





Haha! Good one.



ICLR 2026 will take place in 📍Rio de Janeiro, Brazil 📅 April 23–27, 2026 Save the date - see you in Rio! #ICLR2026


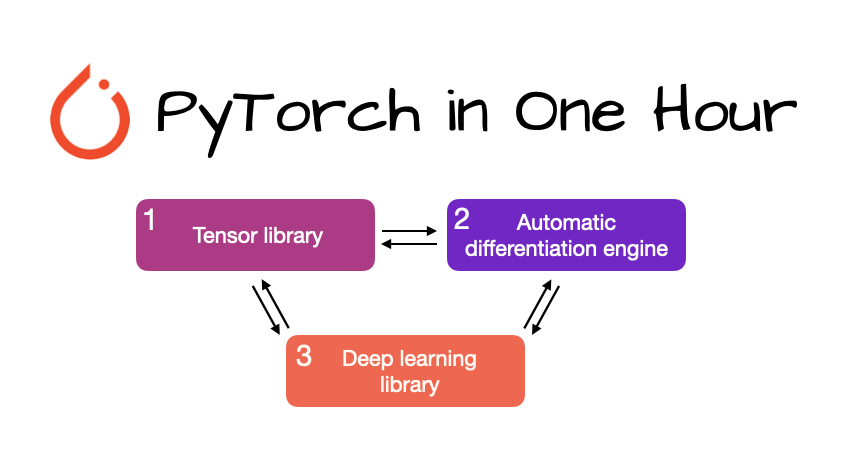
If you're getting into LLMs, PyTorch is essential. And lot of folks asked for beginner-friendly material, so I put this together: PyTorch in One Hour: From Tensors to Multi-GPU Training (sebastianraschka.com/teaching/pytor…) 📖 ~1h to read through 💡 Maybe the perfect weekend project!? I’ve…

Future of Work with AI Agents Stanford's new report analyzes what 1500 workers think about working with AI Agents. What types of AI Agents should we build? A few surprises! Let's take a closer look:

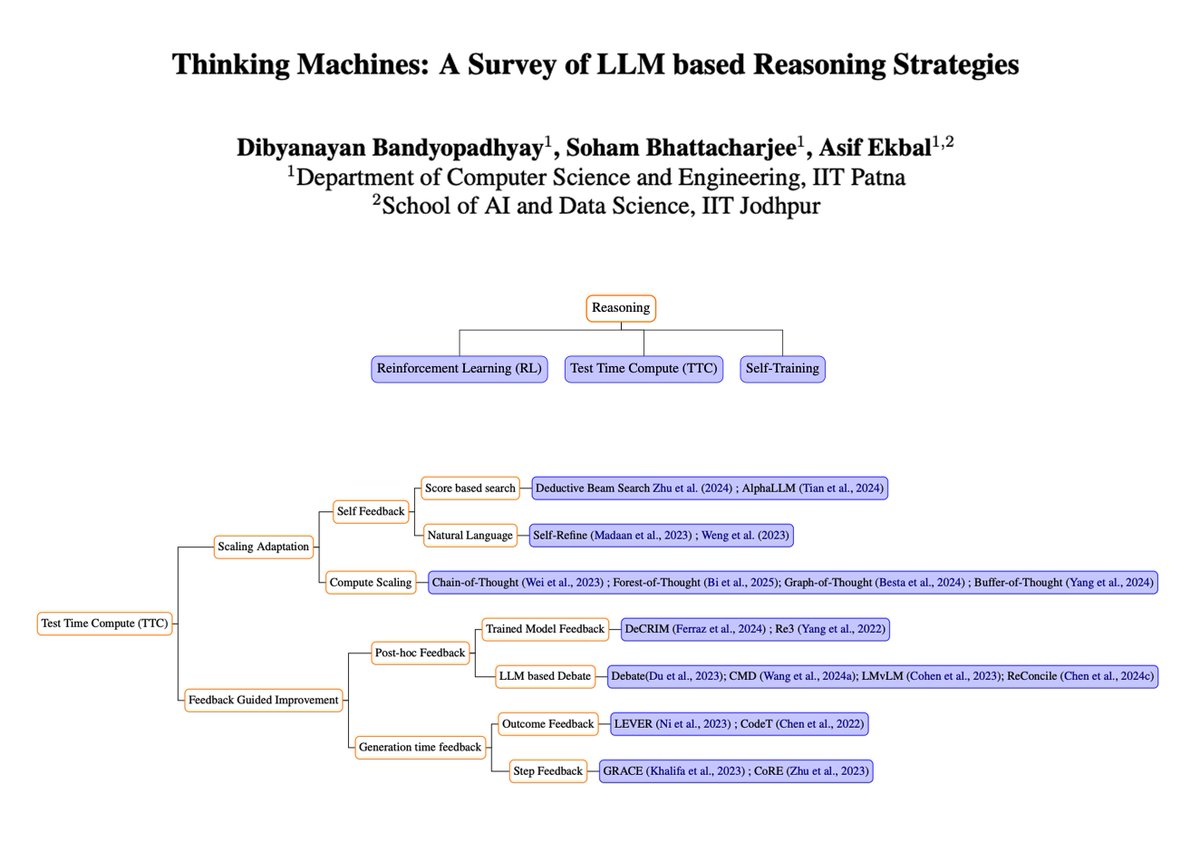
Thinking Machines: A Survey of LLM-based Reasoning Strategies Great survey to catch up on LLM-based reasoning strategies. It provides an overview and comparison of existing reasoning techniques and presents a systematic survey of reasoning-imbued language models.

