
Shenghao Yang
@shenghao_yang
PhD student @UWCheritonCS. Machine learning and optimization over graphs. http://opallab.ca
Vous pourriez aimer
















🎉 Huge congratulations to PhD student Peihao Wang (@peihao_wang ) on two major honors: 🏆 2025 Google PhD Fellowship in Machine Learning & ML Foundations 🌟 Stanford Rising Star in Data Science Incredibly proud of Peihao's outstanding achievements! 🔶⚡

Positional Attention is accepted at ICML 2025! Thanks to all co-authors for the hard work (64 pages). If you’d like to read the paper, check the quoted post. That's a comprehensive study on the expressivity for parallel algorithms, their in- and out-of-distribution learnability,…
Positional Attention: Expressivity and Learnability of Algorithmic Computation (v2) We study the effect of using only fixed positional encodings (referred to as positional attention) in the Transformer architecture for computational tasks. These positional encodings remain the…



Our new work Spectral Journey arxiv.org/abs/2502.08794 shows a surprising finding: when a 2-layer Transformer is learned to predict the shortest path of a given graph, 1️⃣it first implicitly computes the spectral embedding for each edge, i.e. eigenvectors of Normalized Graph…

My PhD thesis is now available on UWspace: uwspace.uwaterloo.ca/items/291d10bc…. Thanks to my advisors @kfountou and Aukosh Jagannath for their support throughout my PhD. We introduce a statistical perspective for node classification problems. Brief details are below.

"Energy continuously flows from being concentrated, to becoming dispersed, spread out, wasted and useless." ⚡➡️🌬️ Sharing our work on the inability of softmax in Transformers to _robustly_ learn sharp functions out-of-distribution. Together w/ @cperivol_ @fedzbar & Razvan!

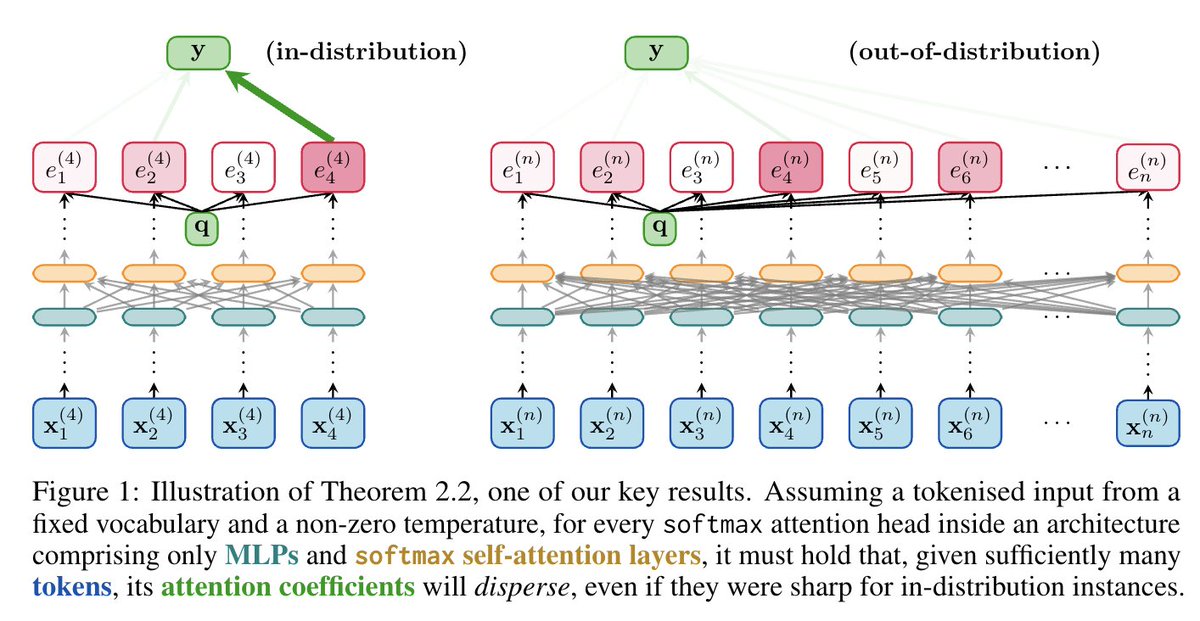
Positional Attention: Out-of-Distribution Generalization and Expressivity for Neural Algorithmic Reasoning We propose calculating the attention weights in Transformers using only fixed positional encodings (referred to as positional attention). These positional encodings remain…


