
Katrina Drozdov (Evtimova)
@stochasticdoggo
AI researcher | PhD from @NYUDataScience | Bulgarian yogurt, prime numbers, and dogs bring me joy | she/her
You might like
















After spending billions of dollars of compute, GPT-5 learned that the most effective use of its token budget is to give itself a little pep talk every time it figures something out. Maybe you should do the same.



Tinker provides an abstraction layer that is the right one for post-training R&D -- it's the infrastructure I've always wanted. I'm excited to see what people build with it. "Civilization advances by extending the number of important operations which we can perform without…

Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!…


The application for a research fellowship at the Flatiron Institute in the Center for Computational Math is now live! This includes positions for ML and stats. The deadline is Dec 1. Links below with more details.
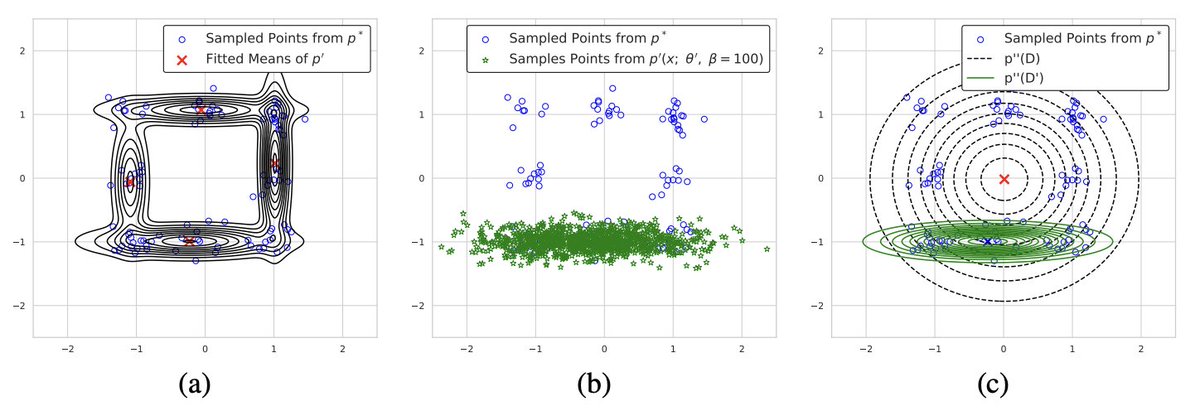
Finally dipped my toes into RL post-training. I trained a code generation LLM with GRPO using open-r1. Here are my 9 takeaways: kevtimova.github.io/posts/grpo/

This simple pytorch trick will cut in half your GPU memory use / double your batch size (for real). Instead of adding losses and then computing backward, it's better to compute the backward on each loss (which frees the computational graph). Results will be exactly identical


excited to finally share on arxiv what we've known for a while now: All Embedding Models Learn The Same Thing embeddings from different models are SO similar that we can map between them based on structure alone. without *any* paired data feels like magic, but it's real:🧵
this is sick all i'll say is that these GIFs are proof that the biggest bet of my research career is gonna pay off excited to say more soon

it's been more than a decade since KD was proposed, and i've been using it all along .. but why does it work? too many speculations but no simple explanation. @_sungmin_cha and i decided to see if we can come up with the simplest working description of KD in this work. we ended…


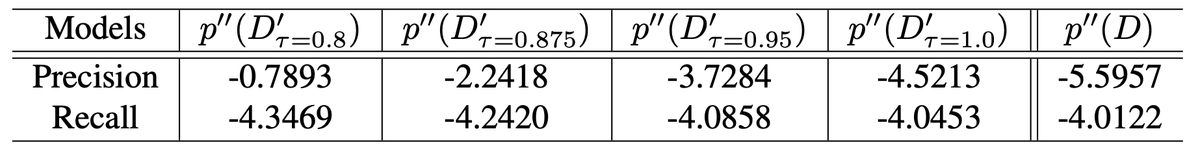

CDS PhD Vlad Sobal (@vlad_is_ai) and Courant PhD Wancong (Kevin) Zhang show that when good data is scarce, planning beats traditional reinforcement learning. With @kchonyc, @timrudner, and @ylecun. nyudatascience.medium.com/when-good-data…

We’re working on researching and designing world models. In the meantime, you definitely need RAG and FreshStack will help.

Existing IR/RAG benchmarks are unrealistic: they’re often derived from easily retrievable topics, rather than grounded in solving real user problems. 🧵Introducing 𝐅𝐫𝐞𝐬𝐡𝐒𝐭𝐚𝐜𝐤, a challenging RAG benchmark on niche, recent topics. Work done during intern @databricks 🧱

No labels. No problems. 😎 Check out the new impactful approach (TAO) from the Mosaic Research Team!

