
You might like






New paper by Nancy Lynch summarizing her career's influence on the field of distributed computing. arxiv.org/pdf/2502.20468 If you don't know who she is, she's the L in FLP and DLS. @MarcJBrooker has a good summary article: brooker.co.za/blog/2014/05/1…


Been working on a tiny LLM service to help me write prompts just like regular well-typed application code. Here's a sample use case - map freeform text to an address form:

For everyone interested in data infra, want to get a quick sense of how big data works, how data systems are designed, and what the tradeoffs are, start with this share from @MOVNTDQ, really nice intro! intro-data-system.xiangpeng.systems


Excited to announce a new side project, a power user terminal UI for your personal finances: moneyflow.dev For years I've used personal finance tools like Mint and now Monarch. The data cleaning can be slow and tedious, so I made this to speed that up!

@ApacheDataFusio 's policy for AI assisted contribution: AI is great, but not AI dumps: maintainers could finish the task faster by using AI directly, and the submitters gain little knowledge when acting as a pass through AI proxy. datafusion.apache.org/contributor-gu…

First one is: "Speedrunning the lakehouse" by Jacopo Tagliabue (CTO of Bauplan) He asks: What if we started from scratch? Building a lakehouse infrastructure from scratch. Hilarious, funny, and informative youtube.com/watch?v=dvBRC9…

youtube.com
YouTube
Speedrunning the Lakehouse

We use asserts all the time in Turso DB and also in the Turso Server. They're in release builds and shipped to production. And yes, they could crash the server. Asserts are my favorites, and I use them whenever possible. Just yesterday I merged a PR that contained asserts and…

New post -- A B+Tree Node Underflows: Merge or Borrow? jacobsherin.com/posts/2025-08-… An interesting engineering trade-off I stumbled upon implementing a concurrent B+Tree from scratch; where production databases diverge from textbook algorithms, and each does it their own way.
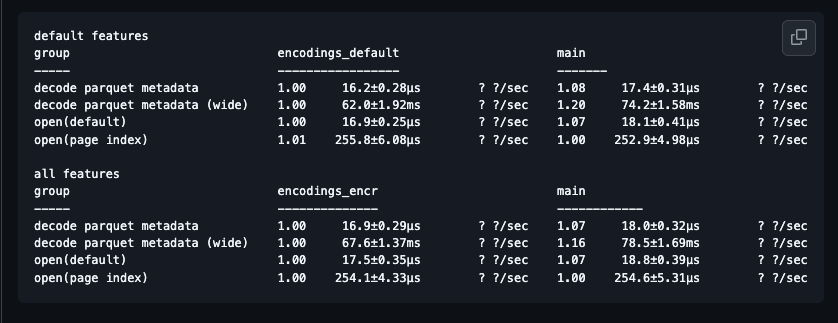
Our new thrift parser in the Rust @ApacheParquet implementation is a 🎁 that keeps on giving performance wise 🚀 github.com/apache/arrow-r… We are also working on a blog post that has a deeper explanation

So instead of working together, everyone (including us) released their own format: → @velox_lib Nimble: github.com/facebookincuba… → @cwi_da FastLanes: github.com/cwida/FastLanes → @SpiralDB Vortex: vortex.dev