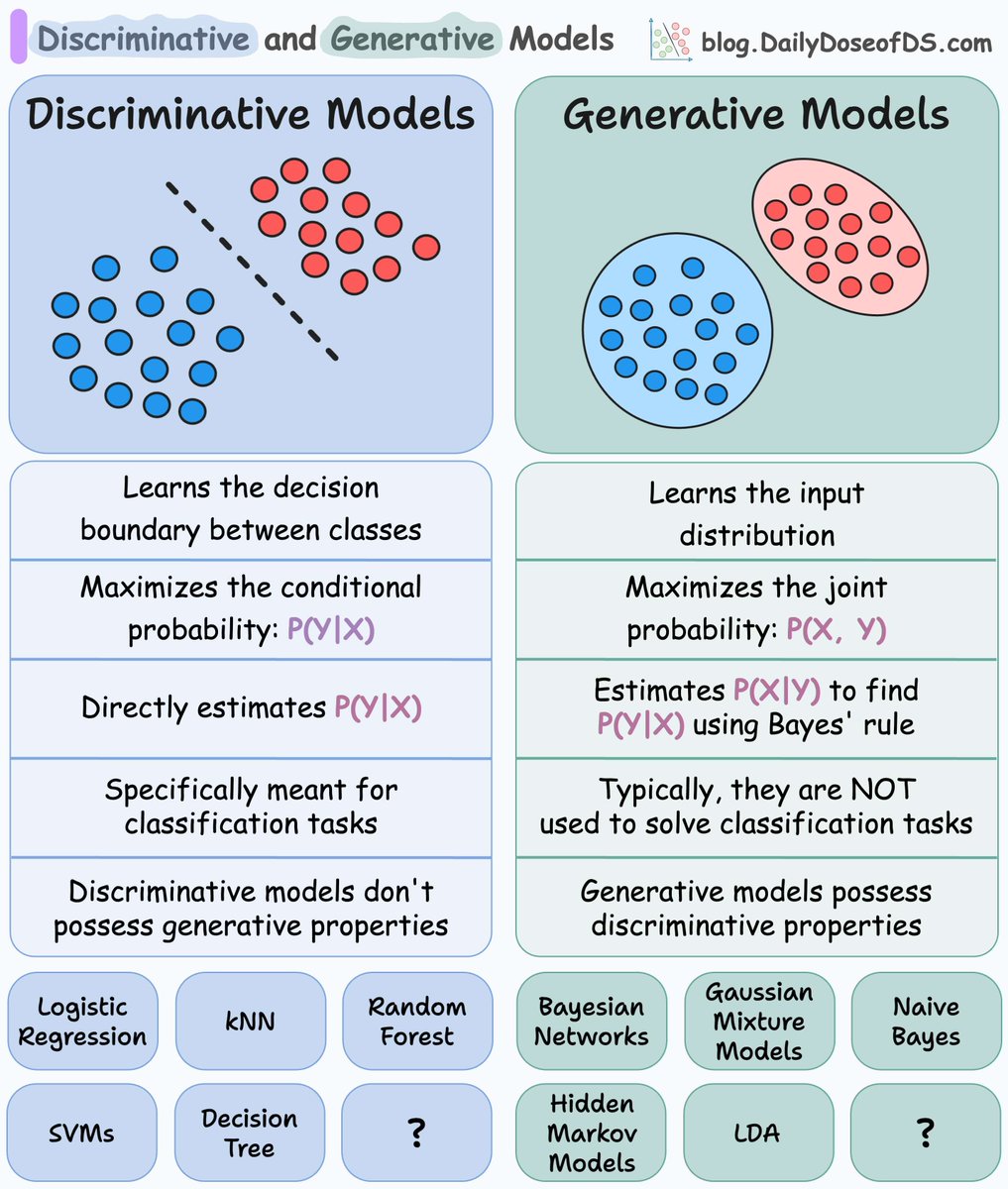
Generative vs. discriminative models in ML: Generative models: - learn the distribution so they can generate