
Parameter Lab
@parameterlab
Empowering individuals and organisations to safely use foundational AI models.
قد يعجبك














🎉Delighted to announce that our 🫗Leaky Thoughts paper about contextual privacy with reasoning models is accepted to #EMNLP main! Huge congrats to the amazing team @tommasogreen @HaritzPuerto @coallaoh @oodgnas
Delighted by this great thread from @omarsar0 presenting our new Leaky Thoughts paper! We show that reasoning models pose serious privacy risks when used as personal agents. Reasoning traces are a new attack vector. Work led by @tommasogreen during his internship @parameterlab!

🧪 Our latest research: Does SEO boost the visibility of content in LLM-based conversational search? We present C-SEO Bench, a benchmark to evaluate conversational SEO strategies. Key takeaway: SEO methods that target LLM do not work. But surprisingly, traditional SEO is not…


🔎 Does Conversational SEO (C-SEO) actually work? Our new benchmark has an answer. Excited to announce C-SEO Bench: Does Conversational SEO Work? 🌐 RTAI: researchtrend.ai/papers/2506.11… 📄 Paper: arxiv.org/abs/2506.11097 💻 Code: github.com/parameterlab/c… 📊 Data: huggingface.co/datasets/param…

We see news like this from time to time and that’s why it’s vital to keep researching on tools to prove these cases! Our #NAACL2025 paper shows that with over 10k tokens, we can reliably detect whether a text was part of an LLM’s training data aclanthology.org/2025.findings-…

Disney, Universal sue image creator Midjourney for copyright infringement reut.rs/3SMqtlu


Proud to have co-led more than 200 of those 999 during my time at Google.



Check out the 999 open models that Google has released on @huggingface: huggingface.co/google (Comparative numbers: 387 for Microsoft, 33 for OpenAI, 0 for Anthropic).

Do you want to prove that your copyrighted document/corpus was trained by an LLM? Come to poster 46 #NAACL2025

#NAACL2025 has started! I’ll be presenting my work at @parameterlab about detecting pretraining data on Friday 🗓️ May 2, 11:00 AM - May 2, 12:30 PM 🗺️ Poster Session 8 - APP: NLP Applications Location: Hall 3 Work with @framart1 @oodgnas @coallaoh
🧵 It is assumed that Membership Inference Attacks (MIA) do not work on LLMs, but our new paper shows it can work at the right scale! MIA is effective if the number of input tokens is large enough, such as in long documents and collections of them. 📃arxiv.org/abs/2411.00154

I will be in person at #NAACL2025 🌵🇺🇸 to present Scaling Up Membership Inference: When and How Attacks Succeed on LLMs. Come and say hi 👋 if you want to know how to proof if an LLM was trained on a data point!
🧵 It is assumed that Membership Inference Attacks (MIA) do not work on LLMs, but our new paper shows it can work at the right scale! MIA is effective if the number of input tokens is large enough, such as in long documents and collections of them. 📃arxiv.org/abs/2411.00154

GPT-4o image gen is seriously impressive. People are unlocking new creative ways to use it. 10 wild examples

👥 We're Hiring: Senior/Junior Data Engineer! 📍 Remote or Local | Full-Time or Part-Time At ResearchTrend.AI, we’re building a platform that connects researchers and AI engineers worldwide—helping them stay ahead with daily digests, insightful summaries, and interactive…

🔎 Wonder how to prove an LLM was trained on a specific text? The camera ready of our Findings of #NAACL 2025 paper is available! 📌 TLDR: longs texts are needed to gather enough evidence to determine whether specific data points were included in training of LLMs:…
🧵 It is assumed that Membership Inference Attacks (MIA) do not work on LLMs, but our new paper shows it can work at the right scale! MIA is effective if the number of input tokens is large enough, such as in long documents and collections of them. 📃arxiv.org/abs/2411.00154

We just wanted to say: Membership inference is unlikely to succeed on n-grams or even paragraphs. Language models require **multiple documents** to gather enough evidence to determine whether specific data points were included in training. Accepted to #NAACL2025 Findings.
I'm excited to announce that my internship paper at @parameterlab was accepted to Findings of #NAACL2025 🎉 Huge thanks to @framart1 @coallaoh and @oodgnas! Amazing team!!
I'm excited to announce that my internship paper at @parameterlab was accepted to Findings of #NAACL2025 🎉 Huge thanks to @framart1 @coallaoh and @oodgnas! Amazing team!!
🧵 It is assumed that Membership Inference Attacks (MIA) do not work on LLMs, but our new paper shows it can work at the right scale! MIA is effective if the number of input tokens is large enough, such as in long documents and collections of them. 📃arxiv.org/abs/2411.00154
techcrunch.com/2025/01/09/mar… From time to time we hear news like this. However, proving that an LLM was trained on a specific document is very challenging 🥴 This motivated my latest work, where we show that current methods can be effective if we use enough data 🧐

