
Xinting Huang
@timhuangxt
Senior Researcher @TencentGlobal, working on LLMs. Ph.D. at @UniMelb; Ex @BytedanceTalk, @MSFTResearch
Also glad to share: We made it work for instruction following models! NH2-Mixtral-8x7B ➕ NH2-Solar-10.7B ➕and OpenChat-3.5-7B ➡️ new sota for 7B model in MT-BENCH Check it out: huggingface.co/papers/2402.16…
huggingface.co
Paper page - FuseChat: Knowledge Fusion of Chat Models
Paper page - FuseChat: Knowledge Fusion of Chat Models

Knowledge Fusion of LLMs Is it possible to merge existing models into a more potent model? We have already seen a few ways that show the potential to effectively do this using approaches like weight merging and ensembling of models. This work proposes FuseLLM with the core…


The End of Manual Decoding: Meet AutoDeco Researchers unveil AutoDeco, a groundbreaking framework that teaches LLMs to control their own decoding strategy. It dynamically predicts temperature & top-p for each token, eliminating manual tuning & enabling natural language control.


Introducing Search Self-play (SSP, arxiv.org/abs/2510.18821)! We let deep search agents act simultaneously as a task proposer and a problem solver. Through competition and cooperation, their agent capabilities co-evolve and uniformly surpass SOTA performance without supervision!




🚀 Excited to announce our 🍁Marco‑MT🍁 achieved outstanding results at #WMT2025 General Translation! 🏆 Notably, in English→Chinese it outperformed closed‑source leaders like GPT‑4.1 and Gemini 2.5 Pro. Among 13 language pairs we competed in, Maroc-MT-Algharb achieves (final…

🌺GPT-4o’s image generation is stunning — but how well does it handle complex scenarios? 🤔 We introduce 🚀CIGEVAL🚀, a novel method to evaluate models' capabilities in Conditional Image Generation 🖼️➕🖼️🟰🖼️. Find out how top models perform when conditions get truly…

These findings resonate with my impressions. AFAIC, structured prompting outperforms CoT & ICL by steering LLMs through workflows. Great to see this ‘rebuttal’ backed by such rigorous analysis — reminds me of the insights in LLMs Cannot Self-Correct. We need more like this!

Does Structured Outputs hurt LLM performance? 🤔 The paper "Let Me Speak Freely" paper claimed that it does, but new experiments by @dottxtai (team behind outlines) show it doesn’t if you do it correctly! 👀 TL;DR; 📈 The "Let Me Speak Freely" poor results came from weak…

Exciting to see our old friend continuing to push the real-world boundaries of LLM applications (shoutout to MT here)!
🔥Our LLM-powered MT (Marco-MT) has achieved massive commercial use, leading the industry in both efficiency and cost-effectiveness. 🌏 Revolutionizing translation in e-commerce and beyond! 🚀 🌍 For more details: bloomberg.com/news/videos/20… ✨ Try it now: aidc-ai.com





To Code, or Not To Code? Exploring Impact of Code in Pre-training discuss: huggingface.co/papers/2408.10… Including code in the pre-training data mixture, even for models not specifically designed for code, has become a common practice in LLMs pre-training. While there has been…

🚀Check out VideoVista, a comprehensive video-LMMs evaluation benchmark! videovista.github.io 🚀 Dive into our leaderboard: - 📊 Evaluating 33 Video-LMMs across 27 tasks; - 🥉 The latest GPT-4o-Mini clinches 3rd place; - 🏆 InternLM-XComposer-2.5 emerges as the…

🚀Check out VideoVista, our comprehensive video-LMMs evaluation benchmark! We've assessed 33 video Video-LMMs across 27 tasks. Highlights include the latest GPT-4o-Mini, ranked third, and InternLM-XComposer-2.5, the top-performing open-source model. More: videovista.github.io

Open-sourced Multimodal models -- fascinating Open-sourced MOE models -- fascinating Open-sourced Multimodal MOE models -- WOW! check this out 👇
🥳We introduce Uni-MoE, a unified multimodal LLM based on sparse MoE architecture. It integrates 📹 video, 🖼️ image, 📄 text, 🔊 audio, and 🗣️ speech, supporting 8+ experts in parallel training across mixed modalities. 🌈Paper: arxiv.org/abs/2405.11273. 💐Project (Code, Data,…




