expanded into an umbrella foundation. @vllm_project and @DeepSpeedAI have been accepted as hosted projects, advancing community-driven AI across the full lifecycle. Supporting quotes provided by the following members: @AMD, @Arm, @AWS, @Google, @Huawei,…

Come hear all the exciting DeepSpeed updates at the upcoming PyTorch Day France 2025 DeepSpeed – Efficient Training Scalability for Deep Learning Models - sched.co/21nyy @sched
Introducing 🚀DeepCompile🚀: compiler-based distributed training optimizations. - Automatic parallelization & profile-guided optimizations - Enable ZeRO1, ZeRO3, Offloading, etc. via compiler passes - 1.2X-7X speedups over manual ZeRO1/ZeRO3/Offloading tinyurl.com/8cys28xk

AutoTP + ZeRO Training for HF Models - Enhance HF post-training with larger models, batches, & contexts - 4x faster LLAMA3 fine-tuning with TP=2 vs TP=1 - No code changes needed Blog: tinyurl.com/5n8nfs2w


1/4⚡️nanoton now supports DoMiNo with intra-layer communication overlapping, achieving 60% communication hiding for tensor parallelism (TP) in both the forward and backward passes while maintaining the same training loss.



🚀 Excited to introduce DeepSpeed, a deep learning optimization library from @Microsoft! It simplifies distributed training and inference, making AI scaling more efficient and cost-effective. Learn more 👉 hubs.la/Q0351DJC0 #DeepSpeed #AI #OpenSource #LFAIData

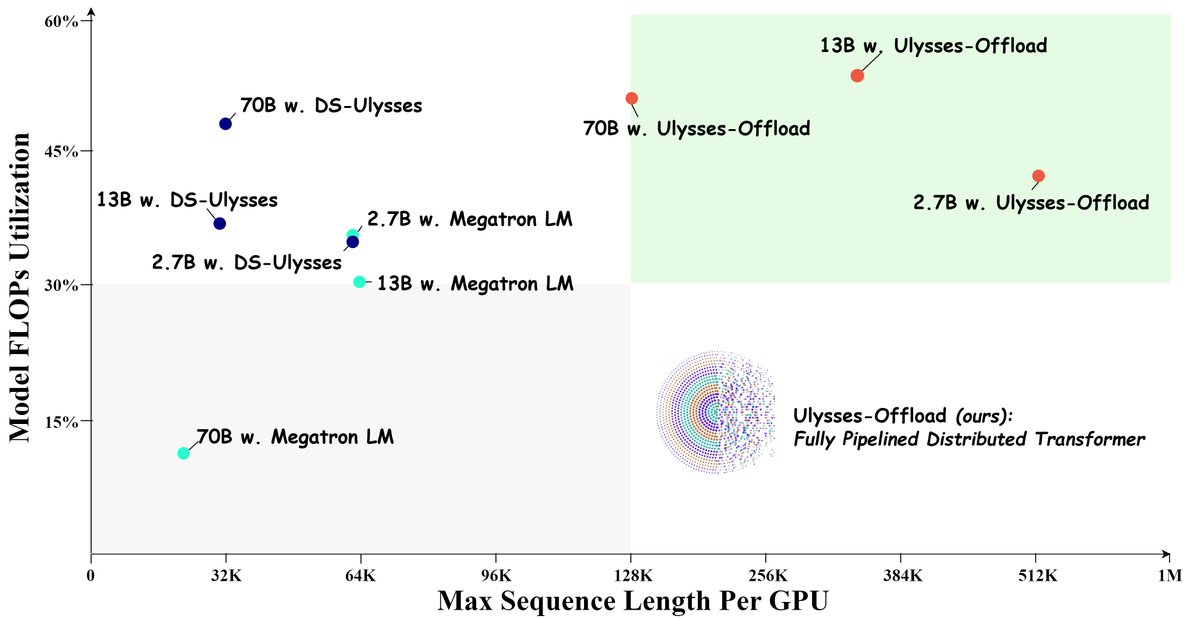
🚀Introducing Ulysses-Offload🚀 - Unlock the power of long context LLM training and finetuning with our latest system optimizations - Train LLaMA3-8B on 2M tokens context using 4xA100-80GB - Achieve over 55% MFU Blog: shorturl.at/Spx6Y Tutorial: shorturl.at/bAWu5
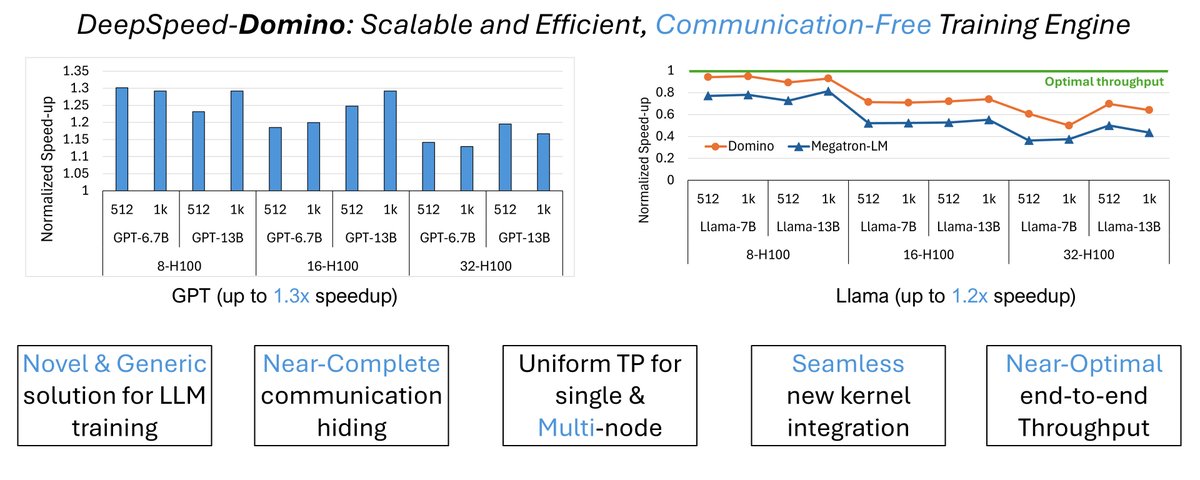
Introducing Domino: a novel zero-cost communication tensor parallelism (TP) training engine for both single node and multi-node settings. - Near-complete communication hiding - Novel multi-node scalable TP solution Blog: github.com/microsoft/Deep…
Great to see the amazing DeepSpeed optimizations from @Guanhua_Wang_, Heyang Qin, @toh_tana, @QuentinAnthon15, and @samadejacobs presented by @ammar_awan at MUG '24.

