
Mechanical Dirk
@mechanicaldirk
Principal Engineer at @allen_ai. Engineering Lead of the OLMo project.
Talvez você curta















Love you too Cody 😃

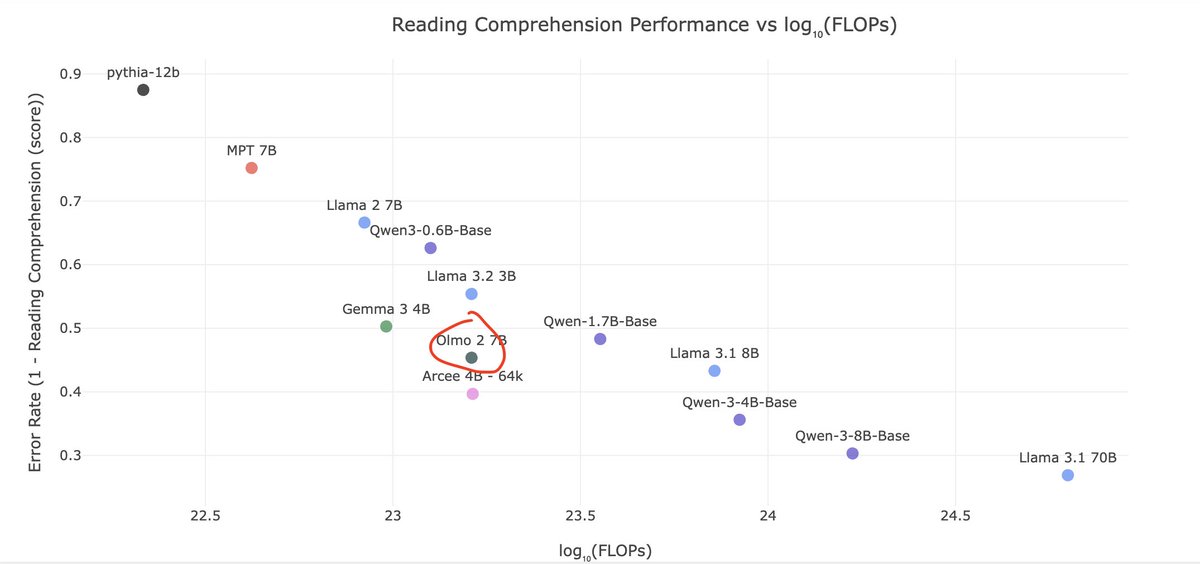
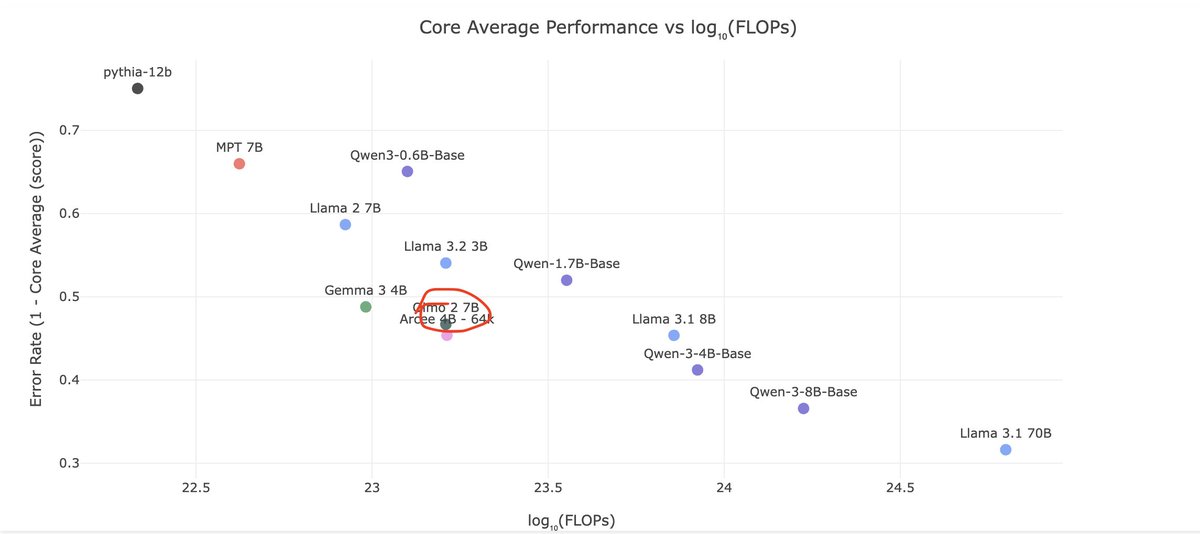
People sleep on OLMo 2, but its one of the best trained OSS models per train flop out there. The @allen_ai data team is cracked AF.