There's an internship opening at @parameterlab : parameterlab.de/careers The research outputs have been quite successful so far: researchtrend.ai/organizations/…

🎉 We’re pleased to share the release of the models from our Apricot 🍑 paper, "Calibrating Large Language Models Using Their Generations Only", accepted at ACL 2024! At Parameter Lab, we believe openness and reproducibility are essential for advancing science, and we've put in…
🔥 Curious about the latest trends in AI? ResearchTrend.AI gives you an intuitive overview of diverse topics in AI. Dive into our dashboard featuring 55 communities ready for you to explore! 👉 Visit: researchtrend.ai/communities Browse and follow your favourite communities.…

🚨📄 Exciting new research! Discover when and at what scale we can detect if specific data was used in training LLMs — a method known as Membership Inference (MIA)! Our findings open new doors for using MIA as potential legal evidence in AI. More info in the 🧵below.

🧵 It is assumed that Membership Inference Attacks (MIA) do not work on LLMs, but our new paper shows it can work at the right scale! MIA is effective if the number of input tokens is large enough, such as in long documents and collections of them. 📃arxiv.org/abs/2411.00154
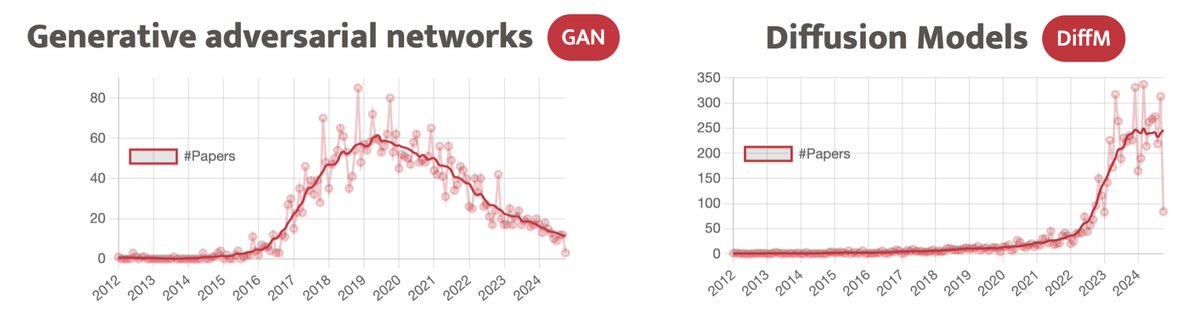
The GAN community peaked around 2019 and has been declining since 2020. Today, there is little update in this area as Diffusion Models have taken over, which gained momentum in 2022. Visit researchtrend.ai to learn more. #ResearchTrendAI We're seeking a marketer. DM me!






























































































United States الاتجاهات
- 1. D’Angelo 268K posts
- 2. Brown Sugar 19.9K posts
- 3. #PortfolioDay 14.8K posts
- 4. Young Republicans 11.3K posts
- 5. Pentagon 107K posts
- 6. Drew Struzan 25.9K posts
- 7. Politico 158K posts
- 8. Black Messiah 10.2K posts
- 9. Big 12 13.2K posts
- 10. Scream 3 N/A
- 11. Voodoo 20.5K posts
- 12. Jeff Albert N/A
- 13. Venables 3,409 posts
- 14. Soybeans 4,472 posts
- 15. Merino 11.9K posts
- 16. VPNs 1,369 posts
- 17. Baldwin 20.2K posts
- 18. Happy Birthday Charlie 143K posts
- 19. How Does It Feel 8,927 posts
- 20. World Cup 319K posts
قد يعجبك
-
 Aarav AI
Aarav AI
@defikin -
 Suyog
Suyog
@Flux159 -
 Junhwa Hur
Junhwa Hur
@JunhwaHur -
 Blissur
Blissur
@ITS_HEREEEE -
 Sungbin Lim
Sungbin Lim
@sungbin_ku -
 Daesik Kim
Daesik Kim
@chuckguhaja -
 robik shrestha
robik shrestha
@ShresthaRobik -
 sha λ
sha λ
@entropic_sapien -
 Charles Shen
Charles Shen
@CharlesShenPhD -
 Hubert Rozmarynowski
Hubert Rozmarynowski
@hbrt_me -
 Arjun Ashok
Arjun Ashok
@arjunashok37 -
 Karanjot Vendal
Karanjot Vendal
@VendalKaranjot -
 Calm
Calm
@Cocoa_ukk
Something went wrong.
Something went wrong.