
The leaked Gemini 3 benchmarks look good and all, but I'm a little disappointed in the coding results. I guess I'll most likely be sticking with Claude

I don't get why there's no comparison to Opus 4.1, which is way smarter than Sonnet 4.5.


I’m not one to say to trust the benchmarks HOWEVER if it is that similar to Sonnet, that’s still a win imo in AI studio, Gemini 3 Pro is significantly faster than Sonnet, which would let you iterate a lot faster

to be fair, the benchmarks don’t do it justice as far as how it feels to actually code with it

It’s also about speed. Most projects do a decent job already. If speed if much faster than Claude with almost similar accuracy. It’s still a Win.

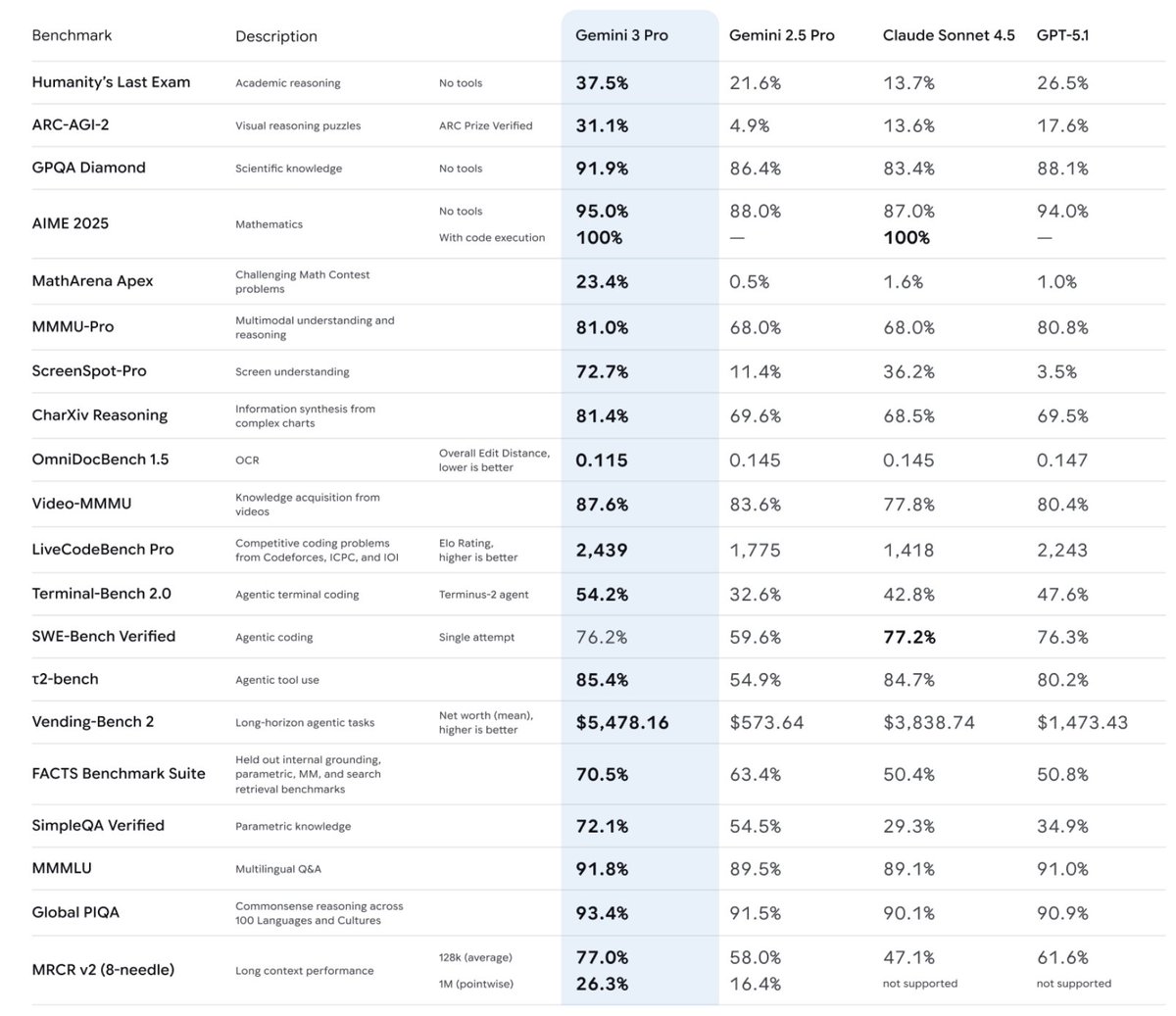
+one thousand ELO on LiveCodeBench Pro and 2:1 winrate vs 4.5 on Design Bench seems worth giving a shot

It’s honestly funny how Anthropic has been able to stay as the best coding model company

Gemini 3 Pro absolutely smokes and destroys all models in front-end taste

Anyone who has worked with actual industry codebases will soon quickly realise how ahead Claude is compared to every other llm. Gpt 5 codex is good, 3.7 level but not as good as 4 (not to mention it's often slow compared to Claude on ghcp)


I don't think benchmark are reliable, I was having an issue with writing a sql stored procedure and was constantly getting an error every top model failed from opus 4.1, gpt 5.1, claude 4.5 thinking but gemini 2.5 correctly identified that dbeaver was the issue



Get 30% off Clip Studio Paint Ver. 4.0 now during our Holiday Sale!✨ Ends December 25, 8:00 am UTC


I'll act like I understood what these benchmarks mean irl lol



It's faster, cheaper, overall smarter. It is just absolutely nonsensical to let one benchmark result, which is mind you practically on par, dissuade you from using the model entirely

idk how you use the gemini but it completely smokes the rest of the models in everything except agentic which almost neck to neck to claude and keep in mind this is only the preview version

how are those coding tests conducted btw? how are the problems defined?




United States 트렌드
- 1. Good Thursday 29.6K posts
- 2. #DareYouToDeathEP1 398K posts
- 3. Happy Friday Eve N/A
- 4. #thursdayvibes 1,839 posts
- 5. Cartoon Network 1,842 posts
- 6. #NicolandriaxGlamour 1,225 posts
- 7. #thursdaymotivation 1,869 posts
- 8. Disturbed 7,057 posts
- 9. Ally 30.4K posts
- 10. Newt 3,149 posts
- 11. Garfunkel N/A
- 12. Davido 281K posts
- 13. Nickelodeon 1,954 posts
- 14. Keith Richards 7,898 posts
- 15. #Survivor49 15.1K posts
- 16. TOP CALL 12K posts
- 17. Warrior Dividend 34.6K posts
- 18. Savannah 15.1K posts
- 19. 4 Republicans 12K posts
- 20. Lindsey 8,824 posts
Something went wrong.
Something went wrong.