
MIT NLP
@nlp_mit
NLP Group at @MIT_CSAIL! PIs: @yoonrkim @jacobandreas @lateinteraction @pliang279 @david_sontag, Jim Glass, @roger_p_levy
Hello everyone! We are quite a bit late to the twitter party, but welcome to the MIT NLP Group account! follow along for the latest research from our labs as we dive deep into language, learning, and logic 🤖📚🧠


🗞️ Dialogues with AI Reduce Beliefs in Misinformation but Build No Lasting Discernment Skills ➡️ While interactions with AI have been shown to durably reduce people’s beliefs in false information, it is unclear whether these interactions also teach people the skills to discern…

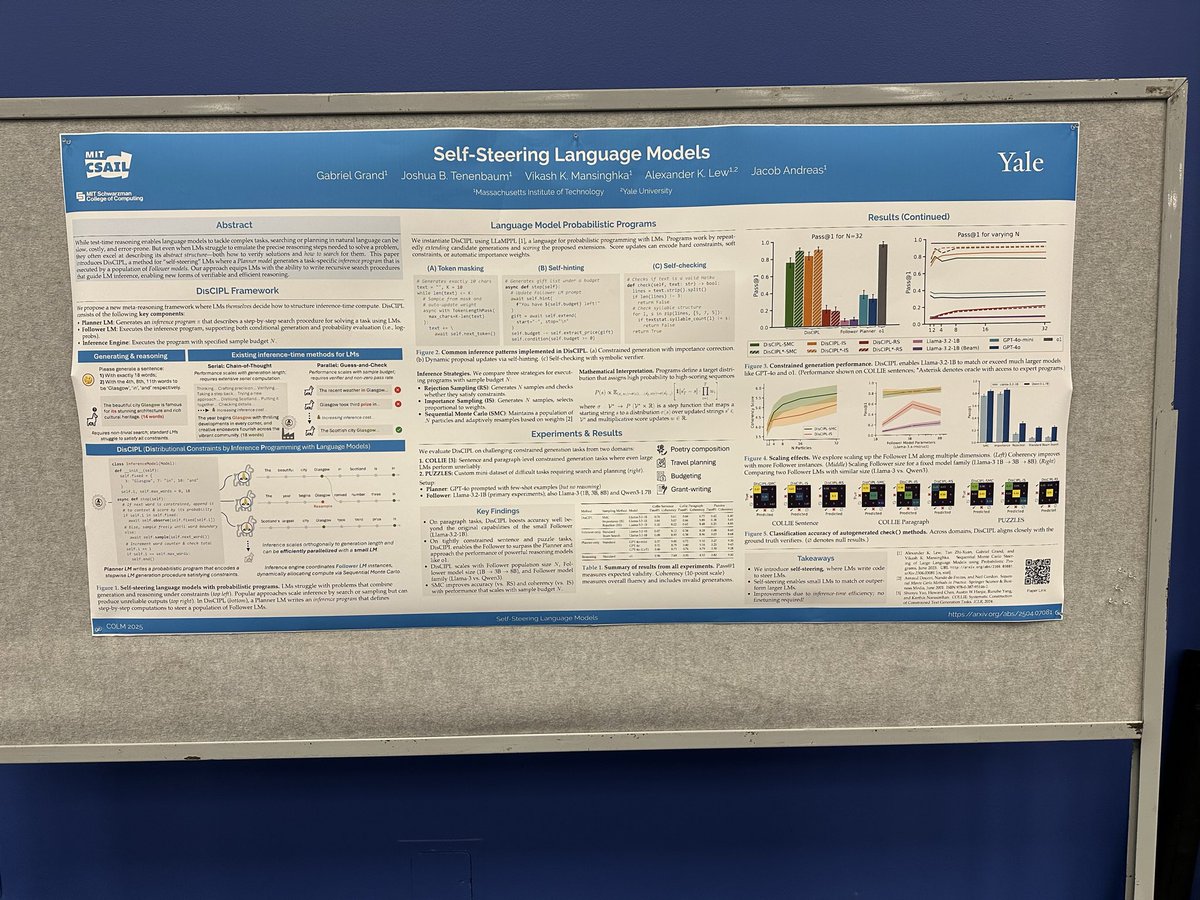
catch MIT NLP at @COLM_conf day 1! morning: @gabe_grand is presenting “Self Steering Language Models” @ben_lipkin is presenting “Fast Controlled Generation from Language Models with Adaptive Language righted Rejection Sampling” @KaivuHariharan is presenting “Breakpoint:…