The sordid backstory is that there was an collaboration attempt to unify on a single format with CMU, Tsinghua, Meta, CWI, Voltron, Nvidia, and SpiralDB. The plan was to create a consortium and start with Meta's Nimble. But then lawyers got involved and it all fell apart.
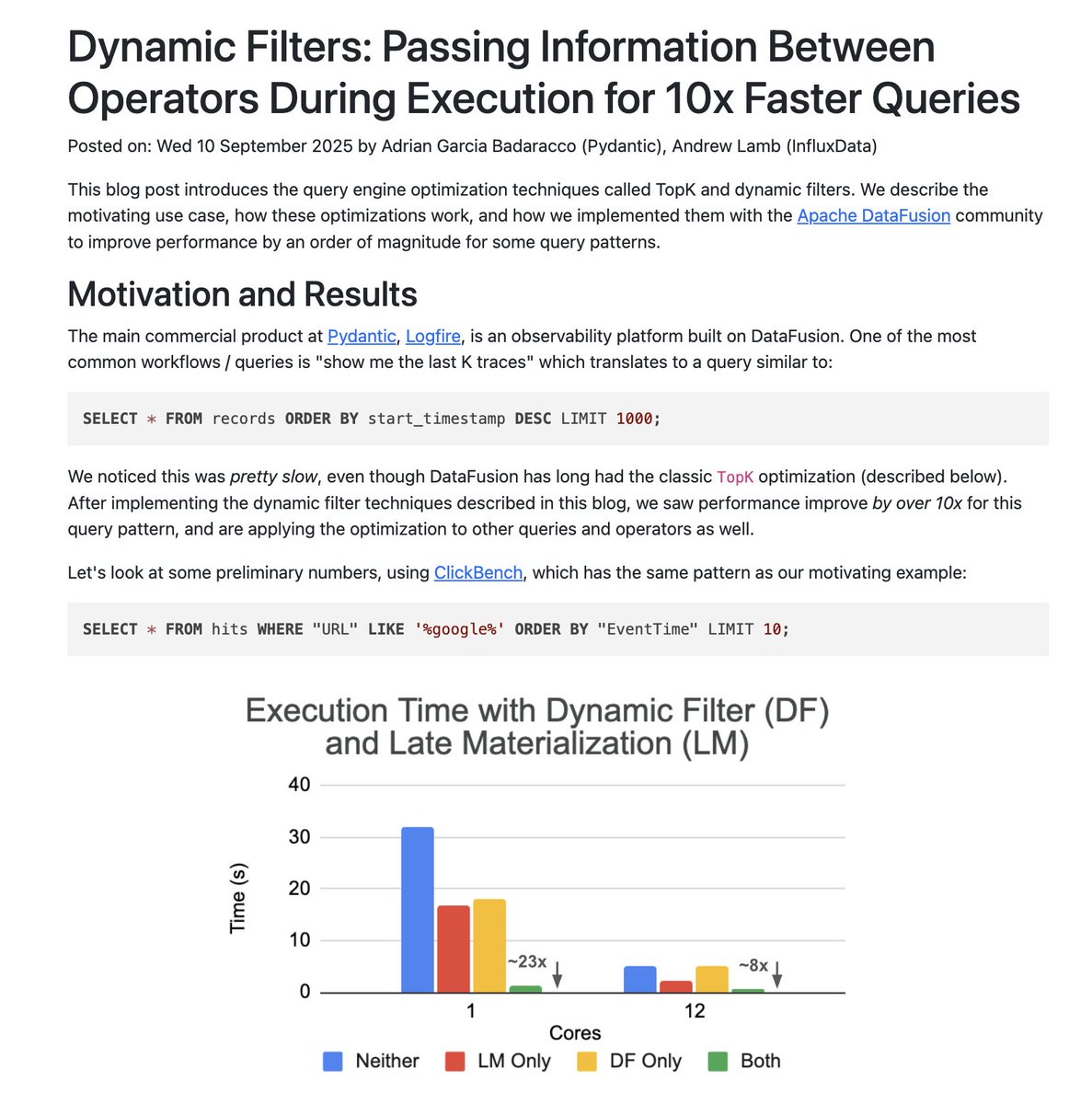
Dynamic Filters for TopK and Join queries landing in DataFusion 50.0.0: datafusion.apache.org/blog/2025/09/1…
People asked me about how OpenDAL makes money: the answer is it doesn’t. OpenDAL is for public goods, it helps you to access storage services and make money 🫡

Tobias Schmidt (TUM) at @VLDBconf presented SQLStorm, which uses LLMs to generate a huge amount of large queries. SQLStorm now has 18K different complex queries and runs on a large real-world dataset (stackoverflow) paper: vldb.org/pvldb/vol18/p4… code: github.com/SQL-Storm/SQLS…


Recording of "Introduction to Variant in @ApacheParquet ": youtube.com/watch?v=nlOJD7… Here are the slides: docs.google.com/presentation/d…


