
vishal
@vishal_learner
Data Science/ML. http://ColBERT.ai Maintainer. #FlyEaglesFly
In 285 days, my current role as a data analyst will come to an end. I’m excited to begin my professional machine learning journey. Just published a blog post on what I’ve been building, learning, and looking for next (link below).

👀 Animals have been assigned. Scheduled to print fall 2026! We have iterated on this with over 3k students (and continue to do so). We give our students access to the full draft as part of our evals course (link in bio).

why did i not use GitHub Desktop more before. it's so much easier to wrap my head around branches and changes

almost everything is in distribution if broken in small enough steps and done in the right order.

Early next year I would love to support a symposium on the future of AI interfaces, design and adaptive intelligence. If you are a designer, UX/AI researcher, or just have opinions and want to contribute would love to have you involved. We will keep it small + invite only.

Humans learn most characteristically from reflection.

One of the most though provoking points Karpathy made during the Dwarkesh podcast is that humans learn mostly from “synthetic” self generated data, ie replaying, distilling, processing recent experience.
pre order my new book "the art and science of being friendly enough with your neighbors to have pleasant interactions when running into them but not so friendly that it makes it awkward and creates an unsustainable relational expectation"
i hope LLMs don't overly start using e.g. and i.e. because that's fundamental to how i communicate and will never change

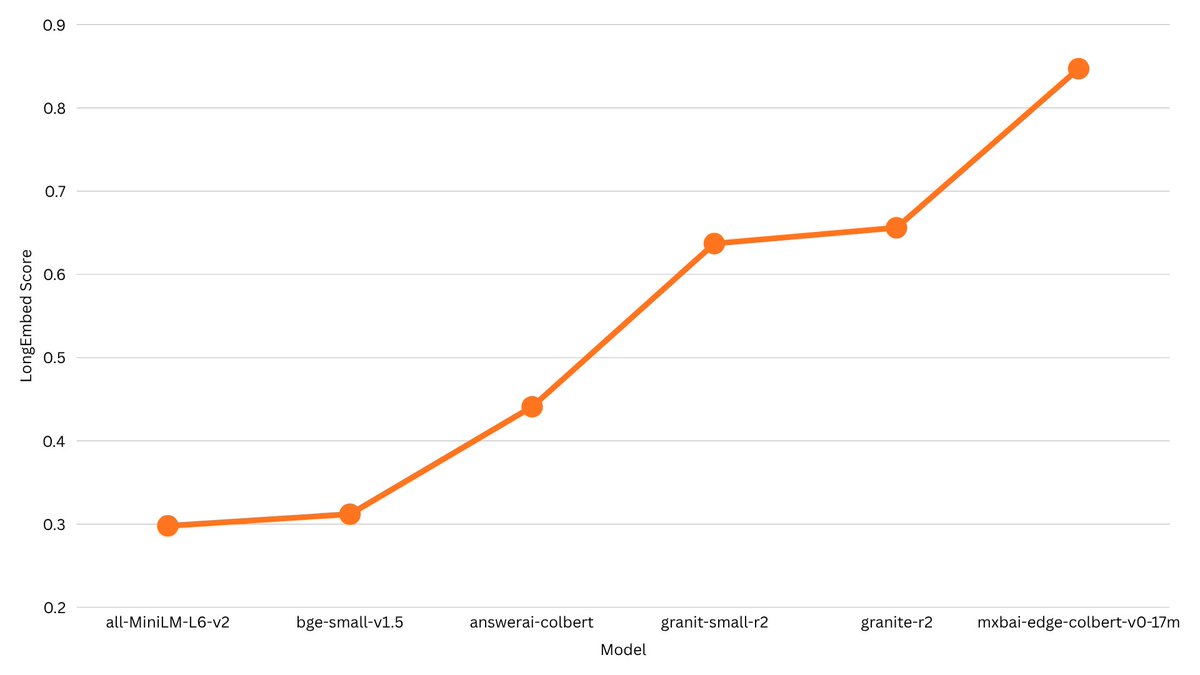
Releasing small ColBERT models as my first project @mixedbreadai!!🍞 Even the 17M model easily beats the longembed leader:) The tech report includes many easy wins for training embedding models and ColBERT models from scratch🗒️

One More (Small) Thing: Introducing mxbai-colbert-edge-v0 17M and 32M. They are are the result of an easily reproducible way to train ColBERT models from scratch. They're strong, too: the 17M variant would rank first on the LongEmbed leaderboard for models under 1B parameters.