Dr. Ammar Ahmad Awan from Microsoft DeepSpeed giving a presentation at MUG '24 over Trillion-parameter LLMs and optimization with MVAPICH. @OSUengineering @Microsoft @OhTechCo @mvapich @MSFTDeepSpeed @MSFTDeepSpeedJP #MUG24 #MPI #AI #LLM #DeepSpeed




Announcing that DeepSpeed now runs natively on Windows. This exciting combination unlocks DeepSpeed optimizations to Windows users and empowers more people and organizations with AI innovations. - HF Inference & Finetuning - LoRA - CPU Offload Blog: shorturl.at/a7TF8


💡Check out Comet’s latest integration with DeepSpeed, a deep learning optimization library! 🤝With the @MSFTDeepSpeed + @Cometml integration automatically start logging training metrics generated by DeepSpeed. Try the quick-start Colab to get started: colab.research.google.com/github/comet-m…




























































































United States Xu hướng
- 1. Spotify 1.27M posts
- 2. Giannis 32K posts
- 3. #WhyIChime 1,275 posts
- 4. Chris Paul 43.8K posts
- 5. Clippers 59.2K posts
- 6. Hartline 15.2K posts
- 7. Ty Lue 5,977 posts
- 8. Merino 16.9K posts
- 9. Bucks 23.8K posts
- 10. Apple Music 228K posts
- 11. Madueke 9,997 posts
- 12. Trent 26.6K posts
- 13. Ben White 4,170 posts
- 14. Milwaukee 11.9K posts
- 15. Mike Lindell 3,245 posts
- 16. Mbappe 95.4K posts
- 17. Jack Smith 25.9K posts
- 18. SNAP 167K posts
- 19. Shams 2,055 posts
- 20. #VoluMOASS N/A
Bạn có thể thích
-
 Reka
Reka
@RekaAILabs -
 lmarena.ai
lmarena.ai
@arena -
 Jan Leike
Jan Leike
@janleike -
 Tri Dao
Tri Dao
@tri_dao -
 Databricks Mosaic Research
Databricks Mosaic Research
@DbrxMosaicAI -
 Susan Zhang
Susan Zhang
@suchenzang -
 Hadi Salman
Hadi Salman
@hadisalmanX -
 Harrison Chase
Harrison Chase
@hwchase17 -
 Jerry Liu
Jerry Liu
@jerryjliu0 -
 Wenhu Chen
Wenhu Chen
@WenhuChen -
 LlamaIndex 🦙
LlamaIndex 🦙
@llama_index -
 Yi Tay
Yi Tay
@YiTayML -
 Georgi Gerganov
Georgi Gerganov
@ggerganov -
 Julien Chaumond
Julien Chaumond
@julien_c -
 Lior Alexander
Lior Alexander
@LiorOnAI
Something went wrong.
Something went wrong.