
你可能會喜歡


















近日,日本參議院議員石平在自己的個人YouTube頻道中,痛罵中國國家主席習近平29分鐘! 包括但不限於「小學生」「傻X」「蠢豬」「不是個東西」等金句! 火力之猛,實屬日本現役參議員中的罕見! 影片連結放到下方第一條評論中 👇👇👇

笑出猪叫 近日,日本参议院议员石平在自己的个人YouTube頻道中,对习包子全程开大,多达29分鐘! 包括但不限于「小学生」「傻X」「蠢猪」等金句! 骂得好 发出来给小粉们破防下🤪

Samsung's Tiny Recursive Model (TRM) masters complex reasoning With just 7M parameters, TRM outperforms large LLMs on hard puzzles like Sudoku & ARC-AGI. This "Less is More" approach redefines efficiency in AI, using less than 0.01% of competitors' parameters!


Transfusion combines autoregressive with diffusion to train a single transformer, but what if we combine Flow with Flow? 🤔 🌊OneFlow🌊 the first non-autoregressive model to generate text and images concurrently using a single transformer—unifying Edit Flow (text) with Flow…

Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for…

🤔Can we train RL on LLMs with extremely stale data? 🚀Our latest study says YES! Stale data can be as informative as on-policy data, unlocking more scalable, efficient asynchronous RL for LLMs. We introduce M2PO, an off-policy RL algorithm that keeps training stable and…


Introducing Pretraining with Hierarchical Memories: Separating Knowledge & Reasoning for On-Device LLM Deployment 💡We propose dividing LLM parameters into 1) anchor (always used, capturing commonsense) and 2) memory bank (selected per query, capturing world knowledge). [1/X]🧵

My brain broke when I read this paper. A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2. It's called Tiny Recursive Model (TRM) from Samsung. How can a model 10,000x smaller be smarter? Here's how…


Absolutely classic @GoogleResearch paper on In-Context-Learning by LLMs. Shows the mechanisms of how LLMs learn in context from examples in the prompt, can pick up new patterns while answering, yet their stored weights never change. 💡The mechanism they reveal for…

No Prompt Left Behind: A New Era for LLM Reinforcement Learning This paper introduces RL-ZVP, a novel algorithm that unlocks learning signals from previously ignored "zero-variance prompts" in LLM training. It achieves significant accuracy improvements on math reasoning…


