
You might like
















GEPA featured in @OpenAI and @BainandCompany new cookbook tutorial, showing how to build self-evolving agents that move beyond static prompts. See how GEPA dynamically enables agents to autonomously reflect, learn from feedback, and evolve their own instructions.


Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range.


I'm constantly irritated that I don't have time to read the torrent of cool papers coming faster and faster from amazing people in relevant fields. Other scientists have the same issue and have no time to read most of my lengthy conceptual papers either. So whom are we writing…

wtf, a 80-layers 321M model???
Synthetic playgrounds enabled a series of controlled experiments that brought us to favor extreme depth design. We selected a 80-layers architecture for Baguettotron, with improvements across the board on memorization of logical reasoning: huggingface.co/PleIAs/Baguett…


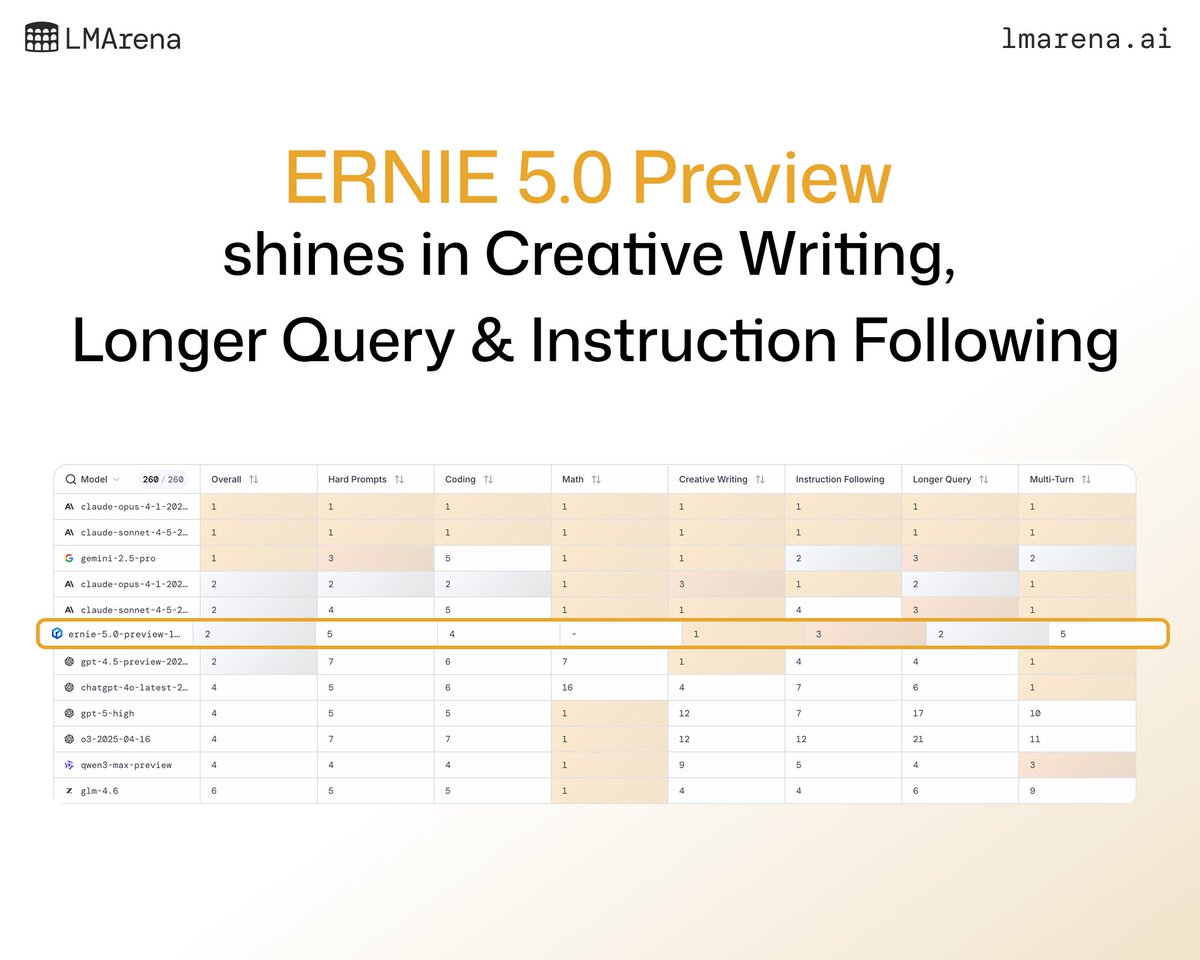
ERNIE-5.0-Preview-1022 shines in Creative Writing, Longer Query & Instruction Following. Click through to see all the leaderboard details by key categories: lmarena.ai/leaderboard/te…