new samples. - possess discriminative properties—we can use them for classification. Discriminative models don't have generative properties.
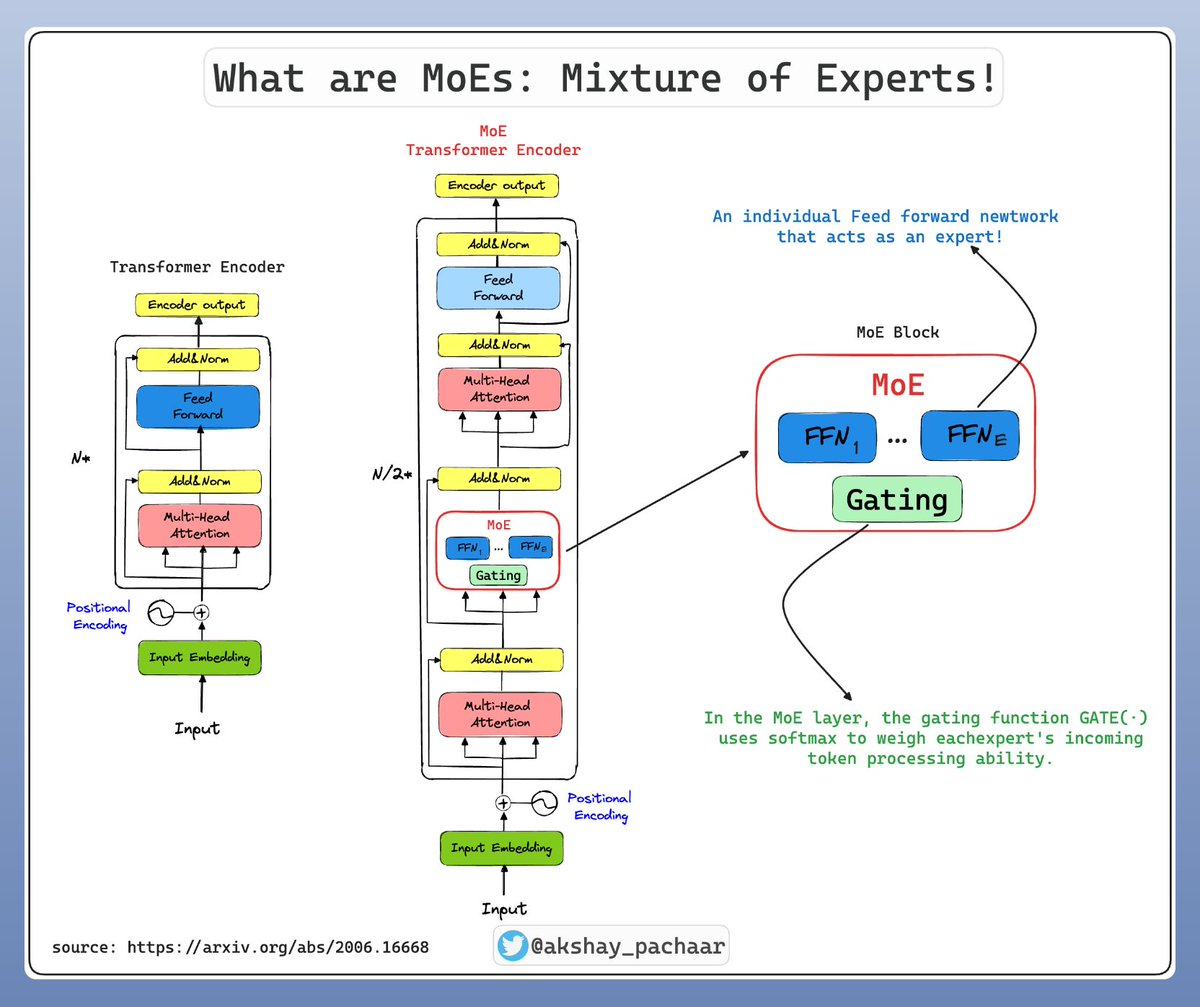
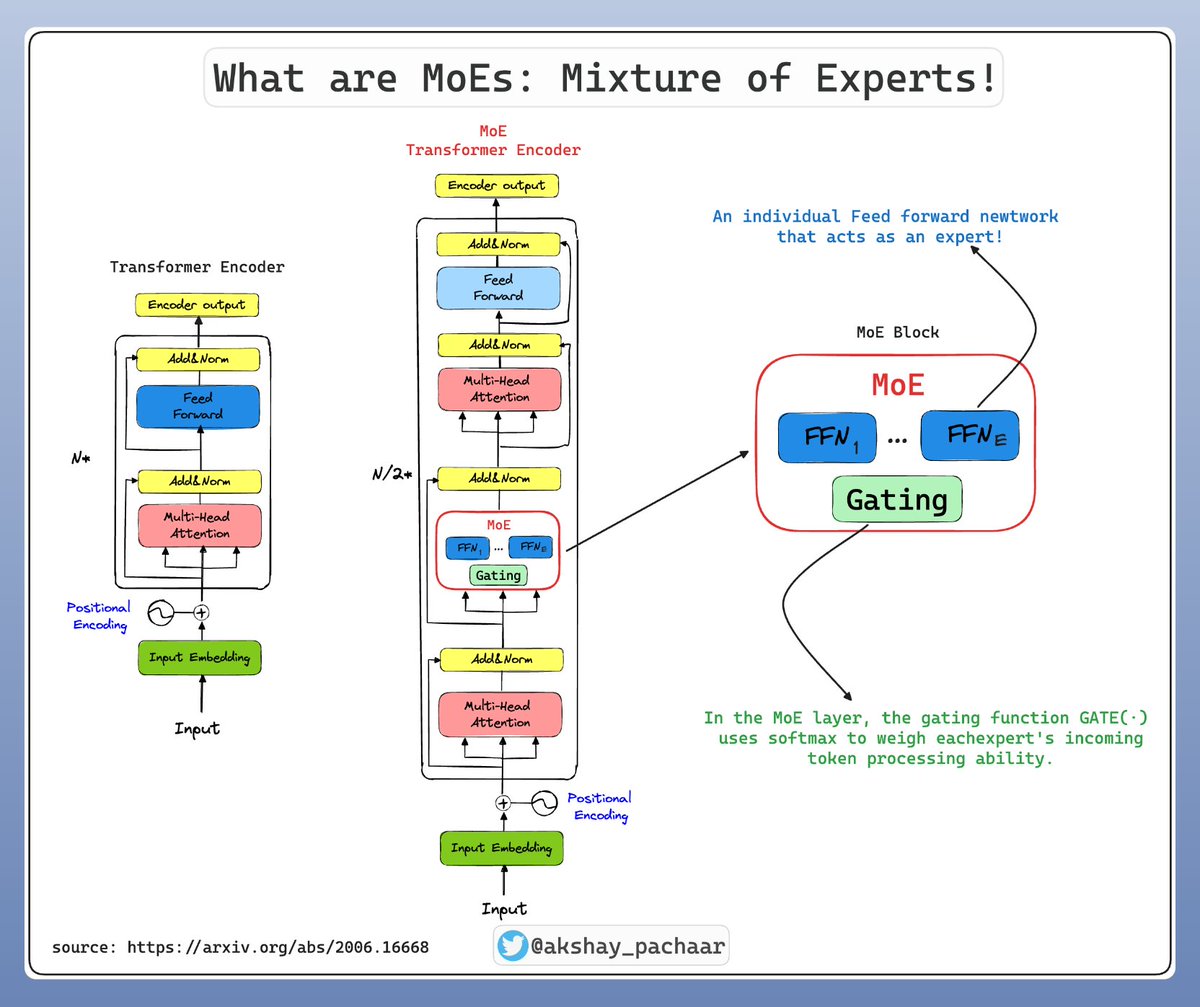
Transformer vs. Mixture of Experts in LLMs, clearly explained (with visuals):

