

We (@lawrence_cjs, @yuyangzhao_ , @shanasaimoe) from the SANA team just posted a blog on the core of Linear Attention: how it achieves infinite context lengths with global awareness but constant memory usage! We explore state accumulation mechanics, the evolution from Softmax to…
The training/ Inference code and checkpoints are released. Welcome to try! github.com/NVlabs/Sana
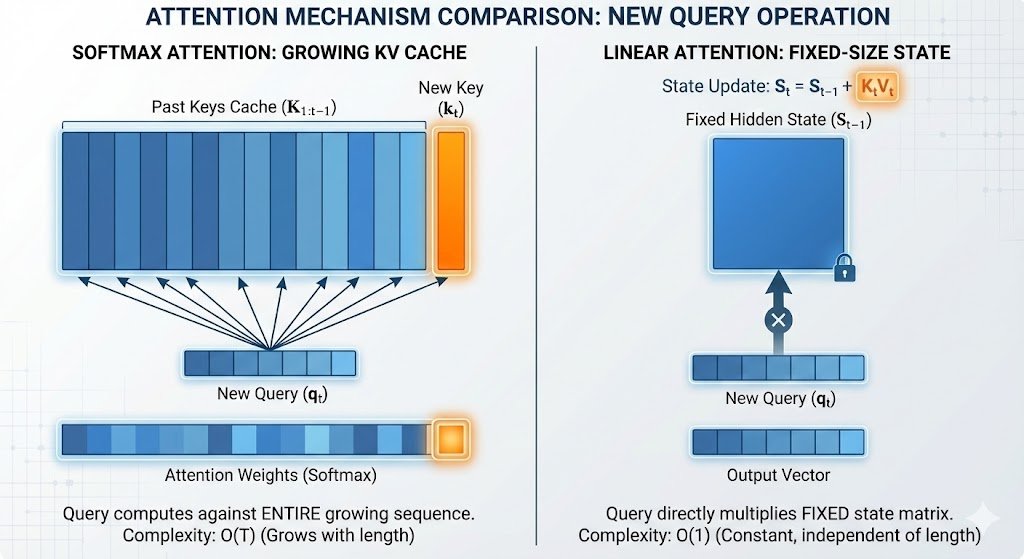
How Linear Attention and Softmax Attention differ in compute and KV-Cache for LLMs and long-video generation. Let's start with this blog. hanlab.mit.edu/blog/infinite-…

We (@lawrence_cjs, @yuyangzhao_ , @shanasaimoe) from the SANA team just posted a blog on the core of Linear Attention: how it achieves infinite context lengths with global awareness but constant memory usage! We explore state accumulation mechanics, the evolution from Softmax to…
Sora 2 is amazing!, But AI video generation inference speed is too slow. Try our Deep Compression Autoencoder + Linear Attention! 🚀🔥 nvlabs.github.io/Sana/Video github.com/dc-ai-projects…
github.com
GitHub - dc-ai-projects/DC-VideoGen: DC-VideoGen: Efficient Video Generation with Deep Compression...
DC-VideoGen: Efficient Video Generation with Deep Compression Video Autoencoder - dc-ai-projects/DC-VideoGen
🚀 SANA-Video: Linear Attention + Constant-Memory KV Cache = Fast Long Videos 💥 Key Features 🌟 🧠 Linear DiT everywhere → O(N) complexity on video-scale tokens 🧰 Constant-memory Block KV cache → store cumulative states only (no growing KV) 🔄 🎯 Temporal Mix-FFN + 3D RoPE…
Thanks so much @_akhaliq for sharing our recent work. Our homepage is here: nvlabs.github.io/Sana/Video/


Changing the autoencoder in latent diffusion models is easier than you think. 🚀 Introducing DC-Gen – a post-training acceleration framework that works with any pre-trained diffusion model, boosting efficiency by transferring it into a deeply compressed latent space with…


We release DC-VideoGen, a new post-training framework for accelerating video diffusion models. Key features: 🎬 Supports video generation up to 2160×3840 (4K) resolution on a single H100 GPU ⚡ Delivers 14.8× faster inference than the base model while achieving comparable or…

🚀 SANA-Video: Linear Attention + Constant-Memory KV Cache = Fast Long Videos 💥 Key Features 🌟 🧠 Linear DiT everywhere → O(N) complexity on video-scale tokens 🧰 Constant-memory Block KV cache → store cumulative states only (no growing KV) 🔄 🎯 Temporal Mix-FFN + 3D RoPE…
Explore recent work from our team. Long-Live generates minute-length videos and interacts as you want with real-time fast speed! Very cool project. 🎉

