
Saurabh Singh
@saurasingh
Research Scientist @ Poetiq, Ex-Google DeepMind
You might like















Peek into our groundbreaking results -- this is what takeoff looks like 🚀.

Is more intelligence always more expensive? Not necessarily. Introducing Poetiq. We’ve established a new SOTA and Pareto frontier on @arcprize using Gemini 3 and GPT-5.1.

Poetiq + Gemini 3 = New Global SOTA. We just broke the ARC-AGI benchmarks (and the cost barrier) using Google's latest model. @GeminiApp
Is more intelligence always more expensive? Not necessarily. Introducing Poetiq. We’ve established a new SOTA and Pareto frontier on @arcprize using Gemini 3 and GPT-5.1.
Someone might claim Vision is a Language problem. Turn into a sequence and train Transformer from scratch 😂.


Love this analysis.

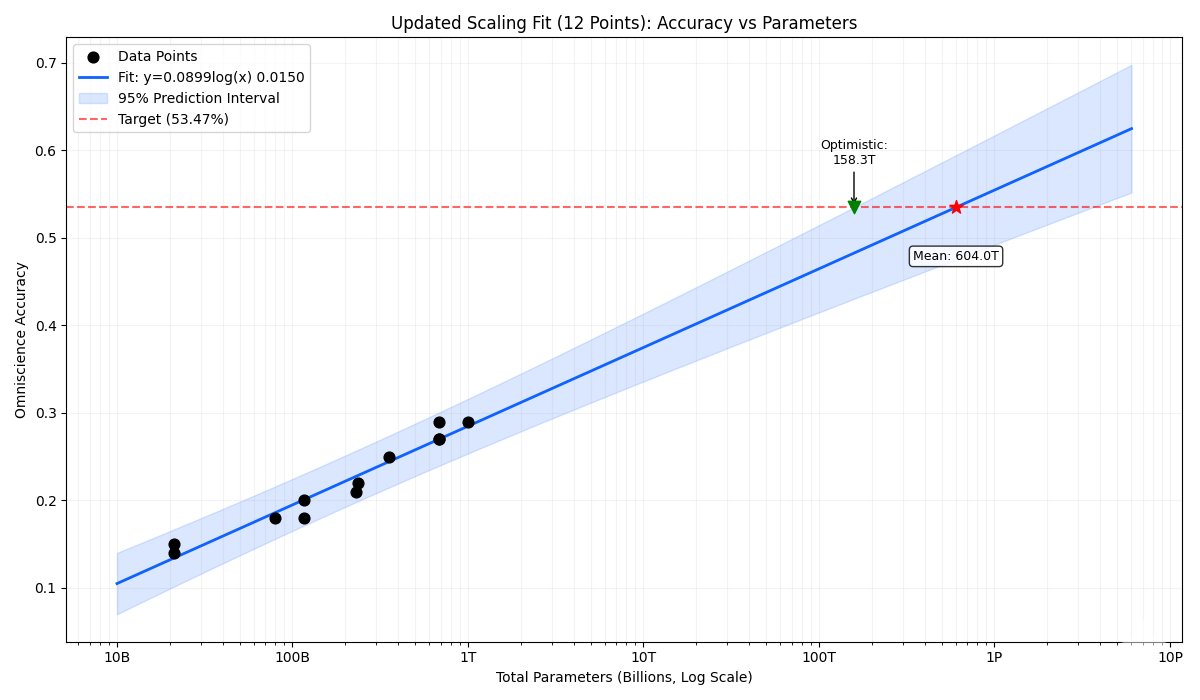
Gemini 3 Pro has around ~7.5T params (vibe-mathing with explanation) > the naive fit with with an R^2 of 0.8816 yields a mean estimation of 2.325 Quadrillion parameters > ummm, that's not it > let's only take sparse MoE reasoning models > this includes gpt-oss-20B and 120B,…



From the look of it, TRM seems to be recurrent (a function called in loop) vs. recursive (function calling itself).

For those who don't know, "Deep thinking" is a older recursive model from 2021. I suspect that "Gemini 3 Deep Think" use some TRM-style recursion.
These are amazing results from Gemini 3 on the ARC-2 challenge.

After we got early access to Gemini 3 Pro, it was SOTA, we were impressed and then Google told us, "there's one more thing..." Deep Think sets the new high water mark on ARC-AGI-2
I think diffusion should be done in latent space. A very simple and principled (upper bound on likelihood) training objective is described here, with all the math worked out for anyone interested. No need to be discreet, we can just assume continuous latents.…

Just found the dLLM library to create Diffusion Language Models It's still early but it's insanely fun to experiment with diffusion (training, inference, eval) dLLM has the potential of becoming the main library for diffusion LLMs
Actually, it's called a model.