MIT's "Matrix Calculus for Machine Learning" 🗒️Lecture Notes: ocw.mit.edu/courses/18-s09… 📽️Lecture Videos: youtube.com/playlist?list=…


Step-by-Step Diffusion: An Elementary Tutorial


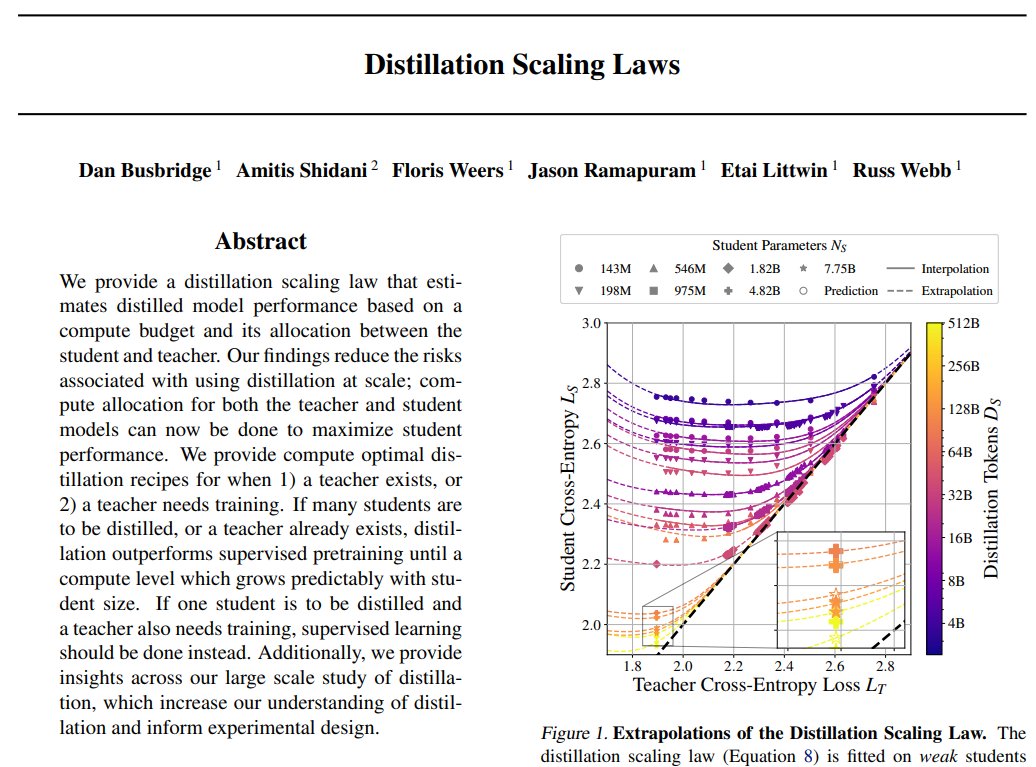
Apple presents: Distillation Scaling Laws Presents a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher

