
Ricardo Dominguez-Olmedo
@rdolmedo_
PhD student at the Max Planck Institute for Intelligent Systems, working with Moritz Hardt and Bernhard Schölkopf.
You might like








After giving all 3 model families the same amount of preparation prior to evaluation, Pythia performs just as well as Llama and Qwen. Pythia got everything right back in October 2022! Since then, improvements in performance largely come from 1) scale and 2) test task training.


🚀 New Paper & Benchmark! Introducing MATH-Beyond (MATH-B), a new math reasoning benchmark deliberately constructed for common open-source models (≤8B) to fail at pass@1024! Paper: arxiv.org/abs/2510.11653 Dataset: huggingface.co/datasets/brend… 🧵1/10


We (Moritz Hardt, @walesalaudeen96,@joavanschoren) are organizing the Workshop on the Science of Benchmarking & Evaluating AI @EurIPSConf 2025 in Copenhagen! 📢 Call for Posters: rb.gy/kyid4f 📅 Deadline: Oct 10, 2025 (AoE) 🔗 More Info: rebrand.ly/bg931sf

My PhD advisor, Moritz Hardt, has just released the first half of his new book, The Emerging Science of Machine Learning Benchmarks. It’s freely available and highly recommended: mlbenchmarks.org
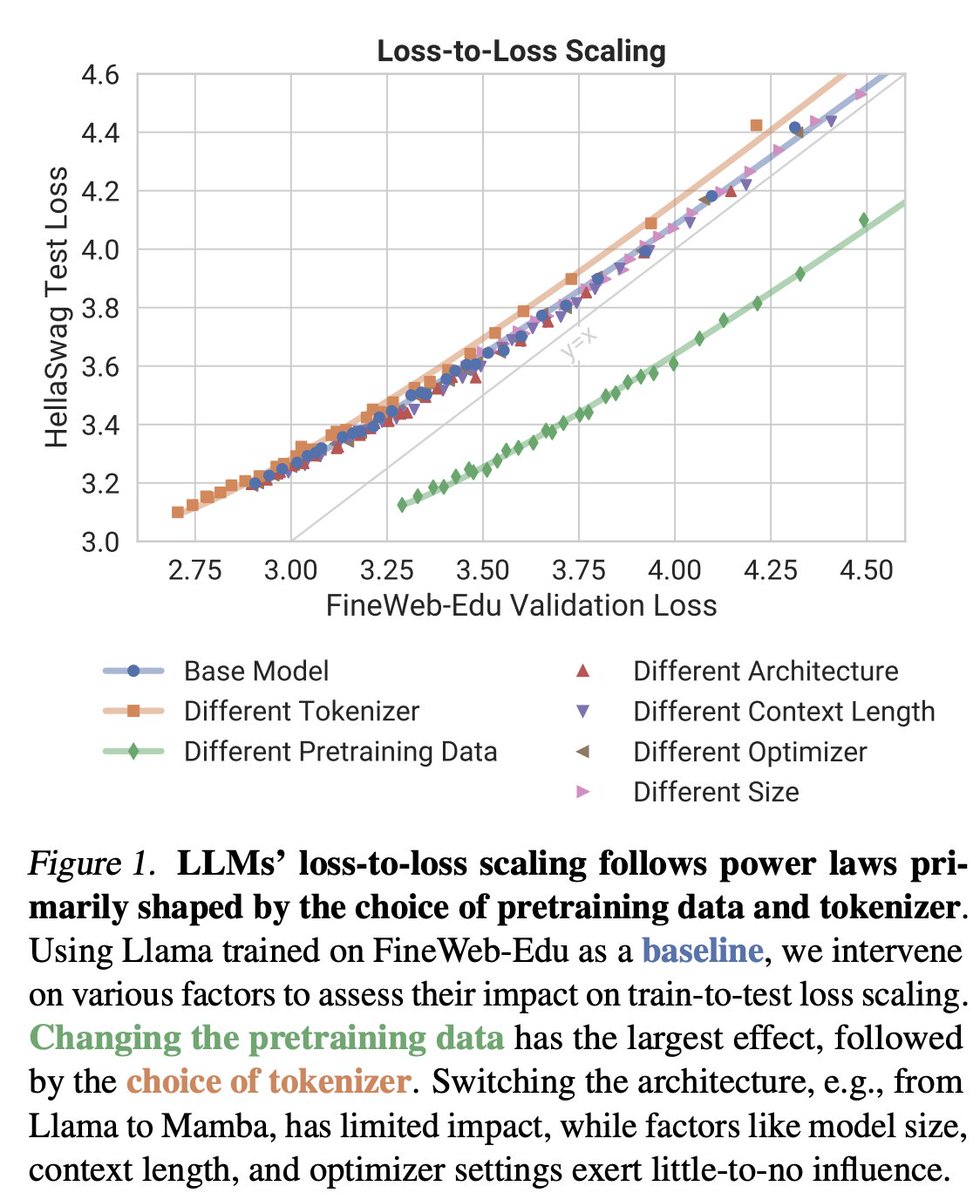
New preprint out! 🎉🎉 How does LLM training loss translate to downstream performance? We show that pretraining data and tokenizer shape loss-to-loss scaling laws, while architecture and other factors play a surprisingly minor role! brendel-group.github.io/llm-line/ 🧵1/8
“Aha moments” can be observed at step 0, so we should not fixate on reporting individual instances. Instead, we should seek reliable measures of internal reasoning that can be tracked throughout training. So far, response length appears to be one such (imperfect) measure.