Good morning @COLM_conf! Excited to present our poster on Self-Steering LMs (#50, 11AM-1PM). If you’re thinking about codegen, probabilistic inference, or parallel scaling, stop by for a chat!


flying to 🇨🇦 this week for #COLM2025! catch us on friday to hear our talk about RLCR at the SCALR@COLM workshop. reach out to chat about test time compute, rl for interaction, and anything else!
It seems GPT‑OSS is very prone to hallucinations … check out our RLCR paper to see how we trained reasoning models to know what they don't know. Website 🌐 and code 💻 out today! rl-calibration.github.io 🚀


I will be giving a talk on RLCR at the SCALR@COLM workshop on Friday! Come learn how LLMs can be trained to reason about their own uncertainty. Always happy to chat about RL and related ideas (DMs open)!
🚨New Paper!🚨 We trained reasoning LLMs to reason about what they don't know. o1-style reasoning training improves accuracy but produces overconfident models that hallucinate more. Meet RLCR: a simple RL method that trains LLMs to reason and reflect on their uncertainty --…

Exciting new work by @alexisjross @megha_byte on AI + education for code!

New preprint on AI + Education! 🍎 “Modeling Student Learning with 3.8M Program Traces” 💻 When students code, their edits tell a story about their reasoning process: exploring, debugging, and tinkering 🧠 What can LMs learn from training on student edit sequences? 📚


🎉 Accepted @ EMNLP! We found surprising brittleness of SOTA RMs under minor input changes and proposed a method to improve them. Paper now updated with more results including an evaluation of GPT-4o (which displays similar brittleness) arxiv.org/abs/2503.11751
Robust reward models are critical for alignment/inference-time algos, auto eval, etc. (e.g. to prevent reward hacking which could render alignment ineffective). ⚠️ But we found that SOTA RMs are brittle 🫧 and easily flip predictions when the inputs are slightly transformed 🍃 🧵


I am super excited to share our new paper “ REGen: Multimodal Retrieval-Embedded Generation for Long-to-Short Video Editing” has been accepted at #NeurIPS 2025. Paper: arxiv.org/abs/2505.18880 Demo: wx83.github.io/REGen/

a bit late – but my last PhD paper was accepted as an oral to #EMNLP2025 ! w/ @zhuci19 @stats_stephen Tommi Jaakkola reasoning LMs improve by thinking for longer, but longer is not always better *thought calibration* is an inference-time strategy for efficient test-time scaling


All the recordings for the @GPU_MODE x @scaleml series are up as a playlist in case you missed it 😁 There's so much value in these ~8 hours of lectures, from proving quantization error bounds on a whiteboard to a deep-dive into GPU warp schedulers! Plz take advantage of it!


For agents to improve over time, they can’t afford to forget what they’ve already mastered. We found that supervised fine-tuning forgets more than RL when training on a new task! Want to find out why? 👇


Since my undergraduate days at CMU, I've been participating in puzzlehunts: involving complex, multi-step puzzles, lacking well-defined problem definitions, with creative and subtle hints and esoteric world knowledge, requiring language, spatial, and sometimes even physical…
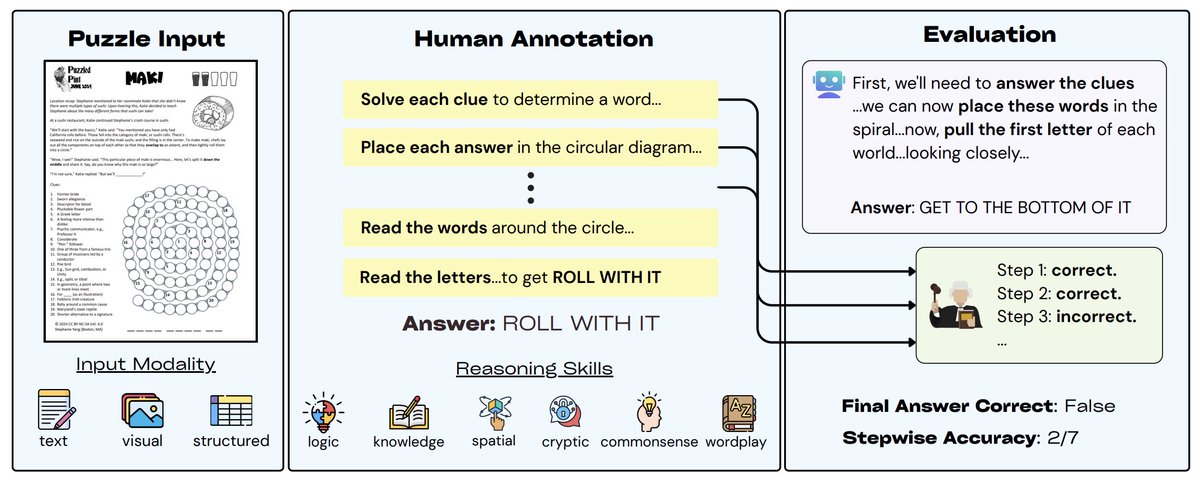