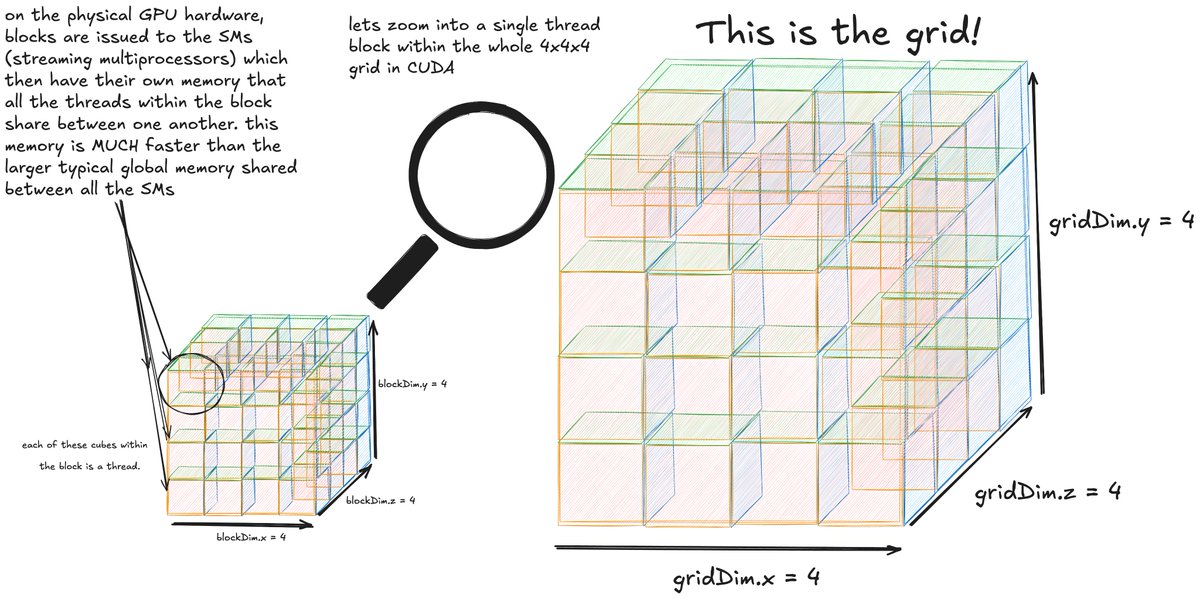

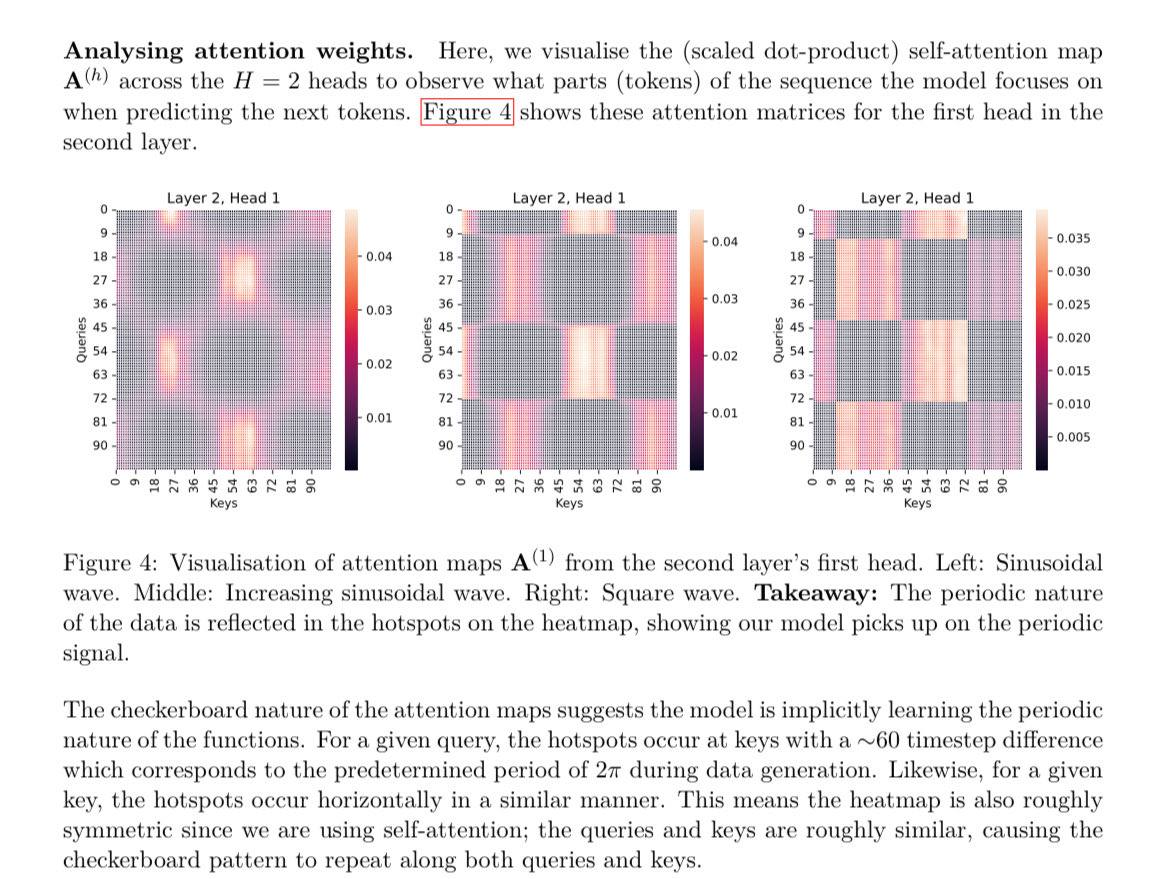
This is a super cool topic! I did a class project with a friend for a course on Kernels during senior year in college 🔗: github.com/rish-16/ma4270… Lots of fun connections between kernels and self-attention, especially when learning periodic functions The attention patterns…