🚀 We open-sourced LongLive — interactive, real-time long-video generation. 👥Generates video in real time as users enter text prompts. ⚡️20.7 FPS on a single H100,⏱️up to 240s per clip. 🎬Fine-tunes SOTA short-video models (e.g., Wan) into long-video generators. 🌍One step…

Explore Deep Compression Autoencoder (DC-AE) 1.5 with higher token compression ratio (64x) for faster visual generation:
🚀 Excited to announce DC-AE 1.5! With a spatial compression ratio boosted to f64, it accelerates high-res diffusion models while preserving text-to-image quality. Key innovation: channel-wise latent structure for faster convergence with many latent channels. 📍 Catch us at…



The best few-step sampling model across the speed-memory frontier? 😱 Introducing SANA-Sprint in collaboration with the great SANA team! Beyond the results, perhaps more importantly, the work is about the recipe of SANA-Sprint. Code & model will be open ❤️ Let's go ⬇️
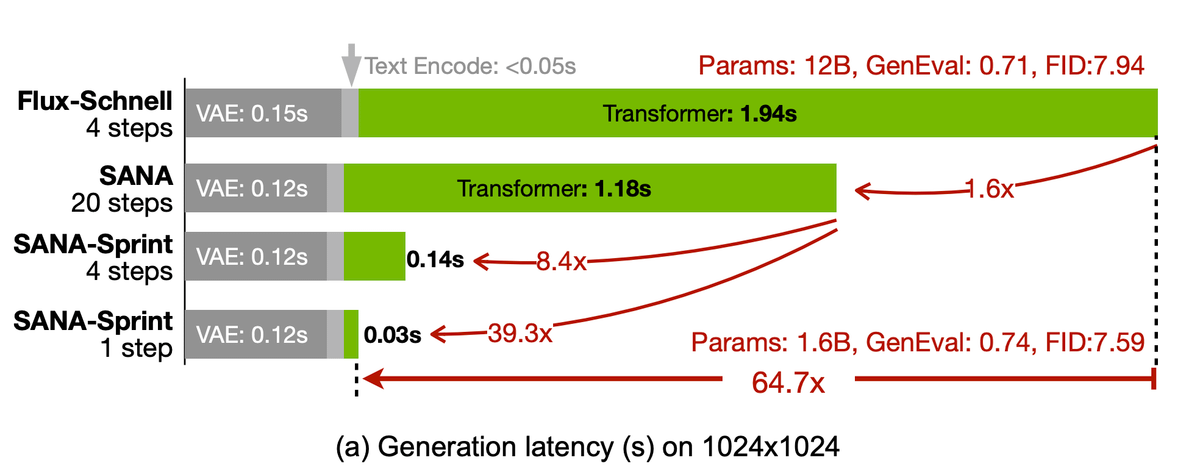
SANA-Sprint One-Step Diffusion with Continuous-Time Consistency Distillation
Explore our one-step diffusion model, SANA-Sprint. Very fast:

Still think consistency models are bad at scale? In fact, sCM can be stably scaled to modern text-to-image diffusion models and greatly improve the generation speed and 1-step generation quality!
Excited for 🏃SANA-Sprint. 🚀Code and weights will be released very soon along with diffusers. Study tuned!❤️
Introducing Sana-1.5. Model scaling up, then scaling down. Also inference time scaling is working as an auto end to end pipeline.
🔥 SANA 1.5: A linear Diffusion Transformer pushes SOTA in text-to-image generation! Key innovations: • Depth-growth training: 1.6B → 4.8B params • Memory-efficient 8-bit optimizer • Flexible model pruning • Inference scaling for better quality Achieves 0.80 on GenEval! 🚀










































































United States Trends
- 1. Thanksgiving 358K posts
- 2. Fani Willis 7,364 posts
- 3. Trumplican 2,241 posts
- 4. Golesh 1,346 posts
- 5. Hong Kong 71.3K posts
- 6. Elijah Moore N/A
- 7. Ruth 13.5K posts
- 8. #Wednesdayvibe 3,306 posts
- 9. #wednesdaymotivation 6,274 posts
- 10. Stranger Things 151K posts
- 11. Karoline Leavitt 26.9K posts
- 12. Nuns 9,756 posts
- 13. Mora 22.2K posts
- 14. Gretzky N/A
- 15. Khabib 5,175 posts
- 16. Good Wednesday 35K posts
- 17. Ribs 11.2K posts
- 18. #WednesdayWisdom 1,079 posts
- 19. Fulton County 1,950 posts
- 20. #BurnoutSyndromeSeriesEP1 265K posts
Something went wrong.
Something went wrong.