LLMSys 我愿意称之为NvidiaSys,谁懂NV toolchain stack,谁就掌握了LLM。 但是NV已经到了顶点,在不远的将来就只有下坡路了。

Edison Scientific (a brand-new company spun out of FutureHouse) releases Kosmos: An AI Scientist for Autonomous Discovery "Our beta users estimate that Kosmos can do in one day what would take them 6 months, and we find that 79.4% of its conclusions are accurate." The paper…


important research paper from google... "LLMs don't just memorize, they build a geometric map that helps them reason" according to the paper: – builds a global map from only local pairs – plans full unseen paths when knowledge is in weights; fails in context – turns a…


1/2) Subham Sahoo (@ssahoo_, @cornell PhD) presented his amozing work on "The Diffusion Duality" in our Generative Memory Lab channel. A must watch for people interested in discrete diffusion! Link below:


The Illustrated NeurIPS 2025: A Visual Map of the AI Frontier New blog post! NeurIPS 2025 papers are out—and it’s a lot to take in. This visualization lets you explore the entire research landscape interactively, with clusters, summaries, and @cohere LLM-generated explanations…



Holy shit... this might be the next big paradigm shift in AI. 🤯 Tencent + Tsinghua just dropped a paper called Continuous Autoregressive Language Models (CALM) and it basically kills the “next-token” paradigm every LLM is built on. Instead of predicting one token at a time,…




近日,日本參議院議員石平在自己的個人YouTube頻道中,痛罵中國國家主席習近平29分鐘! 包括但不限於「小學生」「傻X」「蠢豬」「不是個東西」等金句! 火力之猛,實屬日本現役參議員中的罕見! 影片連結放到下方第一條評論中 👇👇👇

笑出猪叫 近日,日本参议院议员石平在自己的个人YouTube頻道中,对习包子全程开大,多达29分鐘! 包括但不限于「小学生」「傻X」「蠢猪」等金句! 骂得好 发出来给小粉们破防下🤪

Samsung's Tiny Recursive Model (TRM) masters complex reasoning With just 7M parameters, TRM outperforms large LLMs on hard puzzles like Sudoku & ARC-AGI. This "Less is More" approach redefines efficiency in AI, using less than 0.01% of competitors' parameters!


Transfusion combines autoregressive with diffusion to train a single transformer, but what if we combine Flow with Flow? 🤔 🌊OneFlow🌊 the first non-autoregressive model to generate text and images concurrently using a single transformer—unifying Edit Flow (text) with Flow…

Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for…

🤔Can we train RL on LLMs with extremely stale data? 🚀Our latest study says YES! Stale data can be as informative as on-policy data, unlocking more scalable, efficient asynchronous RL for LLMs. We introduce M2PO, an off-policy RL algorithm that keeps training stable and…


Introducing Pretraining with Hierarchical Memories: Separating Knowledge & Reasoning for On-Device LLM Deployment 💡We propose dividing LLM parameters into 1) anchor (always used, capturing commonsense) and 2) memory bank (selected per query, capturing world knowledge). [1/X]🧵






























































































United States Trends
- 1. Nicki Minaj 47.9K posts
- 2. Chase Brown 2,108 posts
- 3. Bucs 6,384 posts
- 4. Bryce Young 2,468 posts
- 5. James Cook 4,904 posts
- 6. Judkins 5,691 posts
- 7. JJ McCarthy 2,547 posts
- 8. Ewers 4,818 posts
- 9. #KeepPounding 2,380 posts
- 10. #Browns 3,435 posts
- 11. #BillsMafia 6,512 posts
- 12. Jaxson Dart 2,113 posts
- 13. #Skol 1,785 posts
- 14. Abdul Carter N/A
- 15. #DawgPound 2,361 posts
- 16. Titans 13.8K posts
- 17. Theo Johnson N/A
- 18. Brian Burns N/A
- 19. Sean Tucker N/A
- 20. Mike Evans 2,532 posts
You might like
-
 subho
subho
@subhobrata1 -
 Greg Kamradt
Greg Kamradt
@GregKamradt -
 COSMIC 🐙 SLOP
COSMIC 🐙 SLOP
@afrocosmist -
 Jorge Hernandez 🇺🇦 🏳️🌈
Jorge Hernandez 🇺🇦 🏳️🌈
@braneloop -
 Richard Nadler
Richard Nadler
@RichardNadler1 -
 Marketing AI Institute
Marketing AI Institute
@MktgAi -
 Exa
Exa
@ExaAILabs -
 soulo
soulo
@soulosaint -
 Aleksa Gordić (水平问题)
Aleksa Gordić (水平问题)
@gordic_aleksa -
 The Spaceshipper 🚀
The Spaceshipper 🚀
@TheSpaceshipper -
 T Tian
T Tian
@gdsttian -
 Daily AI Papers
Daily AI Papers
@papers_daily -
 らうじぃ
らうじぃ
@Rauziii -
 Tejas Kulkarni
Tejas Kulkarni
@tejasdkulkarni -
 Mia ✦彡
Mia ✦彡
@mia_novakova
Something went wrong.
Something went wrong.