All the great breakthroughs in science are, at their core, compression. They take a complex mess of observations and say, "it's all just this simple rule". Symbolic compression, specifically. Because the rule is always symbolic -- usually expressed as mathematical equations. If…

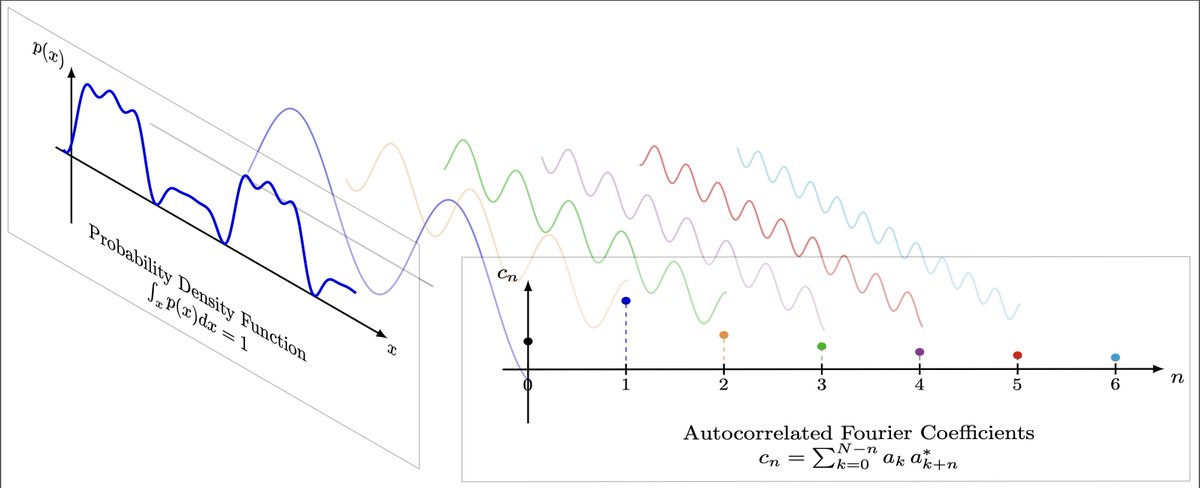
LLMs are powerful sequence modeling tools! They not only can generate language, but also actions for playing video games, or numerical values for forecasting time series. Can we help LLMs better model these continuous "tokens"? Our answer: Fourier series! Let me explain… 🧵(1/n)
Congrats to all the best paper award winners at ICML, no doubt lot of hard work went into it. However, some of these papers clearly can't be reproduced, due to missing details etc. Didn't realize that is not necessary anymore (to be best).

Happy to announce our paper ‘Fourier Basis Density Model’, joint work with @saurasingh and Johannes Ballé, won Best Paper Award at Picture Coding Symposium (PCS 2024)🏅 arxiv.org/abs/2402.15345
Can we use Fourier series to model univariate PDFs? (esp. useful in neural compression) We introduce a lightweight, flexible, and end-to-end trainable Fourier basis density model. w/ @saurasingh Johannes Ballé Paper: arxiv.org/abs/2402.15345 Code: github.com/google/codex
Pleased to announce that the GPV-1 paper will be presented as an Oral at #CVPR2022. An updated version of the paper that conveys the key ideas much more clearly is now available on arxiv arxiv.org/abs/2104.00743 #GeneralPurposeVision #GPV @allen_ai
Excited to share snippets from our latest video explaining the ideas behind "General Purpose Vision" Video: youtu.be/ok2-Y58PGAY Paper, code & demo: prior.allenai.org/projects/gpv Work done with collaborators @kamath_amita @anikembhavi @HoiemDerek @allen_ai @IllinoisCS 🧵


An excellent implementation of keepalive loop.



