






agi was the friends we made along the way


Introducing INTELLECT-3: Scaling RL to a 100B+ MoE model on our end-to-end stack Achieving state-of-the-art performance for its size across math, code and reasoning Built using the same tools we put in your hands, from environments & evals, RL frameworks, sandboxes & more

should've shot farther :^)

≈320B 15B active, calling it Trillion-class on the next turn go on, surprise me






> be arcee > look around > realize open-weight frontier MoE is basically a Qwen/DeepSeek monopoly > decide “nah, we’re building our own” > actual end-to-end pretraining > on US soil > introducing Trinity > Nano (6B MoE) and Mini (26B MoE) > open weights, Apache 2.0 > free on…


few people exemplify the spirit of "just doing things" to the degree that @stochasticchasm does. dude is 25 and has been at @arcee_ai less than a year and is driving pretraining efforts which rival the ambition of pretty much anything else in the open. this is a moneyball moment

ArceeAI Just dropped Trinity models -mini and -nano variants with sizes 26B and 6B, there is a 3rd one with larger size (420B !)cooking still. Read the details in blog arcee.ai/blog/the-trini…

Hell of a day to launch

Today, we are introducing Trinity, the start of an open-weight MoE family that businesses and developers can own. Trinity-Mini (26B-A3B) Trinity-Nano-Preview (6B-A1B) Available Today on Huggingface.

This is how you train SOTA models in late 2025.

Today, we are introducing Trinity, the start of an open-weight MoE family that businesses and developers can own. Trinity-Mini (26B-A3B) Trinity-Nano-Preview (6B-A1B) Available Today on Huggingface.

The 420B-A13B is coming in January which will be SO BIG! The biggest American pretrained model released in a long time
Today, we are introducing Trinity, the start of an open-weight MoE family that businesses and developers can own. Trinity-Mini (26B-A3B) Trinity-Nano-Preview (6B-A1B) Available Today on Huggingface.

cant wait to post train this model family
We're excited to support @Arcee_ai's Trinity models A family of open base Mixture of Experts models pretrained in collaboration between Arcee, Datology, and Prime Intellect Releasing Trinity Nano (6B) and Mini (26B) today, with Trinity Large still in training
it's the dawn of a glorious new era for western open models congrats @arcee_ai on an incredible release!! thrilled we got to be a part of it :)


Today, we are introducing Trinity, the start of an open-weight MoE family that businesses and developers can own. Trinity-Mini (26B-A3B) Trinity-Nano-Preview (6B-A1B) Available Today on Huggingface.
Read a more thought-out and less sleep-deprived breakdown here: arcee.ai/blog/the-trini…

Full thread with blog post and benchmark results: x.com/latkins/status…
Today, we are introducing Trinity, the start of an open-weight MoE family that businesses and developers can own. Trinity-Mini (26B-A3B) Trinity-Nano-Preview (6B-A1B) Available Today on Huggingface.
Arcee's Trinity Mini and Nano are live now! It's been an incredible couple of months collaborating on this pre-training run with the great folks at @arcee_ai and @datologyai. Job's not finished. Trinity Large is still training 🫡
We're excited to support @Arcee_ai's Trinity models A family of open base Mixture of Experts models pretrained in collaboration between Arcee, Datology, and Prime Intellect Releasing Trinity Nano (6B) and Mini (26B) today, with Trinity Large still in training
We're excited to support @Arcee_ai's Trinity models A family of open base Mixture of Experts models pretrained in collaboration between Arcee, Datology, and Prime Intellect Releasing Trinity Nano (6B) and Mini (26B) today, with Trinity Large still in training
Today, we are introducing Trinity, the start of an open-weight MoE family that businesses and developers can own. Trinity-Mini (26B-A3B) Trinity-Nano-Preview (6B-A1B) Available Today on Huggingface.


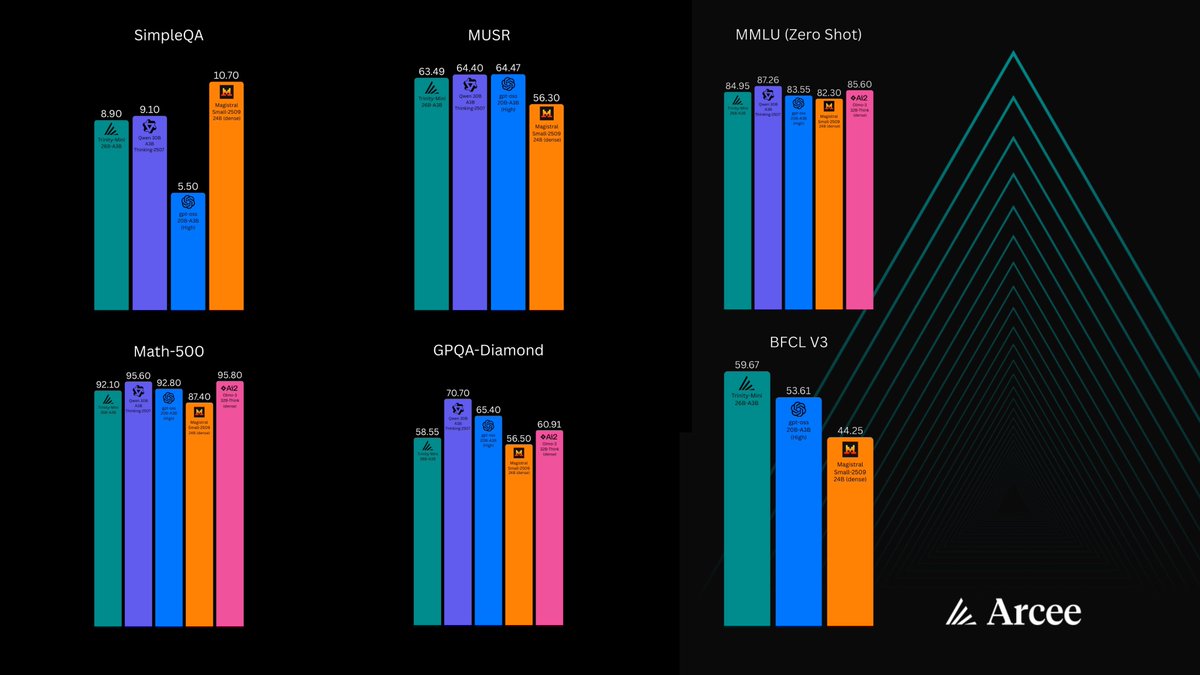
This is what I have using prime's exact settings: aime2024: 89.79% aime2025: 87.71% avg@32 w/ temp=0.6, top_p=1.0, max_tokens=81920 template = "Solve the following math problem. Explain your reasoning and put the final answer in \\boxed{{}}.\n\n{prompt}"
I’ve been able to match prime’s results for INTELLECT-3 closely, within 1% of aime scores reported, using longer response length limits and the exact prompt they used for evaluation. (There was some clipping at 65k.) GLM-4.5-Air is still running, will update when it lands :)
Adding my local results to the discussion. I haven't been able to reproduce the claimed 5%+ gap in prime's headline plots, and I'm seeing a difference within noise with several different prompt formats. x.com/PrimeIntellect…