The goal of AI coding tools doesn't need to be to write the code for me. That part is easy. AI needs to save me from having to look up documentation every two lines.

thx to all the feedback from OSS community! our olmOCR lead @jakepoznanski shipped a new model fixing lotta issues + some more optimization for better throughput have fun converting PDFs!

📝 olmOCR v0.2.1 has arrived with new models! Our open‑source OCR engine now reads tougher docs with greater precision—and it’s still 100 % open. 👇

Are we just alternating conferences between Vancouver and Vienna now? Because honestly, I'm down.
I’ll be in Vienna for ACL next week! Email and DMs open: 1. Always excited to talk about FLaNN theory and pre-pretraining on formal languages 2. Open pretraining (eg OLMo) 3. advice for junior faculty 4. I’m recruiting PhD students this fall

6m later "Nobel Prize is actually a poor measure of intelligence. In this paper we show that ..."

Product idea: Notion except every keystroke doesn't feel like I'm SSH'd into a server on Mars.

Our new ICML 2025 oral paper proposes a new unified theory of both Double Descent and Grokking, revealing that both of these deep learning phenomena can be understood as being caused by prime numbers in the network parameters 🤯🤯 🧵[1/8]
![Jeffaresalan's tweet image. Our new ICML 2025 oral paper proposes a new unified theory of both Double Descent and Grokking, revealing that both of these deep learning phenomena can be understood as being caused by prime numbers in the network parameters 🤯🤯
🧵[1/8]](https://pbs.twimg.com/media/GvgH5aYXcAA-nim.jpg)

The bottleneck in AI isn't just compute - it's access to diverse, high-quality data, much of which is locked away due to privacy, legal, or competitive concerns. What if there was a way to train better models collaboratively, without actually sharing your data? Introducing…

Introducing FlexOlmo, a new paradigm for language model training that enables the co-development of AI through data collaboration. 🧵

🚨 Just announced: OLMo, Molmo & Tülu are now LIVE on the Cirrascale Inference Platform! It’s official, Cirrascale is the first to offer commercial inference endpoints for @Ai2’s OLMo, Molmo & Tülu models on our Inference Platform. Our Inference Platform provides a fully open,…


My latest post: The American DeepSeek Project Build fully open models in the US in the next two years to enable a flourishing, global scientific AI ecosystem to balance China's surge in open-source and an alternative to building products ontop of leading closed models.

This project is a perfect model of an OLMo contribution. Well scoped, practical, sound theoretical underpinnings, and @lambdaviking submitted the paper 24h before the deadline 😍. Integrated into the code here: github.com/allenai/OLMo-c…
As we’ve been working towards training a new version of OLMo, we wanted to improve our methods for measuring the Critical Batch Size (CBS) of a training run, to unlock greater efficiency, but we found gaps between the methods in the literature and our practical needs for training…

The #1 question we get is, when will we have an OLMo 1B? We finally do!
We're excited to round out the OLMo 2 family with its smallest member, OLMo 2 1B, surpassing peer models like Gemma 3 1B or Llama 3.2 1B. The 1B model should enable rapid iteration for researchers, more local development, and a more complete picture of how our recipe scales.


In Singapore @iclr_conf - feel free to come by our OLMoE Oral! Meta recently switched from Dense to MoEs for Llama 4 but hasn't released many details on this yet --- We'll explore MoEs vs Dense & other MoE insights!