We released a new version of PyLate, which mostly bump the version to ST 5.X and have some fixes for LLM base models/models with multiple dense layers This release focuses on making all models compatible... 😇

PyLate is getting better and better
We released a new version of PyLate, which mostly bump the version to ST 5.X and have some fixes for LLM base models/models with multiple dense layers This release focuses on making all models compatible... 😇
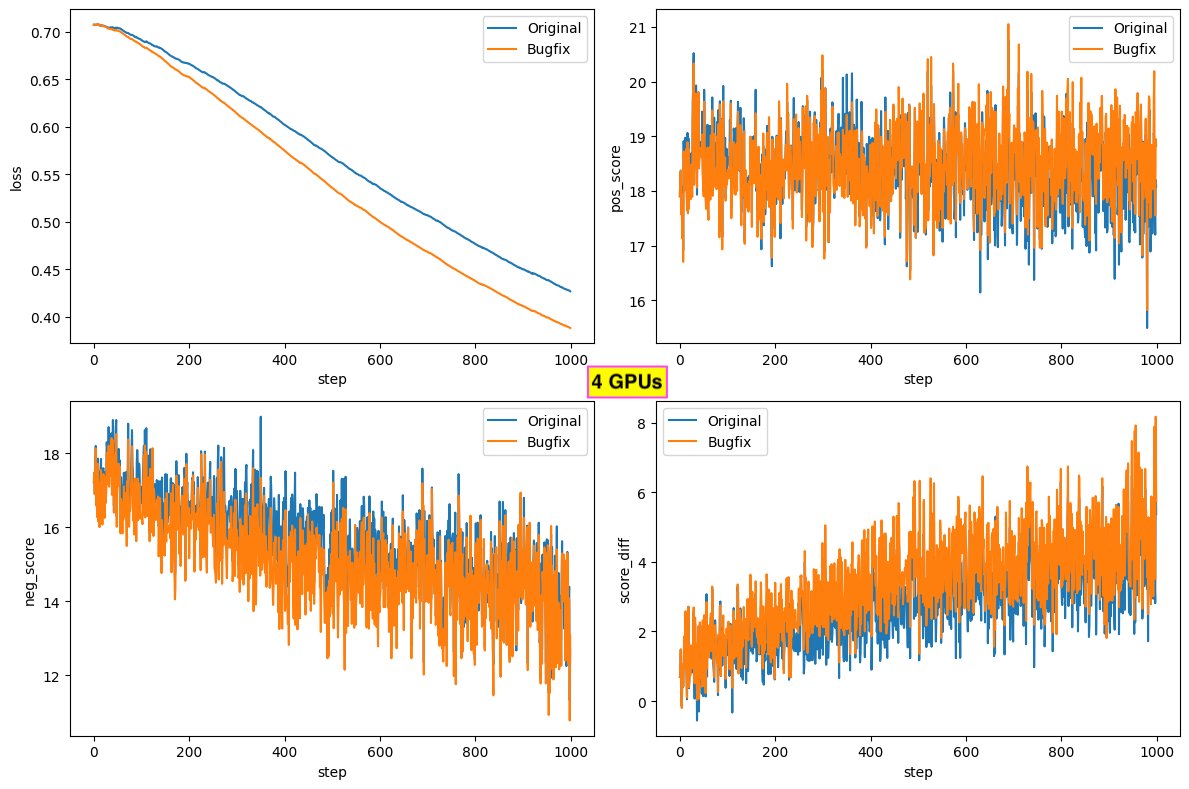
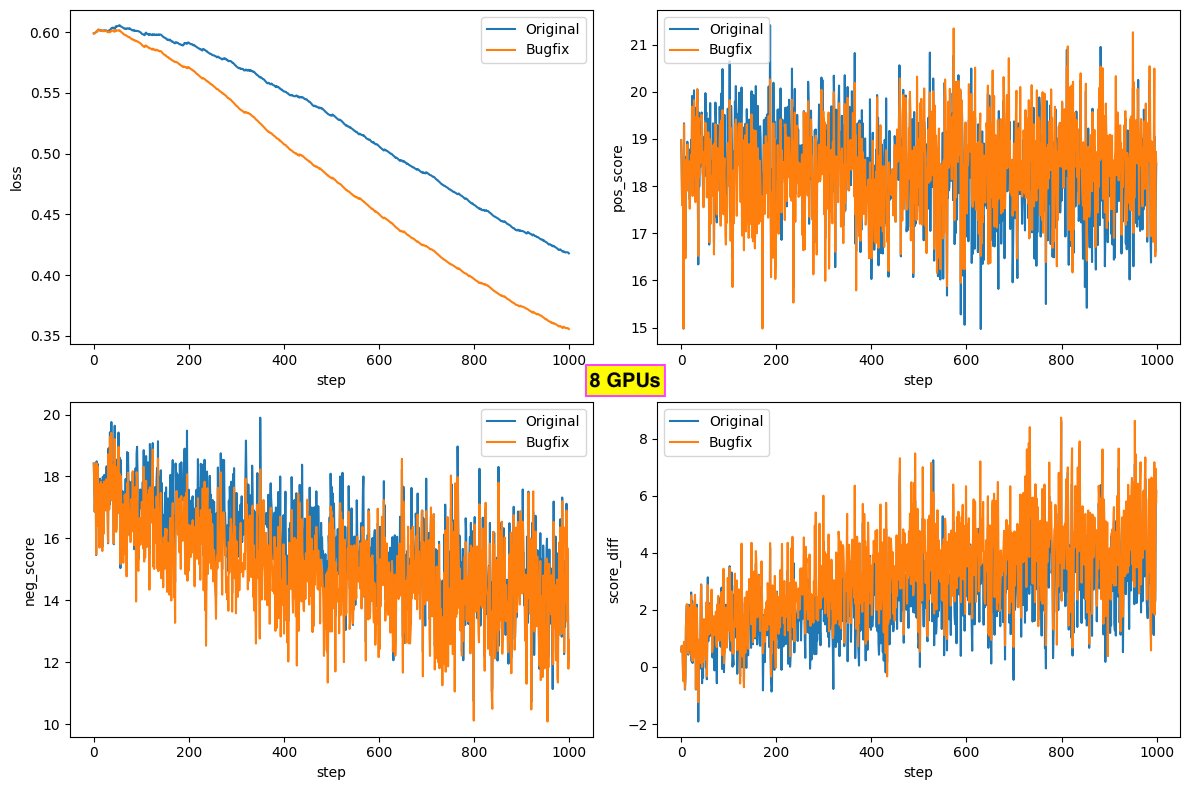
The next colbert-ai release (in 2-3 weeks, after I finish PyTorch 2.x upgrade analysis) will include a bugfix for single-node multi-GPU training (sample division across GPUs) which improves loss/pos score/neg score during training. Thanks to our ColBERT community!
I'm hiring an operations lead 🔥 If you like building things 0-1, and imagining new worlds -- join us 🌍 adaptionlabs.ai