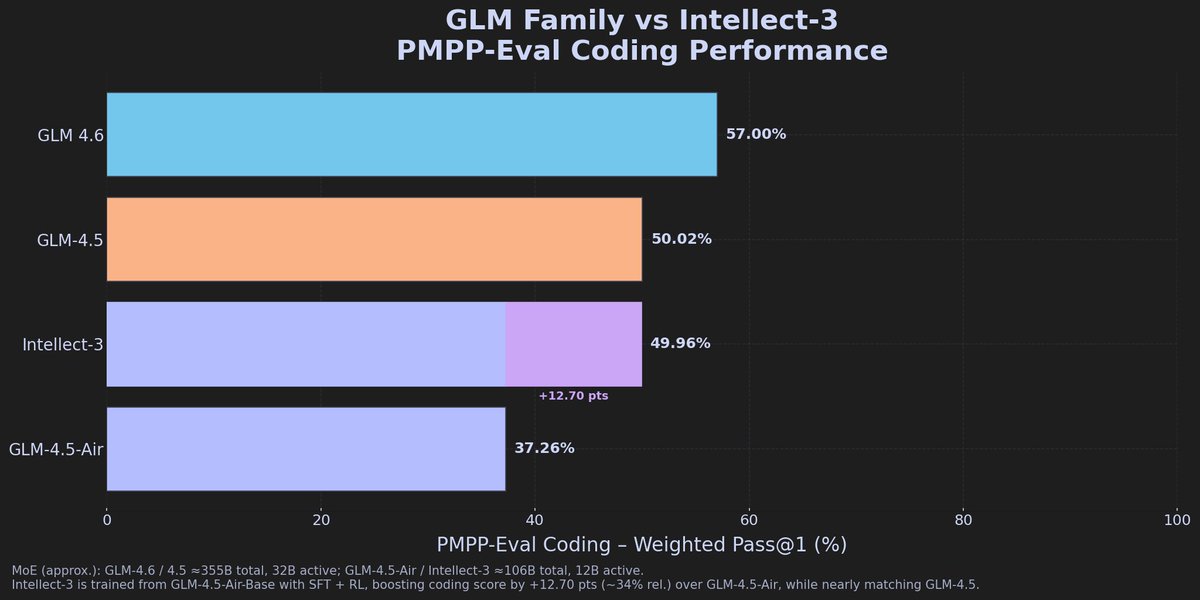
What's really interesting here is that Prime Intellect has quietly built one of the best post-training pipelines in the open source space. Their SFT and RL setup is pulling ahead of 4.5-Air even approaching GLM-4.5 on CUDA coding tasks. The % difference is honestly impressive.
Small PMPP-Eval update for freshly released Intellect-3 by @PrimeIntellect From my personal tests it was clear that its outperforming the Air variant (which uses same base model) numbers are confirming this with +%34 difference compared to Air and on par with 3x sized GLM-4.5

























































































United States الاتجاهات
- 1. Lakers 49.9K posts
- 2. Dillon Brooks 6,960 posts
- 3. Bron 24.7K posts
- 4. Giants 85.7K posts
- 5. #WWERaw 71K posts
- 6. Patriots 131K posts
- 7. Dart 36.2K posts
- 8. Suns 19.1K posts
- 9. Kanata 9,735 posts
- 10. Collin Gillespie 2,034 posts
- 11. Drake Maye 24.4K posts
- 12. #AvatarFireAndAsh 2,997 posts
- 13. STEAK 10.5K posts
- 14. Ryan Nembhard 4,198 posts
- 15. Diaz 34K posts
- 16. Devin Williams 7,730 posts
- 17. Gunther 15.2K posts
- 18. Pats 16.3K posts
- 19. James Cameron 4,590 posts
- 20. Devin Booker 2,634 posts






Something went wrong.
Something went wrong.