Like everyone, I've been a bit distracted exploring @deepseek_ai R1 and experimenting with it locally. I've spoken to a few people recently who don't know how to run local LLMs - this thread will cover a few different tools to get up and running easily.


DeepSeekV3, Gemini, Mixtral and many others are all Mixture of Experts (MoEs). But what exactly are MoEs? 🤔 A Mixture of Experts (MoE) is a machine learning framework that resembles a team of specialists, each adept at handling different aspects of a complex task. It's like…
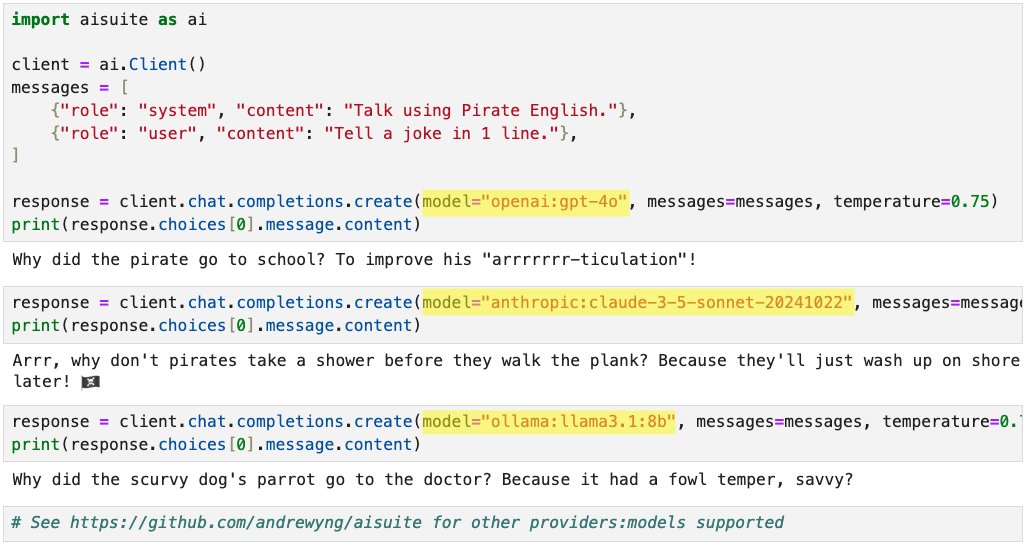
Announcing new open-source Python package: aisuite! This makes it easy for developers to use large language models from multiple providers. When building applications I found it a hassle to integrate with multiple providers. Aisuite lets you pick a "provider:model" just by…

Tora Trajectory-oriented Diffusion Transformer for Video Generation Recent advancements in Diffusion Transformer (DiT) have demonstrated remarkable proficiency in producing high-quality video content. Nonetheless, the potential of transformer-based diffusion models for