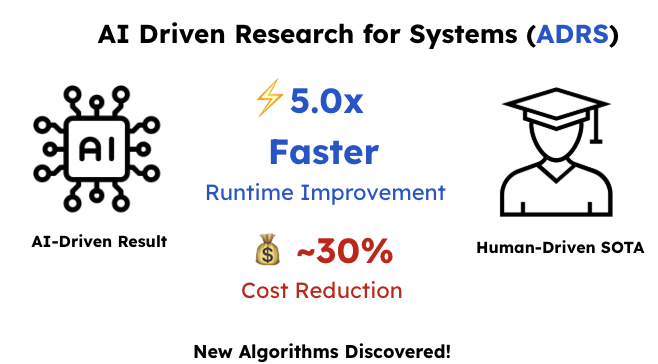
Barbarians at the Gate is a very interesting new paper, with some exciting results showing the potential for AI in systems research. But I think the authors aren't quite asking the hardest problem about where this takes systems as a field. I wrote a new blog post about it.

🚀 Excited to release our new paper: “Barbarians at the Gate: How AI is Upending Systems Research” We show how AI-Driven Research for Systems (ADRS) can rediscover or outperform human-designed algorithms across cloud scheduling, MoE expert load balancing, LLM-SQL optimization,…
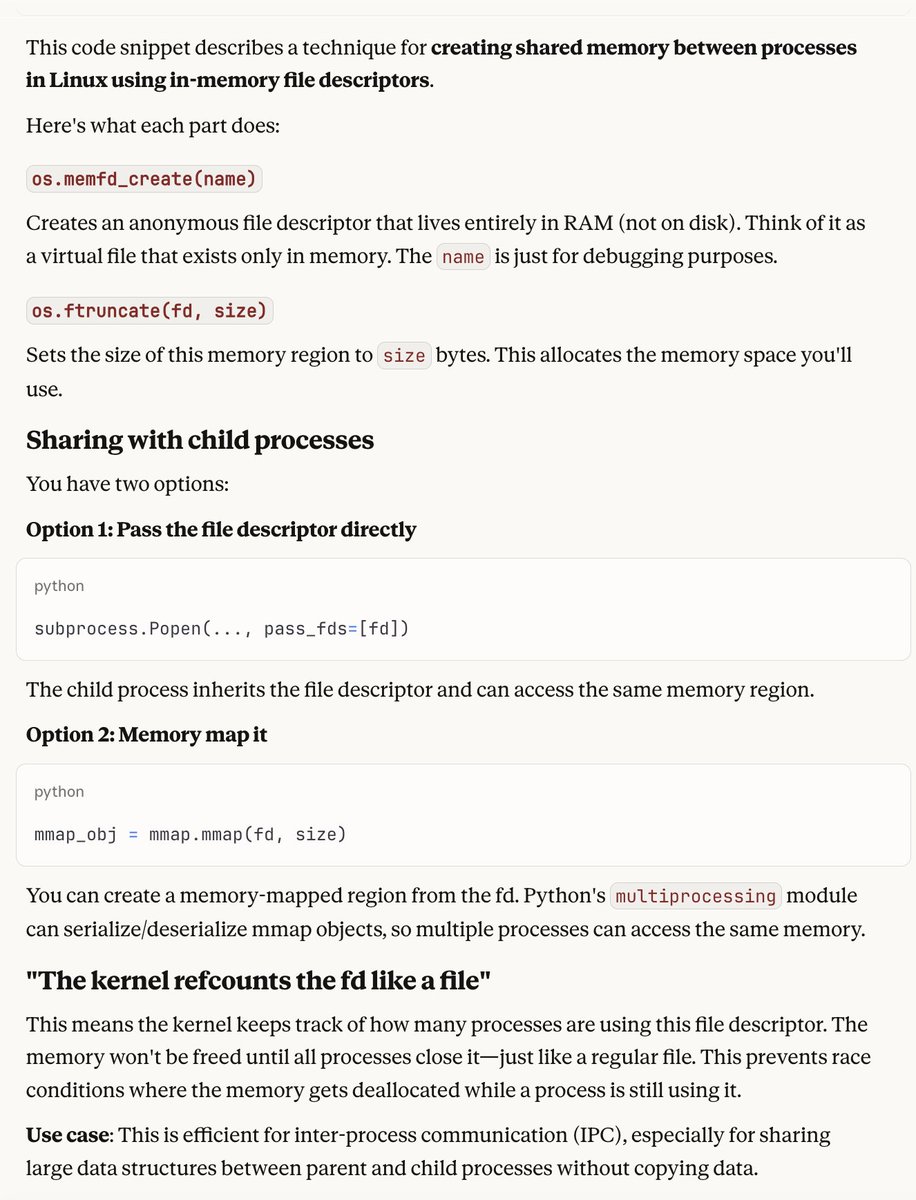

You can do something like fd = os.memfd_create(name) os.ftruncate(fd, size) and then either share fd with your child process e.g. via subprocess.Popen(pass_fds=) or you mmap it which multiprocessing can deserialize to the same region. The kernel refcounts the fd like a file.

til about memfd for sharing across python processes
You can do something like fd = os.memfd_create(name) os.ftruncate(fd, size) and then either share fd with your child process e.g. via subprocess.Popen(pass_fds=) or you mmap it which multiprocessing can deserialize to the same region. The kernel refcounts the fd like a file.

The GIL forced Python engineers into multiprocessing, adding overhead and complexity: slower startup, increased memory use, context switching, and serialization/deserialization headaches (or shared memory complexity). With PyTorch 3.14 finally removing the GIL, multithreading is…





























































































United States เทรนด์
- 1. #SpotifyWrapped 160K posts
- 2. Chris Paul 23.1K posts
- 3. Clippers 34K posts
- 4. #HappyBirthdayJin 67.2K posts
- 5. Hartline 5,028 posts
- 6. GreetEat Corp N/A
- 7. #NSD26 18.6K posts
- 8. South Florida 4,590 posts
- 9. #OurSuperMoonJin 57.5K posts
- 10. $MSFT 13.2K posts
- 11. #WorldwideHandsomeJin 55.7K posts
- 12. Good Wednesday 36.4K posts
- 13. David Corenswet 1,450 posts
- 14. Collin Klein 1,158 posts
- 15. Chris Klieman 1,132 posts
- 16. Chris Henry N/A
- 17. Hump Day 15.2K posts
- 18. Apple Music 271K posts
- 19. National Signing Day 5,820 posts
- 20. Ethan Hawke 2,137 posts
Something went wrong.
Something went wrong.