
Yifan Zhang @ NeurIPS
@yifan_zhang_
PhD student at @Princeton University, focusing on LLMs. Language Modeling and Pretraining, LLM Reasoning and RL. Prev @ Seed @UCLA @Tsinghua_IIIS
🚀DeepSeek V3.2 officially utilized our corrected KL regularization term in their training objective! On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning (arxiv.org/abs/2505.17508) See also tinker-docs.thinkingmachines.ai/losses It will be even better if they can…


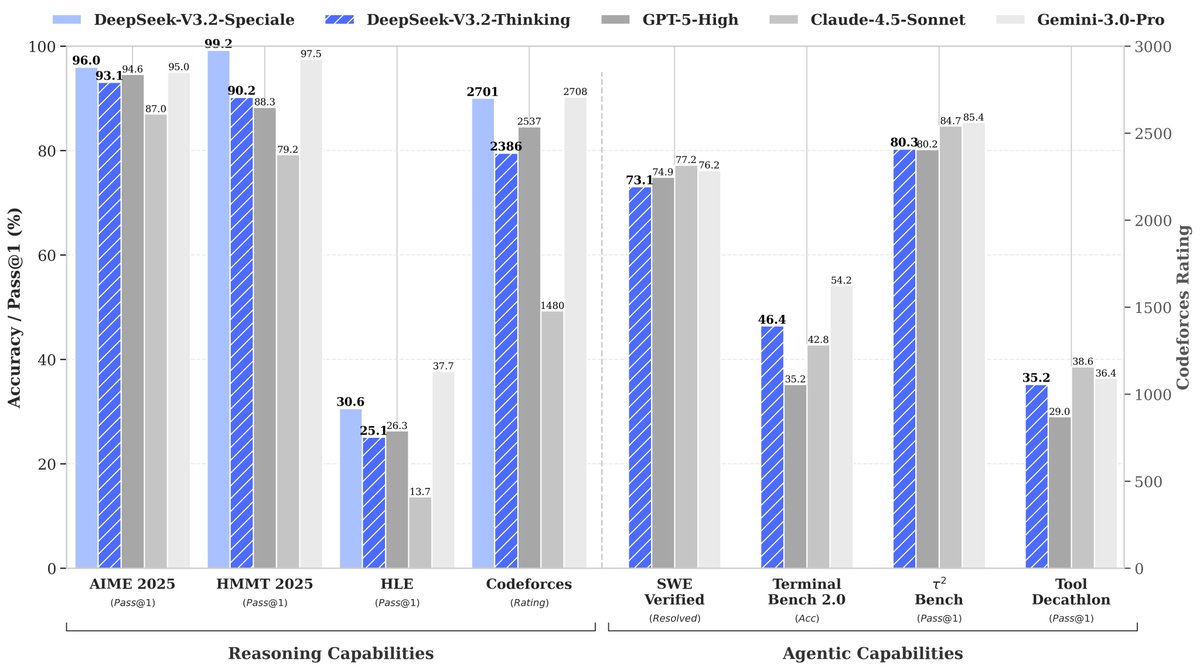
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech…
Historical.

Join us at the 5th MATH-AI Workshop at @NeurIPSConf now, our biggest year yet with a record 249 submissions!! 🎉 ➡️ mathai2025.github.io We’re honored to host an incredible lineup of speakers: @swarat @WeizhuChen @j_dekoninck @Leonard41111588 @HannaHajishirzi @chijinML…




Hope you enjoyed yesterday’s poster! We were honored to have @SonglinYang4, @Xinyu2ML, @wen_kaiyue, and many other esteemed researchers visit and share their guidance! 🚀


Mistral Large 675B, WE ARE SO BACK!

Introducing the Mistral 3 family of models: Frontier intelligence at all sizes. Apache 2.0. Details in 🧵

Fantastic.

Together with @yuxiangw_cs and Maryam Fazel, we are excited to present our tutorial "Theoretical Insights on Training Instability in Deep Learning" tomorrow at #NeurIPS2025! Link: uuujf.github.io/instability/ *picture generated by Gemini

LFG!

I will go to NeurIPS 2025@San Diego during Dec. 2-7 for my spotlight paper "Tensor product attention is all you need", and I'm also excited to meet all of you there to discuss anything interesting, exciting and enlightening about AI, LLMs and next trend of innovation.

The Next Scaling Frontier: On the Scaling Laws of Technical Blogs

Today, OpenAI is launching a new Alignment Research blog: a space for publishing more of our work on alignment and safety more frequently, and for a technical audience. alignment.openai.com
Stanford NLP Group reposted it, thanks a lot! 😀 Kudos to open research! 🚀

🚀DeepSeek V3.2 officially utilized our corrected KL regularization term in their training objective! On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning (arxiv.org/abs/2505.17508) See also tinker-docs.thinkingmachines.ai/losses It will be even better if they can…
Great work! glad to see the Proposer (Generator)-Verifier system works so well. 🚀Please refer to our previous work: arxiv.org/pdf/2308.04371 cumulative-reasoning.github.io









A new model without RoPE. Farewell.

seems like the new MoEs by @arcee_ai are coming soon, super excited for this release lfg here is a recap of the modeling choice according to the transformers PR: > MoE (2 shared experts, top-k=6, 64 total experts, sigmoid routing) > GQA with gated attention > NoPE on the global…

Worth reading, having thought about similar ideas, glad to see this actually works. 😀

RL is bounded by finite data😣? Introducing RLVE: RL with Adaptive Verifiable Environments We scale RL with data procedurally generated from 400 envs dynamically adapting to the trained model 💡find supervision signals right at the LM capability frontier + scale them 🔗in🧵…

John Schulman just followed me. Clearly, this is the singularity! 🚀



















































































United States Trendler
- 1. #UFC323 119K posts
- 2. Indiana 104K posts
- 3. Merab 41.5K posts
- 4. Roach 30K posts
- 5. Mendoza 40.4K posts
- 6. Petr Yan 23.8K posts
- 7. Ohio State 62.7K posts
- 8. Pantoja 34K posts
- 9. Bama 85.7K posts
- 10. Joshua Van 9,968 posts
- 11. Curt Cignetti 10.8K posts
- 12. Heisman 19K posts
- 13. Manny Diaz 2,842 posts
- 14. Miami 309K posts
- 15. #iufb 8,500 posts
- 16. The ACC 37.1K posts
- 17. Tulane 18.2K posts
- 18. Virginia 46.3K posts
- 19. Fielding 8,691 posts
- 20. Georgia 86.4K posts
Something went wrong.
Something went wrong.