Most problems have clear-cut instructions: solve for x, find the next number, choose the right answer. Puzzlehunts don’t. They demand creativity and lateral thinking. We introduce PuzzleWorld: a new benchmark of puzzlehunt problems challenging models to think creatively.
✨New work on mathematical reasoning and attribution is now on arXiv! When given charts and questions, multimodal LLMs generate answers but often lack attribution (which granular chart elements drove the answer). If it sounds interesting, please read arxiv.org/abs/2508.16850 🗞️

A bit late, but finally got around to posting the recorded and edited lecture videos for the **How to AI (Almost) Anything** course I taught at MIT in spring 2025. Youtube playlist: youtube.com/watch?v=0MYt0u… Course website and materials: mit-mi.github.io/how2ai-course/… Today's AI can be…

It seems GPT‑OSS is very prone to hallucinations … check out our RLCR paper to see how we trained reasoning models to know what they don't know. Website 🌐 and code 💻 out today! rl-calibration.github.io 🚀

Scaling CLIP on English-only data is outdated now… 🌍We built CLIP data curation pipeline for 300+ languages 🇬🇧We train MetaCLIP 2 without compromising English-task performance (it actually improves! 🥳It’s time to drop the language filter! 📝arxiv.org/abs/2507.22062 [1/5] 🧵
![YungSungChuang's tweet image. Scaling CLIP on English-only data is outdated now…
🌍We built CLIP data curation pipeline for 300+ languages
🇬🇧We train MetaCLIP 2 without compromising English-task performance (it actually improves!
🥳It’s time to drop the language filter!
📝arxiv.org/abs/2507.22062
[1/5]
🧵](https://pbs.twimg.com/media/GxHWT25agAAIWqD.jpg)
🚨new paper alert!🚨 rl for calibration 🚀🚀🚀
fun new paper training LLMs to analyze their own uncertainty and be more calibrated in their confidence! arxiv.org/abs/2507.16806
fun new paper training LLMs to analyze their own uncertainty and be more calibrated in their confidence! arxiv.org/abs/2507.16806
🚨New Paper!🚨 We trained reasoning LLMs to reason about what they don't know. o1-style reasoning training improves accuracy but produces overconfident models that hallucinate more. Meet RLCR: a simple RL method that trains LLMs to reason and reflect on their uncertainty --…
Check out this new paper training LLMs to analyze their own uncertainty and be more calibrated! from @MehulDamani2 @ishapuri101 @StewartSlocum1 @IdanShenfeld and co!
🚨New Paper!🚨 We trained reasoning LLMs to reason about what they don't know. o1-style reasoning training improves accuracy but produces overconfident models that hallucinate more. Meet RLCR: a simple RL method that trains LLMs to reason and reflect on their uncertainty --…
I'm currently in Vancouver for #ICML2025 this week and will present our work, "Understanding the Emergence of Multimodal Representation Alignment" later today at 4:30pm. Come by to chat!


























































































United States الاتجاهات
- 1. Good Sunday 58.9K posts
- 2. Troy Franklin N/A
- 3. Brownlee N/A
- 4. #sundayvibes 5,430 posts
- 5. #AskFFT N/A
- 6. #AskBetr N/A
- 7. Rich Eisen N/A
- 8. Jermaine Johnson N/A
- 9. Muhammad Qasim 19.2K posts
- 10. Pat Bryant N/A
- 11. Mason Taylor N/A
- 12. #DENvsNYJ 1,007 posts
- 13. #NationalFarmersDay N/A
- 14. Miary Zo 2,110 posts
- 15. Discussing Web3 N/A
- 16. KenPom N/A
- 17. Wordle 1,576 X N/A
- 18. Trump's FBI 14.9K posts
- 19. The CDC 33.3K posts
- 20. Biden FBI 22.3K posts
Something went wrong.
Something went wrong.