Self-reflection is not unique to “reasoning models” or to newer models. Here are some self-reflections produced by Llama 2 7B Chat, **WITHOUT** any RL fine-tuning.



Does reinforcement learning with verifiable rewards work only for recent model families? It turns out that GRPO also works very well for Llama 2 7B, with an impressive +15 accuracy point increase in GSM8K. GRPO over GSM8K train. No bells and whistles. It just works.

One important caveat is that I cannot get the response length to dramatically increase as in the R1 paper.

R1-style GRPO on Llama 3.2 1B Instruct yields +10 accuracy points on GSM8K. It just works! The train data is GSM8K train. Interestingly, supervised fine-tuning yields no performance improvements, since the dataset is tiny compared to all the math reasoning data seen by Llama 3.

R1-style GRPO on Llama 3.2 1B Instruct yields +10 accuracy points on GSM8K. It just works! The train data is GSM8K train. Interestingly, supervised fine-tuning yields no performance improvements, since the dataset is tiny compared to all the math reasoning data seen by Llama 3.

Really cool paper questioning all the 'incredible' progress we've seen recently: "after fine-tuning all models on the same amount of task data, performance per pre-training compute equalizes and newer models are no better than earlier models."
Models released after November 2023 strongly outperform earlier ones on MMLU and GSM8K. However, after fine-tuning all models on the same amount of task data, performance per pre-training compute equalizes and newer models are no better than earlier models.


























































































United States Trends
- 1. #FanCashDropPromotion 2,338 posts
- 2. #FridayVibes 5,230 posts
- 3. Good Friday 61K posts
- 4. Dizzy 7,253 posts
- 5. #PETITCOUSSIN 21.8K posts
- 6. #FridayFeeling 3,128 posts
- 7. #FursuitFriday 9,978 posts
- 8. Elise 13.6K posts
- 9. Publix 2,035 posts
- 10. Happy Friyay 1,562 posts
- 11. Munetaka Murakami 1,429 posts
- 12. Talus Labs 25.9K posts
- 13. Chase 94.1K posts
- 14. Tammy Faye 4,122 posts
- 15. $ZEC 36.8K posts
- 16. Happy N7 2,383 posts
- 17. John Wayne 1,927 posts
- 18. Sydney Sweeney 108K posts
- 19. Hochul 16.9K posts
- 20. Kehlani 20.1K posts








Something went wrong.
Something went wrong.