

🚨This week’s top AI/ML research paper (big week!): LM/Transformers - Mixture of A Million Experts - Vision language models are blind - Learning to (Learn at Test Time) - PaliGemma - Arena Learning (WizardLM 2) - FBI-LLM (first Large bit-based LLM!) - Understanding Transformers…


ProLLM: Protein Chain-of-Thoughts Enhanced LLM for Protein-Protein Interaction Prediction - Use Protein Chain of Thought (ProCoT) to simulate signaling pathways with ProtTrans embeddings and step-by-step reasoning chains. - Convert the Mol dataset into prompt-answer pairs for…

Pseudo-perplexity in One Fell Swoop for Protein Fitness Estimation - Use ESM-2-650M embeddings from an unmasked sequence to predict masked one-at-a-time probability vectors (by MLP), reducing the need for multiple forward passes - Combine OFS pseudo-perplexity technique within an…


[CL] Vision-and-Language Navigation Today and Tomorrow: A Survey in the Era of Foundation Models arxiv.org/abs/2407.07035 - Vision-and-language navigation (VLN) is gaining increasing research attention with the rise of foundation models like BERT, GPT-3, and CLIP. This…
![fly51fly's tweet image. [CL] Vision-and-Language Navigation Today and Tomorrow: A Survey in the Era of Foundation Models
arxiv.org/abs/2407.07035
- Vision-and-language navigation (VLN) is gaining increasing research attention with the rise of foundation models like BERT, GPT-3, and CLIP. This…](https://pbs.twimg.com/media/GSZmZunWYAANc5v.jpg)
![fly51fly's tweet image. [CL] Vision-and-Language Navigation Today and Tomorrow: A Survey in the Era of Foundation Models
arxiv.org/abs/2407.07035
- Vision-and-language navigation (VLN) is gaining increasing research attention with the rise of foundation models like BERT, GPT-3, and CLIP. This…](https://pbs.twimg.com/media/GSZmZukXkAAtdo_.jpg)

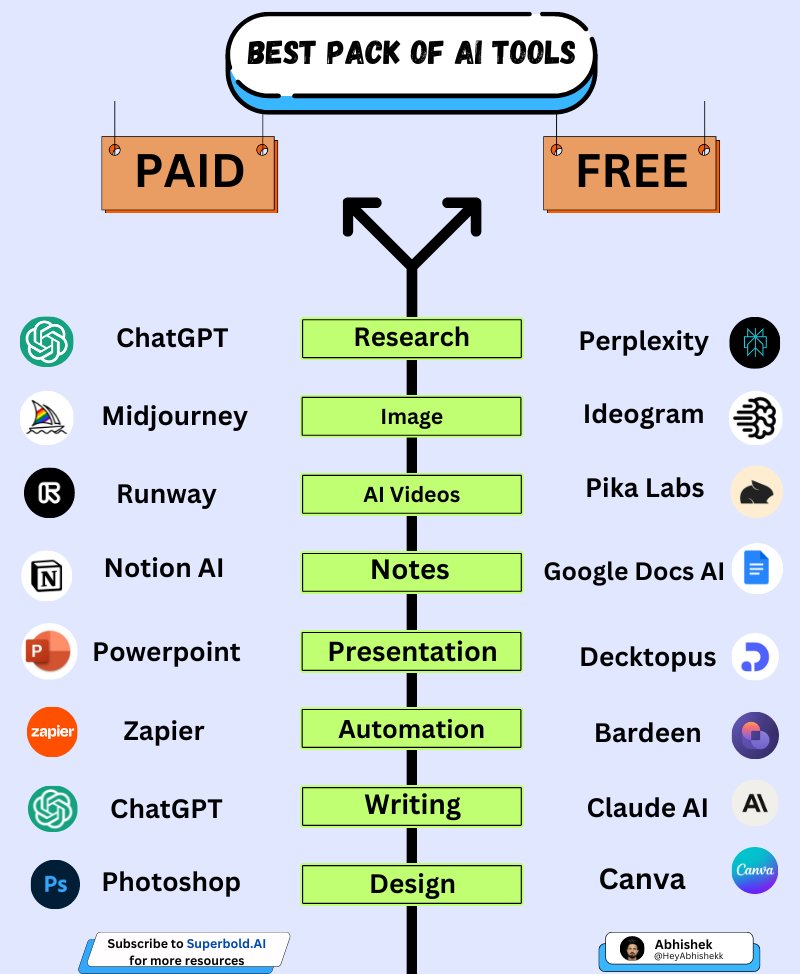
100 AI Tools to replace your tedious work: 1. Research - ChatGPT - YouChat - Abacus - Perplexity - Copilot - Gemini 2. Image - Fotor - Stability AI - Midjourney - Microsoft Designer 3. CopyWriting - Rytr - Copy AI - Writesonic - Adcreative AI 4. Writing - Jasper - HIX AI…

🚨𝐑𝐨𝐛𝐨𝐏𝐨𝐢𝐧𝐭: A Vision-Language Model for Spatial Affordance Prediction for Robotics 🌟𝐏𝐫𝐨𝐣: robo-point.github.io 🚀𝐀𝐛𝐬: arxiv.org/abs/2406.18915 introduce an automatic synthetic data generation pipeline that instruction-tunes VLMs to robotic domains and needs

Scraping web data for AI agents sucks. @firecrawl_dev is fixing that. Live demo of Firecrawl turning entire websites into LLM-ready data in seconds w/ @CalebPeffer