I wrote a blog @Medium on "Random Data and Graph Neural Networks" Link: medium.com/@kimon.fountou… I cover a range of topics: 1. How a single averaging graph convolution changes the mean and variance of the data. 2. How it improves linear classification. 3. How multiple…

For those participating in the Complex Networks in Banking and Finance Workshop, I’ll be presenting our work on Local Graph Clustering with Noisy Labels tomorrow at 9:20 AM EDT at the Fields Institute. Hope to see you there :) arxiv.org/abs/2310.08031
Paper: Analysis of Corrected Graph Convolutions We study the performance of a vanilla graph convolution from which we remove the principal eigenvector to avoid oversmoothing. 1) We perform a spectral analysis for k rounds of corrected graph convolutions, and we provide results…

.@backdeluca is at ICLR and he will present his joint work with @shenghao_yang on "Local Graph Clustering with Noisy Labels". Date: Friday 10th of May. Time: 4:30pm - 6:30pm CEST. Place: Halle B #175.


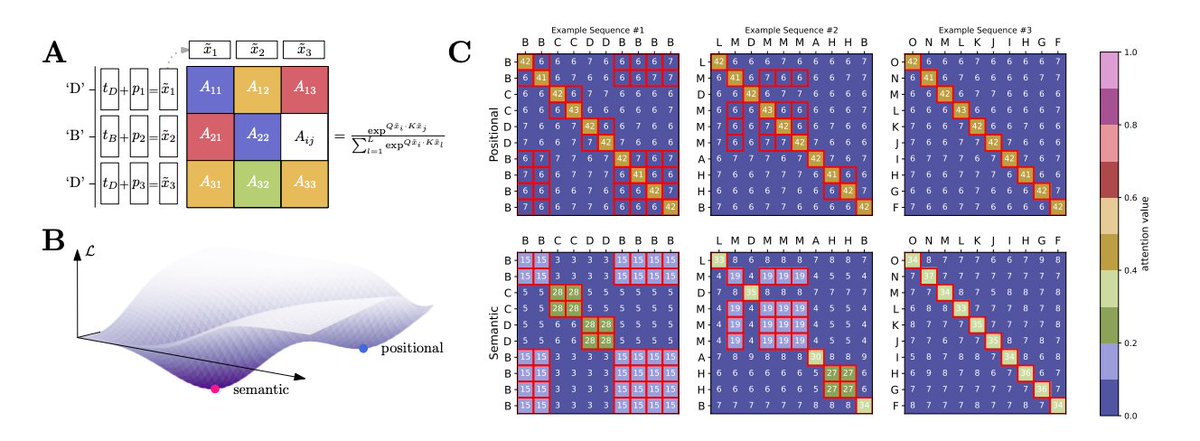
Emergence in LLMs is a mystery. Emergence in physics is linked to phase transitions. We identify a phase transition between semantic and positional learning in a toy model of dot-product attention. Very excited about this one! arxiv.org/pdf/2402.03902…

The November issue of SIAM News is now available! In this month's edition, @n_veldt finds that even a seemingly minor generalization of the standard #hypergraph cut penalty yields a rich space of theoretical questions and #complexity results. Check it out! sinews.siam.org/Details-Page/g…

Graph Attention Retrospective is live at JMLR jmlr.org/papers/v24/22-…. The revised version has additional results: 1) Beyond perfect node classification, we provide a positive result on graph attention’s robustness against structural noise in the graph. In particular, our…
New paper "Graph Attention Retrospective". One of the most popular type of models is graph attention networks. These models were introduced to allow a node to aggregate information from the features of neighbor nodes in a non-uniform way arxiv.org/abs/2202.13060

