
You might like















Just signed up for the #1 Terminal Bench coding agent by @openblocklabs: waitlist.openblocklabs.com/?ref=xn3o6g5yra Check it out: x.com/openblocklabs/…
openblocklabs.com
OB-1 Coding Agent — Early Access
Experience the future of autonomous AI. OB-1 applies our reinforcement learning research to create agents that think, learn, and evolve.

Introducing OB-1: the new #1 coding agent on Terminal Bench. After a year of R&D, our agent now outperforms Codex and Claude Code. Early access is rolling out to waitlist users now.
a new post about Hierarchical Reasoning, Energy Based Transformers and Streaming Deep RL medium.com/p/hierarchical…

I converted one of my favorite talks I've given over the past year into a blog post. "On the Tradeoffs of SSMs and Transformers" (or: tokens are bullshit) In a few days, we'll release what I believe is the next major advance for architectures.

I was just about to get into fitness, but then side tracked into vibe coding - kpe.github.io/workout-track/…
The Robust And Secure Machine Learning Podcast is here youtube.com/playlist?list=… #RobustML #SecureML #MachineLearning #DeepLearning #AdversarialML #DeepLearning #ML #AI #LLMs

BREAKING NEWS The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Physics to John J. Hopfield and Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks.”

Wow...

Ever looked at the attention operation and said "hang on, that's a one-point function!"?

Blind Vaysha is a 2016 animated short by Theodore Ushev based on a story by Georgi Gospodinov. The film tells the story of a girl who sees the past out of her left eye and the future from her right—and so is unable to live in the present. youtu.be/WxZfg-r11vU?si…

youtube.com
YouTube
Blind Vaysha | 2016 | Acclaimed Animated Short Film | Theodore Ushev

I'm really excited about these results for many reasons, but the most important is that we're starting to connect mechanistic interpretability to questions about the safety of large language models.

New Anthropic research paper: Scaling Monosemanticity. The first ever detailed look inside a leading large language model. Read the blog post here: anthropic.com/research/mappi…


AlphaMath Almost Zero Enhances LLMs with Monte Carlo Tree Search (MCTS) to improve mathematical reasoning capabilities. The MCTS framework extends the LLM to achieve a more effective balance between exploration and exploitation. For this work, the idea is to generate…


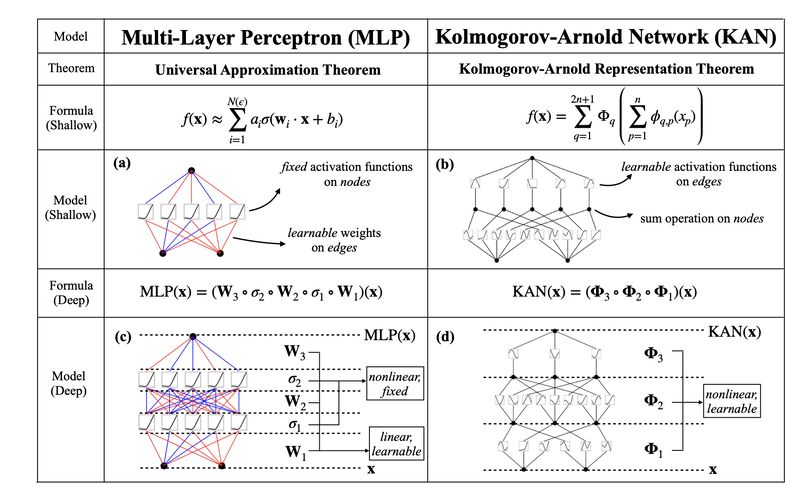
All you need is Kolmogorov–Arnold Network! 🔥🔥🔥 complete with GitHub repo 🚀🚀🚀🚀🚀 'KAN: Kolmogorov–Arnold Networks' from @MIT and @Caltech h/t @illumattnati

It's been a wild ride. Just 20 of us, burning through thousands of H100s over the past months, we're glad to finally share this with the world! 💪 One of the goals we’ve had when starting Reka was to build cool innovative models at the frontier. Reaching GPT-4/Opus level was a…

Meet Reka Core, our best and most capable multimodal language model yet. 🔮 It’s been a busy few months training this model and we are glad to finally ship it! 💪 Core has a lot of capabilities, and one of them is understanding video --- let’s see what Core thinks of the 3 body…

