
Jinghuan Shang
@jsfiredrice
Research Scientist @ The AI Institute. Making better brains for robots. #Robotics.
You might like












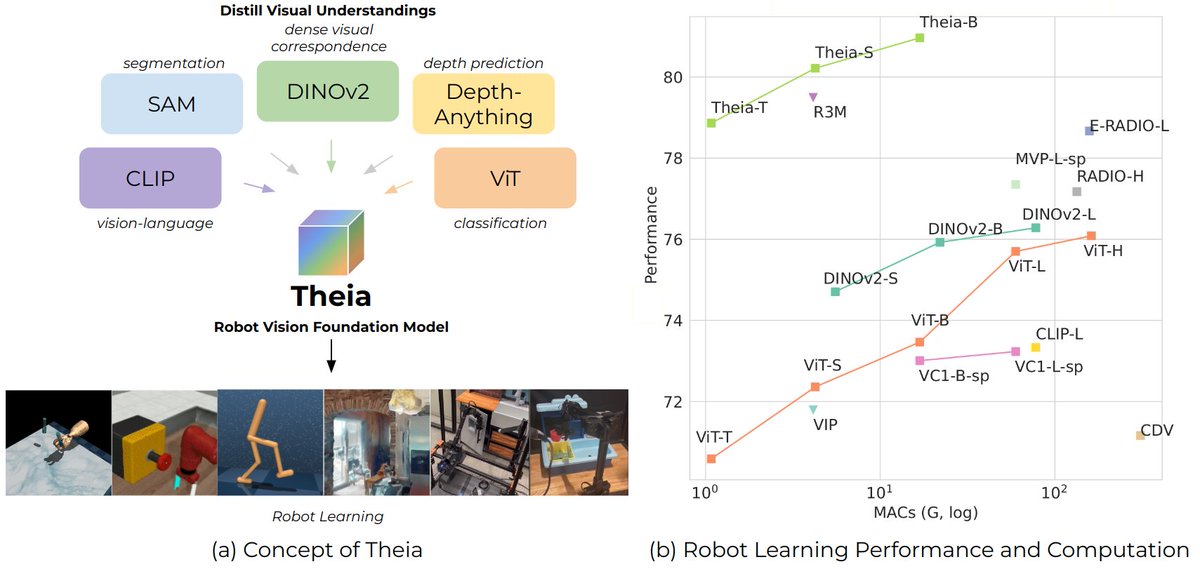
#CoRL2024 accepted!! Theia: Distilling Diverse Vision Foundation Models for Robot Learning. Theia is smaller but more powerful than off-the-shelf vision models in robotic tasks, and can generate features of SAM and DINOv2! Code, demo: theia.theaiinstitute.com Thank my co-authors!

Loving the energy @corl_conf 2025 Largest CoRL ever with more than 2400 in-person participants!





#CoRL2025 Sponsor exhibitions corl.org/program/exhibi… We are immensely grateful to our sponsors for being the driving force behind #CoRL2025.


✈Two days to go for #CoRL2025! Some tips for the participants: Venue information: corl.org/attending/venu… Local tips: corl.org/attending/loca… Map for main program: corl.org/program/main-c… Map for workshop: corl.org/program/worksh… Registration kiosk opens at 7AM. Safe trip!
🎤Free K-Pop Concert Tickets for #CoRL2025 Attendees! Yeongdong-daero K-POP Concert will be right next to our venue on Sep 27, from 7-9 PM. We have 300 complimentary tickets available at the registration desk starting at 12PM Sep 27, on a first-come, first-served basis.

Reinforcement learning is used to speed the production of behavior for the @BostonDynamics Atlas humanoid robot. At the heart of the learning process is a physics-based simulator that generates training data for a variety of maneuvers.

Unitree H1: Humanoid Robot Makes Its Debut at the Spring Festival Gala 🥰 Hello everyone, let me introduce myself again. I am Unitree H1 "Fuxi". I am now a comedian at the Spring Festival Gala, hoping to bring joy to everyone. Let’s push boundaries every day and shape the future…
Introducing Theia, a vision foundation model for robotics developed by our team at the Institute. By using off-the-shelf vision foundation models as a basis, Theia generates rich visual representations for robot policy learning at a lower computation cost. theaiinstitute.com/news/theia

I am extremely pleased to announce that CoRL 2025 will be in Seoul, Korea! The organizing team includes myself and @gupta_abhinav_ as general chairs, and @JosephLim_AI, @songshuran, and Hae-Won Park (KAIST) as program chairs.