The hardest part about finetuning LLMs is that people generally don't have high-quality labeled data. Today, @databricks introduced TAO, a new finetuning method that only needs inputs, no labels necessary. Best of all, it actually beats supervised finetuning on labeled data.

Huge congratulations on the launch! @reflection_ai has an incredible team and an ambitious mission—excited to follow your progress!

Today I’m launching @reflection_ai with my friend and co-founder @real_ioannis. Our team pioneered major advances in RL and LLMs, including AlphaGo and Gemini. At Reflection, we're building superintelligent autonomous systems. Starting with autonomous coding.

Today I’m launching @reflection_ai with my friend and co-founder @real_ioannis. Our team pioneered major advances in RL and LLMs, including AlphaGo and Gemini. At Reflection, we're building superintelligent autonomous systems. Starting with autonomous coding.

I shared a controversial take the other day at an event and I decided to write it down in a longer format: I’m afraid AI won't give us a "compressed 21st century". The "compressed 21st century" comes from Dario's "Machine of Loving Grace" and if you haven’t read it, you probably…
I asked ChatGPT, Gemini, and Claude for a clever joke. They all gave me the same one. Either AI is merging into a hive mind… or humor has officially been solved mathematically!


VideoJAM is our new framework for improved motion generation from @AIatMeta We show that video generators struggle with motion because the training objective favors appearance over dynamics. VideoJAM directly adresses this **without any extra data or scaling** 👇🧵

The buzz over DeepSeek this week crystallized, for many people, a few important trends that have been happening in plain sight: (i) China is catching up to the U.S. in generative AI, with implications for the AI supply chain. (ii) Open weight models are commoditizing the…
The principle of least effort, from psychology, describes how we favor efficiency over effort. It aligns with System 1 (fast, intuitive) vs. System 2 (slow, deliberate) reasoning. AI faces a similar challenge: knowing when to rely on heuristics vs. deeper reasoning.

The recording of the GAN test of time talk by @dwf is now publicly available: neurips.cc/virtual/2024/t…

Got a diffusion model? What if there were a way to: - Get SOTA text-to-image prompt fidelity, with no extra training! - Steer continuous and discrete (e.g. text) diffusions - Beat larger models using less compute - Outperform fine-tuning - And keep your stats friends happy !?
















































































































United States Trends
- 1. #BornOfStarlightHeeseung 16.5K posts
- 2. Happy Birthday Charlie 72.8K posts
- 3. #tuesdayvibe 4,321 posts
- 4. good tuesday 36.3K posts
- 5. Sandy Hook 3,840 posts
- 6. Alex Jones 16.8K posts
- 7. Pentagon 80.5K posts
- 8. #NationalDessertDay N/A
- 9. #PortfolioDay 4,188 posts
- 10. Shilo 2,732 posts
- 11. Monad 198K posts
- 12. Dissidia 7,689 posts
- 13. Victory Tuesday 1,249 posts
- 14. Janet Mills 2,218 posts
- 15. Happy Heavenly 10.8K posts
- 16. Time Magazine 21.4K posts
- 17. Happy 32nd 11.8K posts
- 18. Standard Time 3,018 posts
- 19. Sly Cooper N/A
- 20. #PutThatInYourPipe N/A
You might like
-
 Jason Weston
Jason Weston
@jaseweston -
 Kianté Brantley (Hiring Fall25 Postdoc and PhDs)
Kianté Brantley (Hiring Fall25 Postdoc and PhDs)
@xkianteb -
 Cinjon Resnick
Cinjon Resnick
@cinjoncin -
 Jason Phang
Jason Phang
@zhansheng -
 augustus odena
augustus odena
@gstsdn -
 Mark Goldstein
Mark Goldstein
@marikgoldstein -
 Sheng Liu
Sheng Liu
@ShengLiu_ -
 Sean Welleck
Sean Welleck
@wellecks -
 Taro Makino
Taro Makino
@taromakino -
 Charles Sutton
Charles Sutton
@RandomlyWalking -
 Nan Wu
Nan Wu
@NanWu__ -
 Elman Mansimov
Elman Mansimov
@elmanmansimov -
 Nishant Subramani @ COLM 🦙
Nishant Subramani @ COLM 🦙
@nsubramani23 -
 Chhavi Yadav
Chhavi Yadav
@chhaviyadav_ -
 Will Whitney
Will Whitney
@wfwhitney
Something went wrong.
Something went wrong.