🔭 Science relies on shared artifacts collected for the common good. 🛰 So we asked: what's missing in open language modeling? 🪐 DataDecide 🌌 charts the cosmos of pretraining—across scales and corpora—at a resolution beyond any public suite of models that has come before.
Ever wonder how LLM developers choose their pretraining data? It’s not guesswork— all AI labs create small-scale models as experiments, but the models and their data are rarely shared. DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵


Reinforcement learning has shown success in eliciting reflection from LLMs, but what if this capability actually manifests earlier in pre-training? We investigated this question and our results are surprising 👇 [1/4]
![ashVaswani's tweet image. Reinforcement learning has shown success in eliciting reflection from LLMs, but what if this capability actually manifests earlier in pre-training? We investigated this question and our results are surprising 👇
[1/4]](https://pbs.twimg.com/media/GoBpzxAasAAv9A8.jpg)

Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data. We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting? Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦

From ‘black box to glass box’: Ai2 (@allen_ai) links AI outputs to training data in breakthrough for transparency geekwire.com/2025/from-blac… via @GeekWire

Biggest one yet! Scroll to the bottom of the blog post (allenai.org/blog/olmo2-32B) for a few fun training stories.

Announcing OLMo 2 32B: the first fully open model to beat GPT 3.5 & GPT-4o mini on a suite of popular, multi-skill benchmarks. Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!


people are talking about whether scaling laws are broken or pretraining is saturating. so what does that even mean? consider the loss curves from our recent gemstones paper. as we add larger models, the convex hull doesn’t flatten out on this log-log plot. that's good!

Introducing olmOCR, our open-source tool to extract clean plain text from PDFs! Built for scale, olmOCR handles many document types with high throughput. Run it on your own GPU for free—at over 3000 token/s, equivalent to $190 per million pages, or 1/32 the cost of GPT-4o!

























































































United States Tendências
- 1. Good Sunday 54K posts
- 2. #sundayvibes 4,763 posts
- 3. #AskBetr N/A
- 4. Muhammad Qasim 8,841 posts
- 5. Discussing Web3 N/A
- 6. Wordle 1,576 X N/A
- 7. #HealingFromMozambique 20.5K posts
- 8. Miary Zo 1,234 posts
- 9. Trump's FBI 12.2K posts
- 10. KenPom N/A
- 11. Biden FBI 18.9K posts
- 12. Blessed Sunday 17.7K posts
- 13. Coco 48.7K posts
- 14. #ChicagoMarathon N/A
- 15. Mason Taylor N/A
- 16. The CDC 33K posts
- 17. Lord's Day 1,688 posts
- 18. Gilligan 7,205 posts
- 19. Macrohard 9,799 posts
- 20. Go Broncos 1,327 posts
Talvez você curta
-
 Saadia Gabriel
Saadia Gabriel
@GabrielSaadia -
 Zhaofeng Wu
Zhaofeng Wu
@zhaofeng_wu -
 Maarten Sap (he/him)
Maarten Sap (he/him)
@MaartenSap -
 Jesse Dodge
Jesse Dodge
@JesseDodge -
 Ana Marasović
Ana Marasović
@anmarasovic -
 Machel Reid
Machel Reid
@machelreid -
 Roy Schwartz
Roy Schwartz
@royschwartzNLP -
 Swabha Swayamdipta
Swabha Swayamdipta
@swabhz -
 Sarah Wiegreffe
Sarah Wiegreffe
@sarahwiegreffe -
 Hamish Ivison @ COLM 🍁
Hamish Ivison @ COLM 🍁
@hamishivi -
 Harsh Trivedi
Harsh Trivedi
@harsh3vedi -
 Gabriel Stanovsky
Gabriel Stanovsky
@GabiStanovsky -
 Jonathan Berant @ COLM 2025
Jonathan Berant @ COLM 2025
@JonathanBerant -
 William Merrill
William Merrill
@lambdaviking -
 Arman Cohan
Arman Cohan
@armancohan
Something went wrong.
Something went wrong.