
Duc Anh Nguyen
@duc_anh2k2
AI Resident @ Qualcomm (Ex VinAI Research) #MachineLearning #Mixtureofexperts #Mamba #PEFT

Alex is currently on the faculty job market! He is an incredible researcher! In fact, my interest in Gaussian processes was sparked by his work.

Today, I gave a talk at the INFORMS Job Market Showcase! If you're interested, here are the slides - link below!


Nice cheat sheet for LLM terminology!

- you are - a random CS grad with 0 clue how LLMs work - get tired of people gatekeeping with big words and tiny GPUs - decide to go full monk mode - 2 years later i can explain attention mechanisms at parties and ruin them - here’s the forbidden knowledge map - top to bottom,…

Couldn't resist. Here's a pure PyTorch from-scratch re-implementation of Gemma 3 270M in a Jupyter Notebook (uses about 1.49 GB RAM): github.com/rasbt/LLMs-fro…

Gemma 3 270M! Great to see another awesome, small open-weight LLM for local tinkering. Here's a side-by-side comparison with Qwen3. Biggest surprise that it only has 4 attention heads!




Summary of GPT-OSS architectural innovations: 1. sliding window attention (ref: arxiv.org/abs/1901.02860) 2. mixture of experts (ref: arxiv.org/abs/2101.03961) 3. RoPE w/ Yarn (ref: arxiv.org/abs/2309.00071) 4. attention sinks (ref: streaming llm arxiv.org/abs/2309.17453)

what are large language models actually doing? i read the 2025 textbook "Foundations of Large Language Models" by tong xiao and jingbo zhu and for the first time, i truly understood how they work. here’s everything you need to know about llms in 3 minutes↓


As promised, my SOP draft is here: algoroxyolo.github.io/assets/pdf/lrz… Please lmk if you have any suggestions or you have any recommendations where you think I should apply or what I should do in my future research. As always RT appreciated!! #PhDApplication #NLP #HCI

New lecture recordings on RL+LLM! 📺 This spring, I gave a lecture series titled **Reinforcement Learning of Large Language Models**. I have decided to re-record these lectures and share them on YouTube. (1/7)

Despite theoretically handling long contexts, existing recurrent models still fall short: they may fail to generalize past the training length. We show a simple and general fix which enables length generalization in up to 256k sequences, with no need to change the architectures!