Cool paper proposing a graph-based agent system to enhance the long-context abilities of LLMs. It first structures long text into a graph (elements and facts) and employs an agent to explore the graph using predefined functions guided by a step-by-step rational plan. The agent…


Gemma-2 Paper is out. Shows the power of Knowledge distillation 📌 Knowledge distillation replaces next token prediction with learning from a larger teacher model's output distribution. This simulates training beyond available tokens, providing richer gradients at each step.…

🚨Towards Semantic Equivalence of Tokenization in Multimodal LLM 🌟𝐏𝐫𝐨𝐣: chocowu.github.io/SeTok-web/ 🚀𝐀𝐛𝐬: arxiv.org/abs/2406.05127 A novel Vision Tokenizer (SeTok), which groups visual features into semantic units via dynamic clustering


Gemini and Gemma are bringing back Knowledge Distillation to Language Models! Gemini and Gemma used “online” Distillation for different pre- & post-training steps. But what is it? 🤔 In Online or on-policy Knowledge Distillation, a student learns from a teacher during training…


Microsoft launched the best course on Generative AI! The free 18 lesson course is available on Github and will teach you everything you need to know to start building Generative AI applications.


One neat thing I learned from the Gemma 2 report is their use of "on policy distillation" to refine the SFT models before RLHF. The motivation is as follows: - suppose you fine-tune a student model on synthetic data from a larger, more capable teacher like GPT-4, Gemini…


🥠 Excited to introduce our latest work on Equivariant Neural Fields (ENFs)! Grounding conditioning variables in geometry 🚀 Paper: arxiv.org/abs/2406.05753 Github: github.com/dafidofff/enf-… Project Page: dafidofff.github.io/enf-jax/ Details below 👇👇


Long-form text generation with multiple stylistic and semantic constraints remains largely unexplored. We present Suri 🦙: a dataset of 20K long-form texts & LLM-generated, backtranslated instructions with complex constraints. 📎 arxiv.org/abs/2406.19371

[CL] A Closer Look into Mixture-of-Experts in Large Language Models arxiv.org/abs/2406.18219 - Experts act like fine-grained neurons. The gate embedding determines expert selection while the gate projection matrix controls neuron activation. Their heatmaps are correlated,…
![fly51fly's tweet image. [CL] A Closer Look into Mixture-of-Experts in Large Language Models
arxiv.org/abs/2406.18219
- Experts act like fine-grained neurons. The gate embedding determines expert selection while the gate projection matrix controls neuron activation. Their heatmaps are correlated,…](https://pbs.twimg.com/media/GRHMDSwakAAW-FU.jpg)
![fly51fly's tweet image. [CL] A Closer Look into Mixture-of-Experts in Large Language Models
arxiv.org/abs/2406.18219
- Experts act like fine-grained neurons. The gate embedding determines expert selection while the gate projection matrix controls neuron activation. Their heatmaps are correlated,…](https://pbs.twimg.com/media/GRHMDSuboAA5XG5.jpg)
![fly51fly's tweet image. [CL] A Closer Look into Mixture-of-Experts in Large Language Models
arxiv.org/abs/2406.18219
- Experts act like fine-grained neurons. The gate embedding determines expert selection while the gate projection matrix controls neuron activation. Their heatmaps are correlated,…](https://pbs.twimg.com/media/GRHMDSva8AA0ZFM.jpg)

Do NLP benchmark measurements provide meaningful insights about the evaluated models? How valid are these measurements? To help practitioners answer these questions, we introduce ECBD - a conceptual framework that formalizes the process of benchmark design 🧵. #ACL2024 #NLProc


Our latest work, "LLMs Assist NLP Researchers," analyzes LLMs as i) paper reviewers and ii) area chairs. Both quantitative and qualitative comparisons show that LLMs are still far from satisfactory in these expertise-demanding roles. Link: arxiv.org/pdf/2406.16253 👏


A collection of our recent work on "LLM agents + X". We are trying to use agents to help research in other domains. We are new and still learning new stuff.


Curious about making big FFNs in Transformers more efficient? 🧠 We explored training structured matrices up to 1.3B models and found they work well in pre-training too! 🚀 They’re more efficient and have steeper scaling curves, aiding in better architecture design! 🧵1/9




![perceptron17's profile picture. Designing apparel for the machine age. Interests: [AI] [ML] [Neuroscience]
.
Find us on facebook:
https://t.co/X252qUdFod](https://pbs.twimg.com/profile_images/817439087800020997/QRYer6Jn.jpg)

















































United States Trends
- 1. $APDN $0.20 Applied DNA N/A
- 2. $SENS $0.70 Senseonics CGM N/A
- 3. $LMT $450.50 Lockheed F-35 N/A
- 4. Good Friday 36.7K posts
- 5. #CARTMANCOIN 1,979 posts
- 6. yeonjun 276K posts
- 7. Broncos 68.4K posts
- 8. Raiders 67.1K posts
- 9. Blockchain 200K posts
- 10. #FridayVibes 2,608 posts
- 11. #iQIYIiJOYTH2026 1.48M posts
- 12. Bo Nix 18.8K posts
- 13. Geno 19.6K posts
- 14. Tammy Faye 1,817 posts
- 15. Kehlani 12K posts
- 16. daniela 57.8K posts
- 17. MIND-BLOWING 22.8K posts
- 18. #Pluribus 3,204 posts
- 19. John Wayne 1,151 posts
- 20. Danny Brown 3,379 posts
Something went wrong.
Something went wrong.