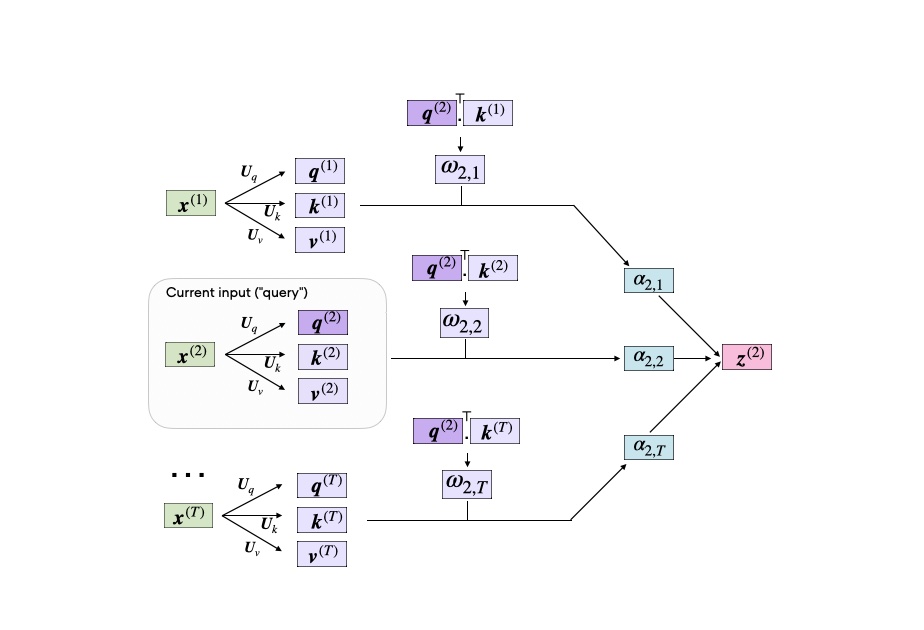
it's 1:28AM and I just finished this abomination. fully illustrated toy calculation of 1 transformer layer. why would I make this? idk ask my thesis advisor, "not everyone knows how a transformer works, you have to give an example"


I love this tutorial on the self-attention mechanism used in transformers. It shows how all matrices are computed, along with the matrix sizes and code to implement it. sebastianraschka.com/blog/2023/self…
What is a Mixture-of-Experts (MoE)? A Mixture of Experts (MoE) is a machine learning framework that resembles a team of specialists, each adept at handling different aspects of a complex task. It's like dividing a large problem into smaller, more manageable parts and assigning…

Is Cosine-Similarity of Embeddings Really About Similarity? Netflix cautions against blindly using cosine similarity as a measure of semantic similarity between learned embeddings, as it can yield arbitrary and meaningless results. 📝arxiv.org/abs/2403.05440


Here's my take on the Sora technical report, with a good dose of speculation that could be totally off. First of all, really appreciate the team for sharing helpful insights and design decisions – Sora is incredible and is set to transform the video generation community. What we…

We just finished a joint code release for CamP (camp-nerf.github.io) and Zip-NeRF (jonbarron.info/zipnerf/). As far as I know, this code is SOTA in terms of image quality (but not speed) among all the radiance field techniques out there. Have fun! github.com/jonbarron/camp…

























































































United States 趨勢
- 1. Sengun 8,104 posts
- 2. Mamdani 422K posts
- 3. #SmackDown 42.4K posts
- 4. Reed Sheppard 3,176 posts
- 5. Norvell 3,234 posts
- 6. Caleb Love N/A
- 7. Florida State 10.7K posts
- 8. Collin Gillespie 2,791 posts
- 9. Lando 33.1K posts
- 10. Rockets 16.1K posts
- 11. Marjorie Taylor Greene 58.8K posts
- 12. Suns 14.6K posts
- 13. #OPLive 2,477 posts
- 14. NC State 5,552 posts
- 15. Timberwolves 9,763 posts
- 16. #BostonBlue 3,767 posts
- 17. #LasVegasGP 59.2K posts
- 18. Booker 7,250 posts
- 19. Jabari 1,822 posts
- 20. Dillon Brooks 3,163 posts




Something went wrong.
Something went wrong.