Here's our new work on the optimality of message-passing architectures for node classification on sparse feature-decorated graphs! Thanks to my advisors and co-authors @kfountou and Aukosh Jagannath. Details within the quoted tweet.
Paper: Optimality of Message-Passing Architectures for Sparse Graphs. Work by @aseemrb. arXiv link: arxiv.org/abs/2305.10391. I have been teaching a graduate course on graph neural networks this year. Close to the end of the course, many students noticed that all proposed…

Alright, I have some important news (at least for me). Now there exists an accelerated personalized PageRank method which is strongly local!! It's running time does not depend on the size of the graph but rather only on the number of nonzeros at uwspace.uwaterloo.ca/handle/10012/1……


SIAM Conference on Applied and Computational Discrete Algorithms (ACDA23) May 31 – June 2, 2023 Seattle, Washington, U.S. New submission due dates: Registering a submission: Jan 16; Paper submission deadline; Jan 23.
SIAM Conference on Applied and Computational Discrete Algorithms (ACDA23), May 31 -- June 2, 2023 siam.org/conferences/cm… Important dates: Short Abstract and Submission Registration: Jan 9, 2023 Papers and Presentations-without-papers: Jan 16, 2023 #SIAMACDA23
Open problem: accelerated methods for l1-regularized PageRank. proceedings.mlr.press/v178/open-prob…

Does it matter where you place the graph convolutions (GCs) in a deep network? How much better is a deep GCN vs an MLP? When are 2 or 3 GCs better than 1 GC? We answer those for node class., and a nonlinearly separable contextual stochastic block model. arxiv.org/pdf/2204.09297….



New video with Prof. @kfountou explaining his paper "Graph Attention Retrospective" is now available! youtu.be/duWVNO8_sDM Check it out to learn what GATs can and cannot learn for node classification in a stochastic block model setting!

youtube.com
YouTube
Graph Attention Retrospective | Kimon Fountoulakis























































































United States Tendances
- 1. LeBron 77.9K posts
- 2. #DWTS 52.9K posts
- 3. #LakeShow 3,776 posts
- 4. Whitney 15.9K posts
- 5. Peggy 18.1K posts
- 6. Reaves 7,963 posts
- 7. Keyonte George 1,846 posts
- 8. Celebrini 4,703 posts
- 9. Orioles 6,897 posts
- 10. Jazz 26.7K posts
- 11. Elaine 17.3K posts
- 12. Grayson 6,952 posts
- 13. Taylor Ward 3,497 posts
- 14. #TheFutureIsTeal 1,504 posts
- 15. Dylan 24.6K posts
- 16. #Lakers 1,582 posts
- 17. Tatum 16K posts
- 18. tDUSD N/A
- 19. Angels 32.3K posts
- 20. #WWENXT 16.9K posts
Vous pourriez aimer
-
 Zhaocheng Zhu
Zhaocheng Zhu
@zhu_zhaocheng -
 Kasper Green Larsen
Kasper Green Larsen
@kasperglarsen -
 Rishabh Agarwal
Rishabh Agarwal
@agarwl_ -
 Nan Jiang
Nan Jiang
@nanjiang_cs -
 Kimon Fountoulakis
Kimon Fountoulakis
@kfountou -
 Ben Eysenbach
Ben Eysenbach
@ben_eysenbach -
 Hejie Cui
Hejie Cui
@HennyJieCC -
 Joey Bose
Joey Bose
@bose_joey -
 Yuge Shi (Jimmy)
Yuge Shi (Jimmy)
@YugeTen -
 Sadhika Malladi
Sadhika Malladi
@SadhikaMalladi -
 Jiaqi Ma
Jiaqi Ma
@Jiaqi_Ma_ -
 Mathilde Papillon🦋 mathildepapillon .bsky .social
Mathilde Papillon🦋 mathildepapillon .bsky .social
@mathildepapillo -
 Dominique Beaini
Dominique Beaini
@dom_beaini -
 Elio (Keqiang) Yan
Elio (Keqiang) Yan
@KeqiangY -
 Moein Shariatnia
Moein Shariatnia
@MoeinShariatnia
Something went wrong.
Something went wrong.