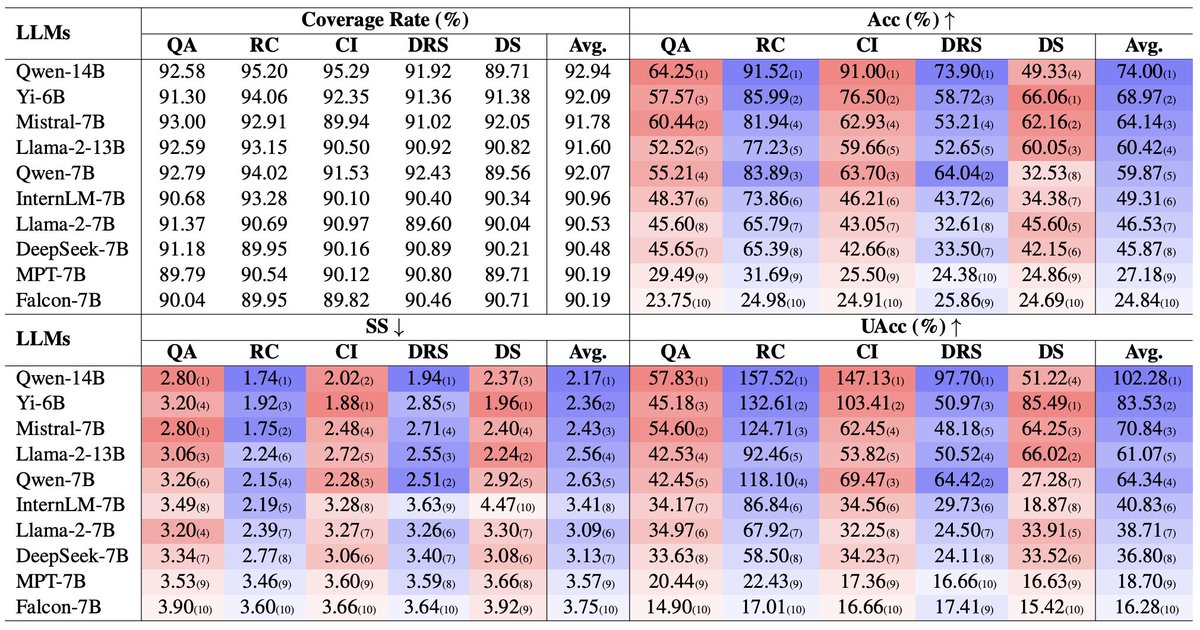
🚀 A game-changer benchmark: LLM-Uncertainty-Bench 🌟 📚 We introduce "Benchmarking LLMs via Uncertainty Quantification", which challenges the status quo in LLM evaluation. 💡 Uncertainty matters too: we propose a novel uncertainty-aware metric, which tests 8 LLMs across 5…

FuseChat Knowledge Fusion of Chat Models While training large language models (LLMs) from scratch can indeed lead to models with distinct capabilities and strengths, this approach incurs substantial costs and may lead to potential redundancy in competencies. An alternative…

















































































United States Trends
- 1. Cynthia 76.3K posts
- 2. #WorldKindnessDay 11.2K posts
- 3. GRABFOOD LOVES LINGORM 822K posts
- 4. Good Thursday 35.7K posts
- 5. Larry Brooks 1,861 posts
- 6. Tommy James N/A
- 7. RIP Brooksie 1,201 posts
- 8. Michael Burry 10.5K posts
- 9. Bonhoeffer 1,399 posts
- 10. #SwiftDay N/A
- 11. #thursdaymotivation 2,422 posts
- 12. Taylor Fritz N/A
- 13. #thursdayvibes 3,366 posts
- 14. Massie 79.4K posts
- 15. RIN AOKBAB BEGIN AGAIN 46.6K posts
- 16. #LoveDesignEP7 46.1K posts
- 17. Katie Couric 1,779 posts
- 18. Bongino 5,919 posts
- 19. Happy Friday Eve N/A
- 20. Rejoice in the Lord 2,789 posts
Something went wrong.
Something went wrong.