
คุณอาจชื่นชอบ















Open-sourcing Introspect: MIT-licensed Deep-Research for your internal data! Works with spreadsheets, databases, PDFs, and web search. Has a remarkably simple architecture – Sonnet agent armed with recursive tool calling and 3 default tools. Best for use-cases where you want to…

Launching something new today. Thought I had everything covered and could have a chill launch week. Then, found tons of bugs and this happened 🫠

Been taking Opus 4.5 for a spin. Opus 4.5 + Claude Code is super worth it for planning, but I still prefer Codex for actual coding and reliability. Opus +ves - Great at using web search to get info that it needs - Thoroughly explores the codebase - Creates fairly concise plans…

Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey. Best fully open 32B reasoning model & best 32B base model. 🧵

I like the new Codex Max – but it's extremely emotionally challenged when writing frontend copy 😅 It's also meh at design Very, very good at verifiable tasks (sp on the backend) though!
Huh, it's somehow gone to shit in the last 30 minutes. Guess they're still figuring out how to handle more traffic w/o compromising quality
Gemini Pro 3 + Antigravity is very good. Antigravity still has janky UX – but its capabilities more than make up for it. Handles major refactors and large codebases extremely well Gemini's long-context supremacy really shining through here
Gemini Pro 3 + Antigravity is very good. Antigravity still has janky UX – but its capabilities more than make up for it. Handles major refactors and large codebases extremely well Gemini's long-context supremacy really shining through here
ChatGPT has (finally) started taking credit for the thankless work it does 😅

Added `grok-4-fast` to my agentic data analysis benchmark – super cheap, super fast, super good

Haiku 4.5 hits a sweet spot for agentic data analysis workflows Super nice blend of low cost, low latency, and high quality outputs. I found it better than gpt-5. Will try to publish proper evals if I can find the time!

Haiku 4.5 hits a sweet spot for agentic data analysis workflows Super nice blend of low cost, low latency, and high quality outputs. I found it better than gpt-5. Will try to publish proper evals if I can find the time!
You're doing yourself a disservice if you still have not used Codex It worked uninterrupted for 35 mins for a super complex task - and got it right first try Quite nuts - it's already a much better programmer than me (for verifiable tasks) already.
Man OpenAI killed it this DevDay. Tons of startups will have to pivot as a result of this. "Ride the waves caused by constant churn" seems to be the only viable strategy for an early stage co moving forward 😅

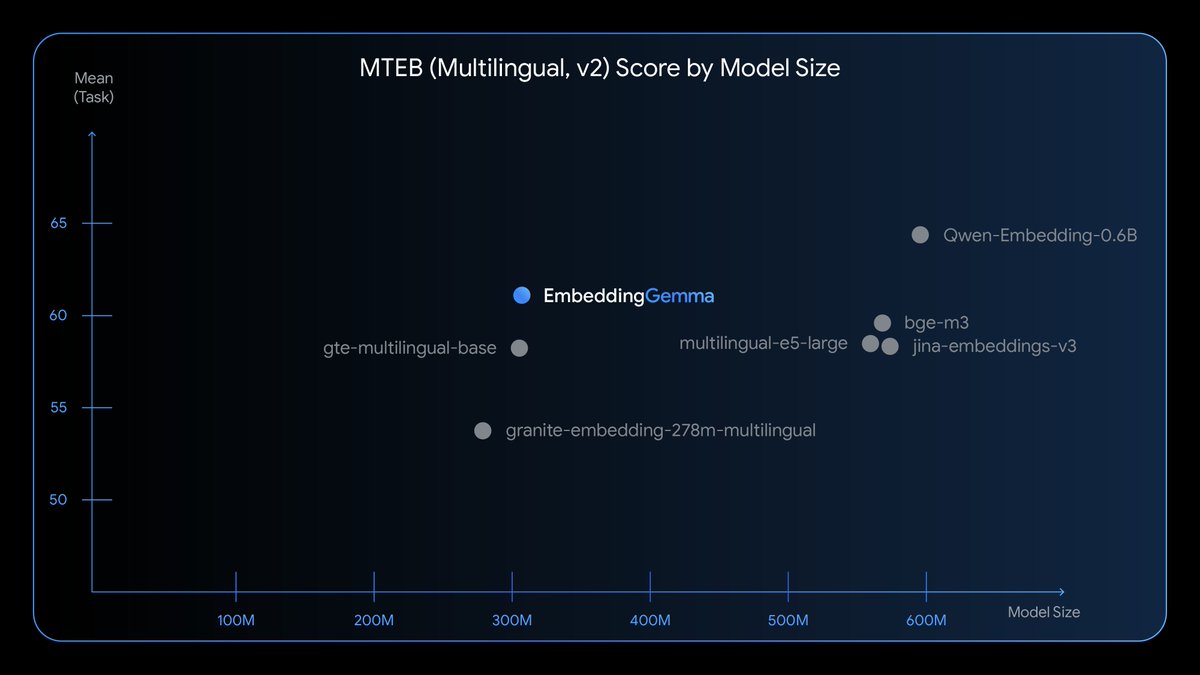
Google's on a roll. That's a lot of performance for that tiny size! I just embedded 1.4 million documents in ~80 mins on my M2 Max for free. Would've been ~$200 with the text-embedding-3-large, with worse quality.