Our team is presenting work at the Conference on Robot Learning, @corl_conf, in Munich, Germany this week! Learn more about our accepted research — theaiinstitute.com/news/corl-roun…

Our team has arrived in Munich and we're thrilled to present this work at the LangRob Workshop @ #CoRL2024 as a spotlight presentation on Nov. 9 morning. Stay tuned!
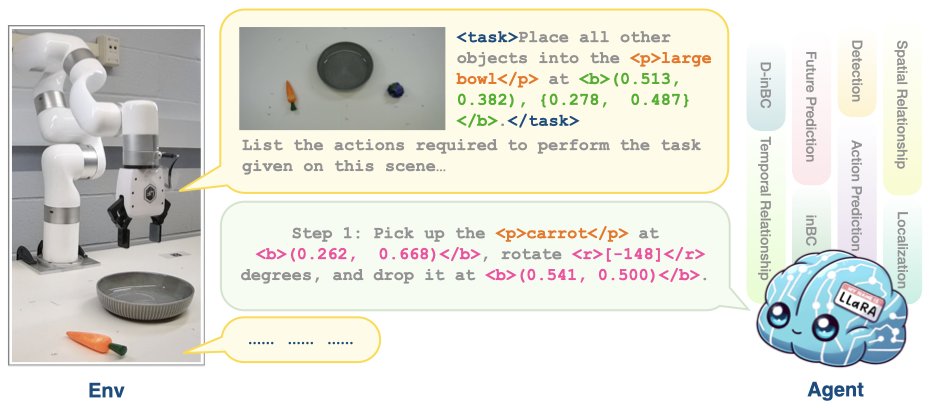
🚀 Excited to share our latest project: LLaRA - Supercharging Robot Learning Data for Vision-Language Policy! 🤖✨ We create a framework to turn robot expert trajectories into conversation-style data and other auxiliary data for instruction tuning. More details to come! (1/N)


Introducing AdaCache, a training-free inference accleration method for video DiTs. It allocates compute tailored to each video generation, maximizing quality-latency trade-off. project-page: adacache-dit.github.io code: github.com/AdaCache-DiT/A… arxiv: arxiv.org/pdf/2411.02397
#CoRL2024 accepted!! Theia: Distilling Diverse Vision Foundation Models for Robot Learning. Theia is smaller but more powerful than off-the-shelf vision models in robotic tasks, and can generate features of SAM and DINOv2! Code, demo: theia.theaiinstitute.com Thank my co-authors!

We will present our #COLM2024 paper, Does RoBERTa Perform Better than BERT in Continual Learning: An Attention Sink Perspective, on Monday 11:00 AM – 1:00 PM at #20 Poster Area. Please stop by if you are interested! Paper: openreview.net/pdf?id=VHhwhmt… Code: github.com/StonyBrookNLP/…


Atlas doing a quick warm up before work.
Want to know visual instruction tuning for robotics? 🤖Check our latest work -- LLaRA
🚀 Excited to share our latest project: LLaRA - Supercharging Robot Learning Data for Vision-Language Policy! 🤖✨ We create a framework to turn robot expert trajectories into conversation-style data and other auxiliary data for instruction tuning. More details to come! (1/N)
#NeurIPS2023 🔔 Wondering an agent can learn how to see 👀 to help act 🦾? Come to see our #ActiveVision #RL with great potential! Time: Thursday, Dec 14 10:45 - 12:45 CST Venue: Great Hall & Hall B1+B2 (level 1) #1501 Everything: elicassion.github.io/sugarl/sugarl.…

What if you had four innocent-looking images, that when combined made a new secret image? Or two images, that when rotated at different angles, produce entirely different scenes? We use diffusion models to do this, with physical images! Read the thread for more details!





















































































United States Trends
- 1. Luka 58.1K posts
- 2. Lakers 44.8K posts
- 3. Clippers 17K posts
- 4. #DWTS 93.5K posts
- 5. #LakeShow 3,397 posts
- 6. Kris Dunn 2,372 posts
- 7. Robert 133K posts
- 8. Kawhi 5,902 posts
- 9. Reaves 10.5K posts
- 10. Jaxson Hayes 2,245 posts
- 11. Ty Lue 1,486 posts
- 12. Alix 15K posts
- 13. Elaine 45.9K posts
- 14. Jordan 117K posts
- 15. Collar 41.2K posts
- 16. Zubac 2,250 posts
- 17. Dylan 34.7K posts
- 18. NORMANI 6,106 posts
- 19. Colorado State 2,360 posts
- 20. Godzilla 36.6K posts
You might like
-
 Xiang Li
Xiang Li
@XiangLi54505720 -
 Hamid Rezatofighi
Hamid Rezatofighi
@HamidRezatofigh -
 Kanchana Ranasinghe
Kanchana Ranasinghe
@kahnchana -
 Saumya Gupta
Saumya Gupta
@SaumyaGupta26 -
 Avinab Saha 🇮🇳
Avinab Saha 🇮🇳
@avinab_saha -
 yifan
yifan
@yifan0sun -
 Srikar Yellapragada
Srikar Yellapragada
@ymsrikar -
 Hyunggi Chang
Hyunggi Chang
@changh95 -
 Amir Habibian
Amir Habibian
@amir_habibian -
 ShahRukh Athar
ShahRukh Athar
@shahrukh_athar -
 Abhinav Shukla
Abhinav Shukla
@Abhinav95_ -
 Sauradip Nag
Sauradip Nag
@Dumb_Thug
Something went wrong.
Something went wrong.