How Kernel Regression is related to Attention Mechanism - a summary in 10 slides. 0/1

The paper shows that Group Relative Policy Optimization (GRPO) behaves like Direct Preference Optimization (DPO), so training on simple answer pairs works. Turns a complex GRPO setup into a simple pairwise recipe without losing quality. This cuts tokens, compute, and wall time,…


🚀 Want high-quality, realistic, and truly challenging post-training data for the agentic era? Introducing Toucan-1.5M (huggingface.co/papers/2510.01…) — the largest open tool-agentic dataset yet: ✨ 1.53M real agentic trajectories synthesized by 3 models ✨ Diverse, challenging tasks…

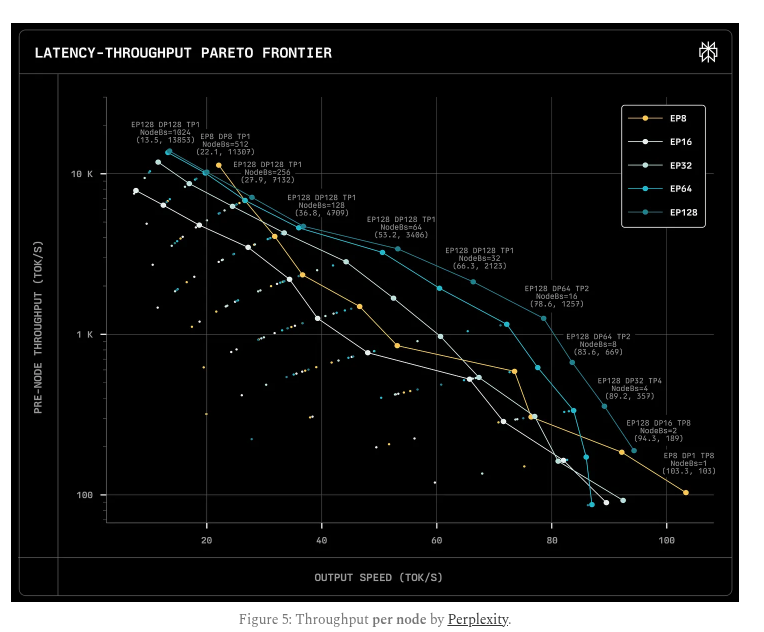
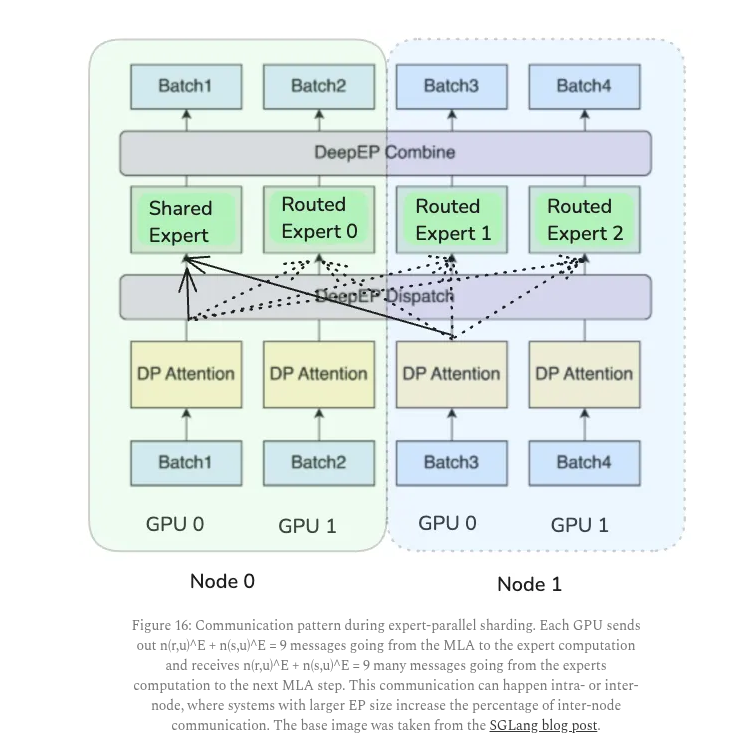
This is a solid blog breaking down how mixture-of-experts (MoE) language models can actually be served cheaply if their design is matched to hardware limits. MoE models only activate a few experts per token, which saves compute but causes heavy memory and communication use.…



Analysis of KL estimator k1, k2, k3 and their use as a reward or as a loss. Partially this is a continuation of previous discussions on it x.com/QuanquanGu/sta…. By the way RLHF is a bit misleading; they did RLVR.