Introducing EmbeddingGemma🎉 🔥With only 308M params, this is the top open model under 500M 🌏Trained on 100+ languages 🪆Flexible embeddings (768 to 128 dims) with Matryoshka 🤗Works with your favorite open tools 🤏Runs with as little as 200MB developers.googleblog.com/en/introducing…
Quick poll - what looks better in dark mode? First image or second image?



























































































































United States เทรนด์
- 1. #AEWDynamite 17.7K posts
- 2. Giannis 74.6K posts
- 3. Claudio 27.6K posts
- 4. #Survivor49 2,181 posts
- 5. Jamal Murray 4,084 posts
- 6. #TheChallenge41 1,503 posts
- 7. #iubb 1,109 posts
- 8. #SistasOnBET 1,781 posts
- 9. Achilles 4,864 posts
- 10. Bucks 49K posts
- 11. Kevin Knight 1,797 posts
- 12. Ryan Nembhard 2,109 posts
- 13. Tyler Herro 1,473 posts
- 14. Dark Order 1,570 posts
- 15. Jericho Sims N/A
- 16. Steve Cropper 3,750 posts
- 17. Wiggins 4,513 posts
- 18. Okada 5,576 posts
- 19. Jon Moxley 1,224 posts
- 20. Yeremi N/A
คุณอาจชื่นชอบ
-
 FactIQ
FactIQ
@tryfactiq -
 Rathin Shah
Rathin Shah
@ShahRathin -
 Hemant Mohapatra
Hemant Mohapatra
@MohapatraHemant -
 sridhar
sridhar
@RamaswmySridhar -
 Arjun Malhotra
Arjun Malhotra
@BadCapitalVC -
 Sajith Pai
Sajith Pai
@sajithpai -
 Kaushik Subramanian
Kaushik Subramanian
@TheHolyKau -
 Zekun Wang (ZenMoore) 🔥
Zekun Wang (ZenMoore) 🔥
@ZenMoore1 -
 Amal Vats
Amal Vats
@amal_vats -
 Nirant
Nirant
@NirantK -
 ashwini asokan
ashwini asokan
@LadyAshBorg -
 Mohit Kumar
Mohit Kumar
@deeppurpled -
 Manjot Pahwa
Manjot Pahwa
@manjotpahwa -
 Ajey Gore
Ajey Gore
@AjeyGore -
 Shailendra J Singh
Shailendra J Singh
@sjs_day1
Something went wrong.
Something went wrong.