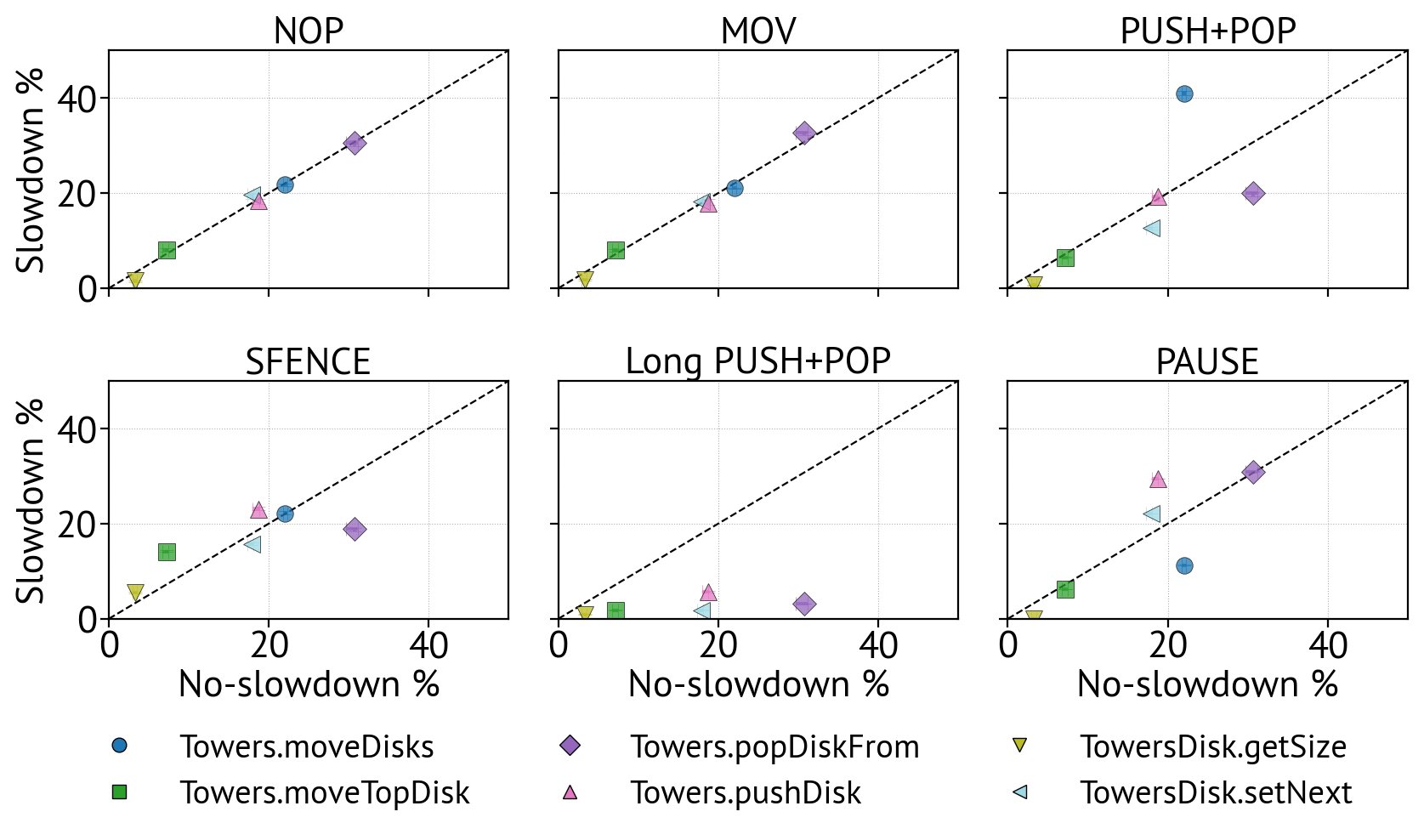
How can you slow down a program? And perhaps more importantly, why would you? Blog post on our upcoming @VMIL2025 paper. stefan-marr.de/2025/08/how-to… The research was led by @Humphrey_HCB.

One improvement regarding benchmaxxing is having thousands of diverse benchmark queries instead of dozens. Plugging the new SQLStorm paper below ;)

Mutli-level merge sort queued up for DataFusion 50.0.0 next month: github.com/apache/datafus… Thanks to @rluvaton and Yongting You

I'm excited to share that our paper (in collaboration with @peterabcz ) has been accepted at VLDB 2025 in London and will be presented there: The FastLanes File Format In this paper, we introduce the FastLanes file format with Expression Encoding—a new way to define and combine…

It is a common misconception that @ApacheParquet files are restricted to basic statistics. Footer metadata and offset-based addressing permit user-defined index structures today. Latest @ApacheDataFusio blog from Qi Zhi, Jigao Luo and myself explains how datafusion.apache.org/blog/2025/07/1…
























































































United States Trends
- 1. #StrangerThings5 266K posts
- 2. Thanksgiving 692K posts
- 3. BYERS 61.6K posts
- 4. robin 96.8K posts
- 5. Afghan 299K posts
- 6. Reed Sheppard 6,321 posts
- 7. holly 66.6K posts
- 8. Dustin 89.5K posts
- 9. Podz 4,811 posts
- 10. Vecna 62.4K posts
- 11. Jonathan 76.1K posts
- 12. hopper 16.5K posts
- 13. Erica 18.3K posts
- 14. Lucas 84.5K posts
- 15. National Guard 674K posts
- 16. noah schnapp 9,141 posts
- 17. derek 20.1K posts
- 18. Nancy 69.5K posts
- 19. Joyce 33.5K posts
- 20. mike wheeler 9,804 posts




Something went wrong.
Something went wrong.