The original GRPO is an off-policy RL algorithm, but its KL regularization isn't done right. Specifically, the k3 estimator for the unnormalized reverse KL is missing the importance weight. The correct formulation should be:


Meta just ran one of the largest synthetic-data studies (over 1000 LLMs, more than 100k GPU hours). Result: mixing synthetic and natural data only helps once you cross the right scale and ratio (~30%). Small models learn nothing; larger ones suddenly gain a sharp threshold…


RL fine-tuning often prematurely collapses policy entropy. We consider a general framework, called set RL, i.e. RL over a set of trajectories from a policy. We use it to incentivize diverse solutions & optimize for inference time performance. Paper: arxiv.org/abs/2509.25424

Exploration is fundamental to RL. Yet policy gradient methods often collapse: during training they fail to explore broadly, and converge into narrow, easily exploitable behaviors. The result is poor generalization, limited gains from test-time scaling, and brittleness on tasks…


🚨🚨New Paper: Training LLMs to Discover Abstractions for Solving Reasoning Problems Introducing RLAD, a two-player RL framework for LLMs to discover 'reasoning abstractions'—natural language hints that encode procedural knowledge for structured exploration in reasoning.🧵⬇️































































































United States 趨勢
- 1. #IDontWantToOverreactBUT 1,230 posts
- 2. #maddiekowalski N/A
- 3. Clemens N/A
- 4. #MondayMotivation 37.7K posts
- 5. Phillips 494K posts
- 6. Howie 8,777 posts
- 7. Victory Monday 4,056 posts
- 8. Hobi 59.4K posts
- 9. Bradley 7,357 posts
- 10. 60 Minutes 134K posts
- 11. Ben Shapiro 6,417 posts
- 12. Mattingly 1,965 posts
- 13. Jeff Kent N/A
- 14. Bonnies N/A
- 15. Good Monday 54.8K posts
- 16. #MondayVibes 3,654 posts
- 17. Tomorrow is Election Day 1,977 posts
- 18. No to Israel 19.8K posts
- 19. JUST ANNOUNCED 27.4K posts
- 20. $IREN 18.2K posts
你可能會喜歡
-
 subho
subho
@subhobrata1 -
 Greg Kamradt
Greg Kamradt
@GregKamradt -
 ZOMBIE 🧟♂️ SLOP
ZOMBIE 🧟♂️ SLOP
@afrocosmist -
 Jorge Hernandez 🇺🇦 🏳️🌈
Jorge Hernandez 🇺🇦 🏳️🌈
@braneloop -
 Richard Nadler
Richard Nadler
@RichardNadler1 -
 Stockimg.ai
Stockimg.ai
@stockimgAI -
 Marketing AI Institute
Marketing AI Institute
@MktgAi -
 Exa
Exa
@ExaAILabs -
 Error.PDF
Error.PDF
@ErrorPdf -
 soulo
soulo
@soulosaint -
 Chris Hytha
Chris Hytha
@Hythacg -
 ⛩️ 𝑫𝒆𝒂𝒕𝒉 𝒃𝒚 𝑯𝒊𝒃𝒂𝒄𝒉𝒊 ⛩️
⛩️ 𝑫𝒆𝒂𝒕𝒉 𝒃𝒚 𝑯𝒊𝒃𝒂𝒄𝒉𝒊 ⛩️
@deathbyhibachi -
 Aleksa Gordić (水平问题)
Aleksa Gordić (水平问题)
@gordic_aleksa -
 The Spaceshipper 🚀
The Spaceshipper 🚀
@TheSpaceshipper -
 T Tian
T Tian
@gdsttian
Something went wrong.
Something went wrong.