Very excited about the renewed focus on iterative refinement as a powerful tool for generative modelling! Here are a few relevant ICLR 2021 submissions: (image credit: github.com/ermongroup/ncsn) (1/3)

Our group just released an arXiv paper that reviews Nonlinear Transform Coding approaches. We hope this will make the development of new end-to-end neural/learned compression methods easier to understand for those new to the field. arxiv.org/abs/2007.03034


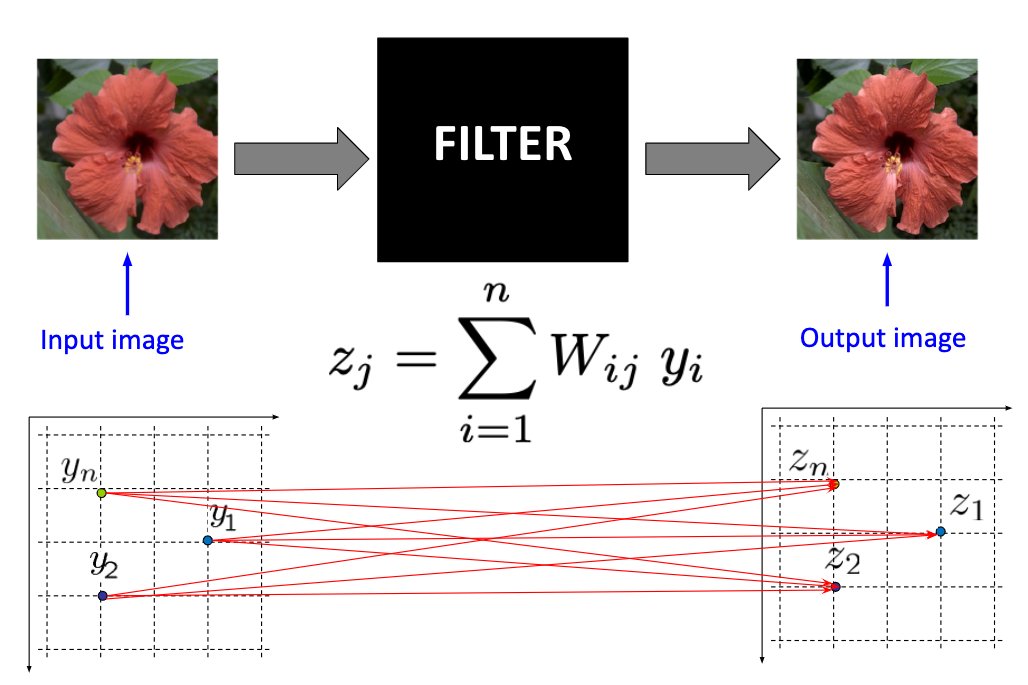
1/8 What does it mean to filter an image (or signal)? Often we choose, or design, a set of weights and apply them to the input image. But what loss/objective function does this process optimize (if any)? Should we care?

Welcome to May. As I feared, the federal government wasted April much as it wasted February. That is a harsh assessment given how much the country has been suffering. But without competent federal leadership, the best we are managing is to tread water. Some stats:





















































































United States Trends
- 1. Chiefs 47.8K posts
- 2. Mahomes 11.3K posts
- 3. Colts 20.5K posts
- 4. Steelers 34.8K posts
- 5. Caleb 29.7K posts
- 6. Jameis 8,893 posts
- 7. Lamar 17.5K posts
- 8. Drake Maye 7,134 posts
- 9. Flacco 3,582 posts
- 10. #GoPackGo 3,383 posts
- 11. #HereWeGo 4,150 posts
- 12. DJ Moore 1,492 posts
- 13. Marcus Jones 1,735 posts
- 14. #Bears 5,087 posts
- 15. #Skol 2,007 posts
- 16. Micah Parsons N/A
- 17. #OnePride 2,139 posts
- 18. Daniel Jones 1,678 posts
- 19. Tony Romo 1,673 posts
- 20. Jaxon Smith 1,928 posts
You might like
-
 Shivangi
Shivangi
@shivangi2201 -
 Tanmay Gupta
Tanmay Gupta
@tanmay2099 -
 Alex Schwing
Alex Schwing
@alexschwing -
 Ricky T. Q. Chen
Ricky T. Q. Chen
@RickyTQChen -
 Jacob Buckman
Jacob Buckman
@jacobmbuckman -
 nic lane
nic lane
@niclane7 -
 Kiana Ehsani
Kiana Ehsani
@ehsanik -
 Hongxu (Danny) Yin
Hongxu (Danny) Yin
@yin_hongxu -
 Sean Welleck
Sean Welleck
@wellecks -
 Shenlong Wang
Shenlong Wang
@ShenlongWang -
 Edgar Dobriban
Edgar Dobriban
@EdgarDobriban -
 Koutilya PNVR
Koutilya PNVR
@koutilya40192 -
 Jiasen Lu
Jiasen Lu
@jiasenlu -
 Priyank Jaini
Priyank Jaini
@priyankjaini -
 Aditi Khandelwal
Aditi Khandelwal
@Aditi184
Something went wrong.
Something went wrong.