Silly AI regulation hype One cannot regulate AI research, just like one cannot regulate math. One can regulate applications of AI in finance, cars, healthcare. Such fields already have continually adapting regulatory frameworks in place. Don’t stifle the open-source movement!…
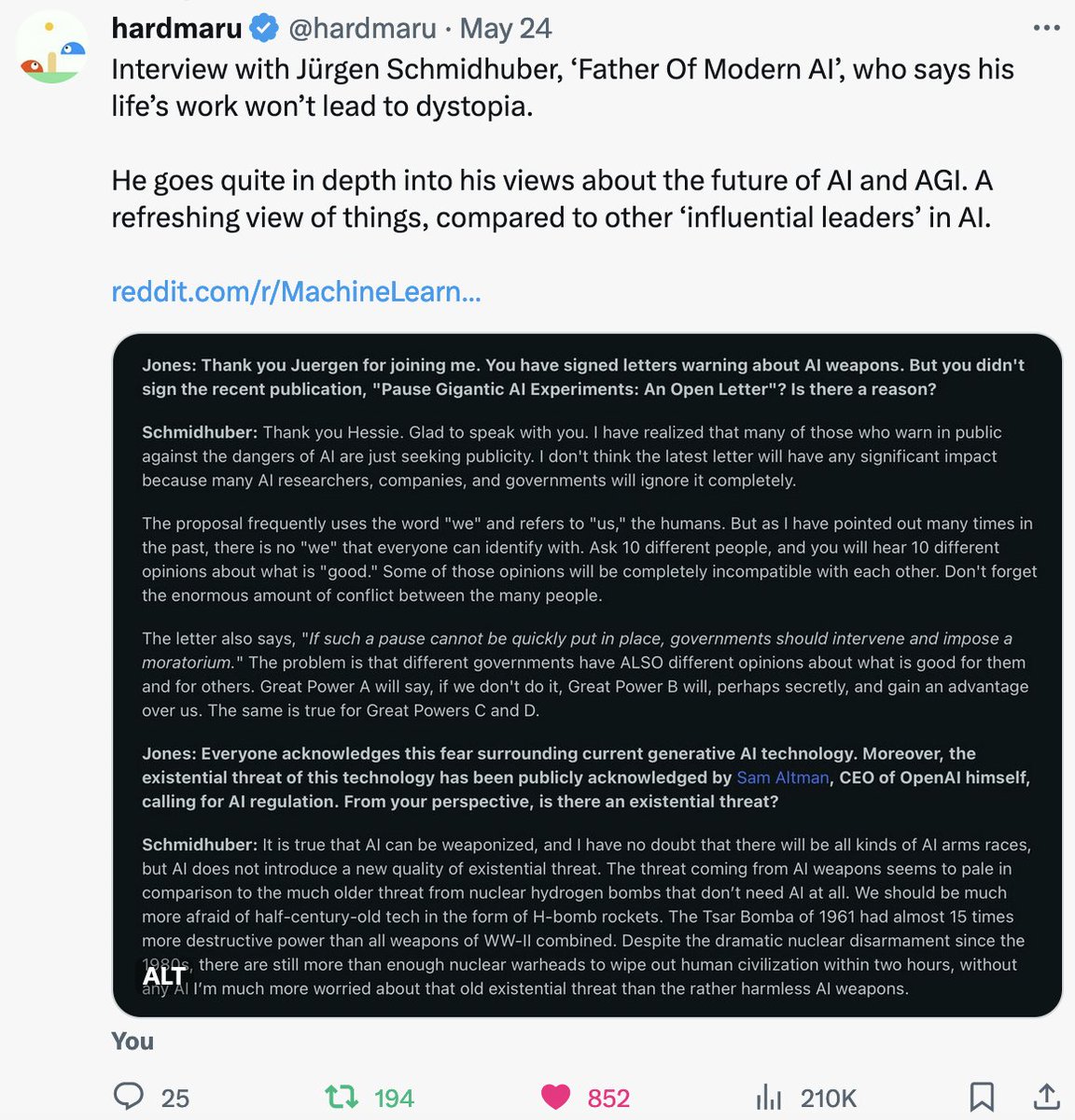

I hear a lot of folks in our AI community complain about openAI -- they don't publish, don't release models, maximum-for-profit, etc., so they are more like closedAI rather than openAI. This is true, but you have to give it to those guys -- they showed the true potential of LLMs…

Inspired by a book cover in 1972 ... half a century later I think I finally understand the Second Law ... and today published my own book about it. amazon.com/Second-Law-Res…

Every single new @HazyResearch blog post and arXiv paper is a new delight. hazyresearch.stanford.edu/blog/2023-07-2…

'It is our responsibility as scientists ... to teach how doubt is not to be feared but welcomed and discussed' -Richard Feynman


Announcing FlashAttention-2! We released FlashAttention a year ago, making attn 2-4 faster and is now widely used in most LLM libraries. Recently I’ve been working on the next version: 2x faster than v1, 5-9x vs standard attn, reaching 225 TFLOPs/s training speed on A100. 1/
































































United States Trends
- 1. INCOGNITO 4,326 posts
- 2. Cynthia 88.9K posts
- 3. CarPlay 2,374 posts
- 4. #WorldKindnessDay 13.6K posts
- 5. Katie Couric 4,205 posts
- 6. #NXXT_EarningReport N/A
- 7. Massie 90.4K posts
- 8. Black Mirror 3,474 posts
- 9. Gabon 87.9K posts
- 10. Encyclopedia Galactica 5,520 posts
- 11. #LoveDesignEP7 139K posts
- 12. Bonhoeffer 2,461 posts
- 13. Larry Brooks 2,951 posts
- 14. Sheel N/A
- 15. RIN AOKBAB BEGIN AGAIN 138K posts
- 16. GRABFOOD LOVES LINGORM 1.02M posts
- 17. #OlandriaxReebok N/A
- 18. Tommy James N/A
- 19. #thursdayvibes 4,085 posts
- 20. Bongino 9,382 posts
You might like
-
 Cameramanbhaiya
Cameramanbhaiya
@Diwakarrajrocks -
 PHIX Photonics Assembly
PHIX Photonics Assembly
@PHIX_Photonics -
 Ishaan
Ishaan
@ishaan_jaff -
 Lawrence Paulson
Lawrence Paulson
@LawrPaulson -
 Shobith Alva
Shobith Alva
@shobith -
 vogueblackheart
vogueblackheart
@vogueblackheart -
 Ov1
Ov1
@TaoistBitcoiner -
 Jonathan Farrow
Jonathan Farrow
@farrow_jonny -
 Fran García
Fran García
@fgbernal -
 Rui Paulo Cruz
Rui Paulo Cruz
@Ruicruz130 -
 webworthy
webworthy
@WebWorthy -
 Rafi (رافع)
Rafi (رافع)
@Rafi3AK -
 David Reid Clausen
David Reid Clausen
@drclausen -
 James
James
@analogwzrd -
 Flyza Floyd
Flyza Floyd
@_letat
Something went wrong.
Something went wrong.