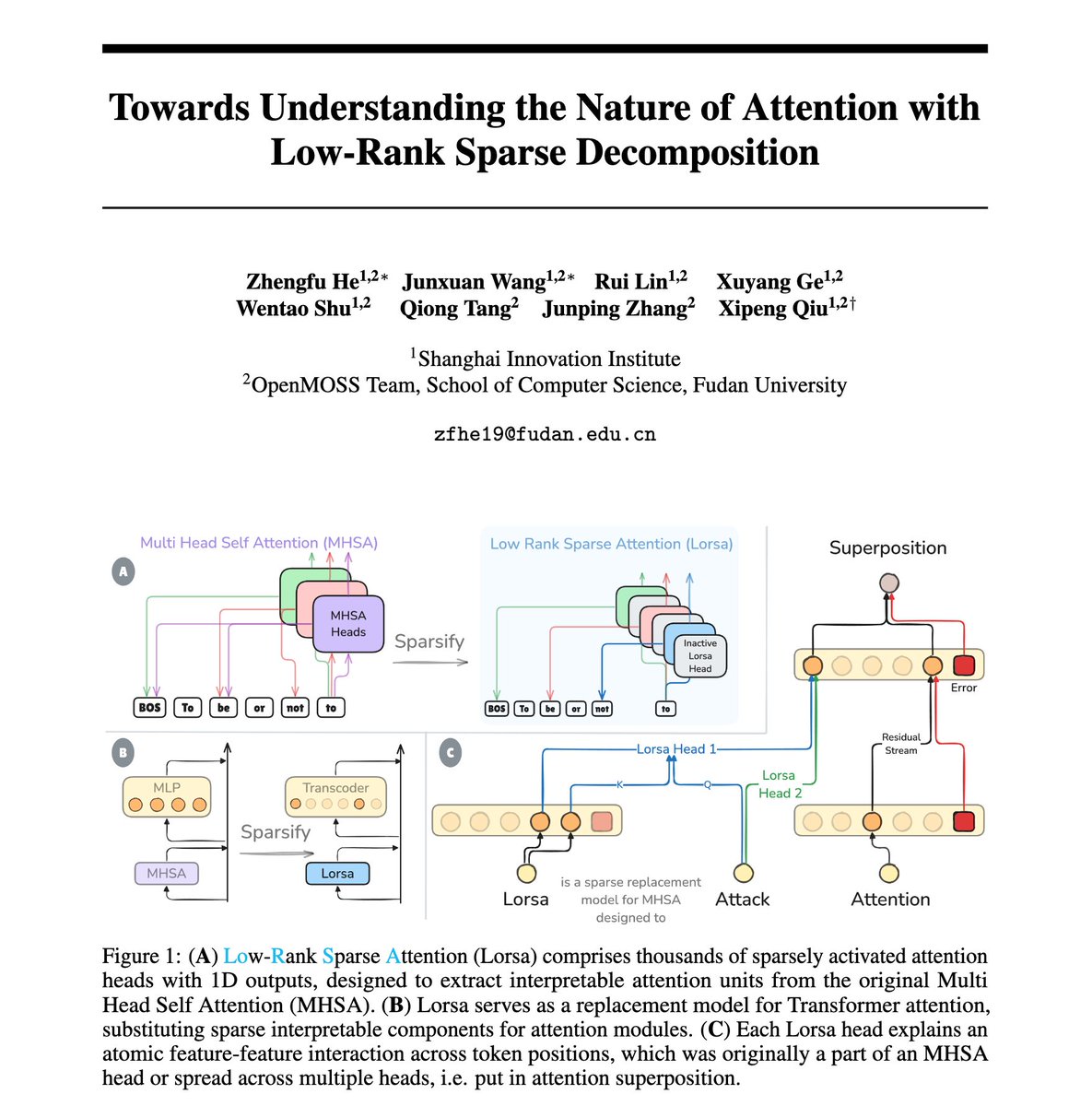
Are attention heads the right units to mechanistically understand Transformers' attention behavior? Probably not due the attention superposition! We extracted interpretable attention units in LMs and found finer grained versions of many known and novel attention behaviors. 🧵1/N



New paper - Transformers, but without normalization layers (1/n)


I've been reading this book alongside Deepseek. The math is mathing. The code is coding. The Deepseek is deepseeking! @deepseek_ai you made god!

Stanford “Statistics and Information Theory” lecture notes PDF: web.stanford.edu/class/stats311…



Excited to share a new project! 🎉🎉 doi.org/10.1101/2024.0… How do we navigate between brain states when we switch tasks? Are dynamics driven by control, or passive decay of the prev task? To answer, we compare high-dim linear dynamical systems fit to EEG and RNNs🌀 ⏬

Announcing MatMamba - an elastic Mamba2🐍architecture with🪆Matryoshka-style training and adaptive inference. Train a single elastic model, get 100s of nested submodels for free! Paper: sca.fo/mmpaper Code: sca.fo/mmcode 🧵(1/10)

A cool Github repo collecting LLM papers, blogs, and projects, with a focus on OpenAI o1 and reasoning techniques.


Excited to share a blog series I've been working on, diving deep into CUDA programming! Inspired by the #PMPP book & #CUDA_MODE!! Check out the links below...


[VAE] by Hand ✍️ A Variational Auto Encoder (VAE) learns the structure (mean and variance) of hidden features and generates new data from the learned structure. In contrast, GANs only learn to generate new data to fool a discriminator; they may not necessarily know the…

EVLM An Efficient Vision-Language Model for Visual Understanding In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the


















































United States Trends
- 1. Luka 60.5K posts
- 2. Clippers 17.6K posts
- 3. Lakers 46.9K posts
- 4. #DWTS 94.7K posts
- 5. Dunn 6,550 posts
- 6. #LakeShow 3,463 posts
- 7. Robert 135K posts
- 8. Kawhi 6,112 posts
- 9. Jaxson Hayes 2,371 posts
- 10. Reaves 11.5K posts
- 11. Ty Lue 1,541 posts
- 12. Collar 43.2K posts
- 13. Elaine 46.1K posts
- 14. Alix 15K posts
- 15. Jordan 116K posts
- 16. Zubac 2,278 posts
- 17. NORMANI 6,291 posts
- 18. Colorado State 2,409 posts
- 19. Godzilla 36.6K posts
- 20. Dylan 34.5K posts
Something went wrong.
Something went wrong.