
Karthik Narasimhan
@karthik_r_n
Professor@PrincetonCS, Research@SierraPlatform. Previously @OpenAI, @MIT_CSAIL, @iitmadras
You might like
















Is online alignment the only path to go despite being slow and computationally expensive? Inspired by prospect theory, we provide a human-centric explanation for why online alignment (e.g. GRPO) outperforms offline alignment (e.g. DPO, KTO) and empirically show how to close the…
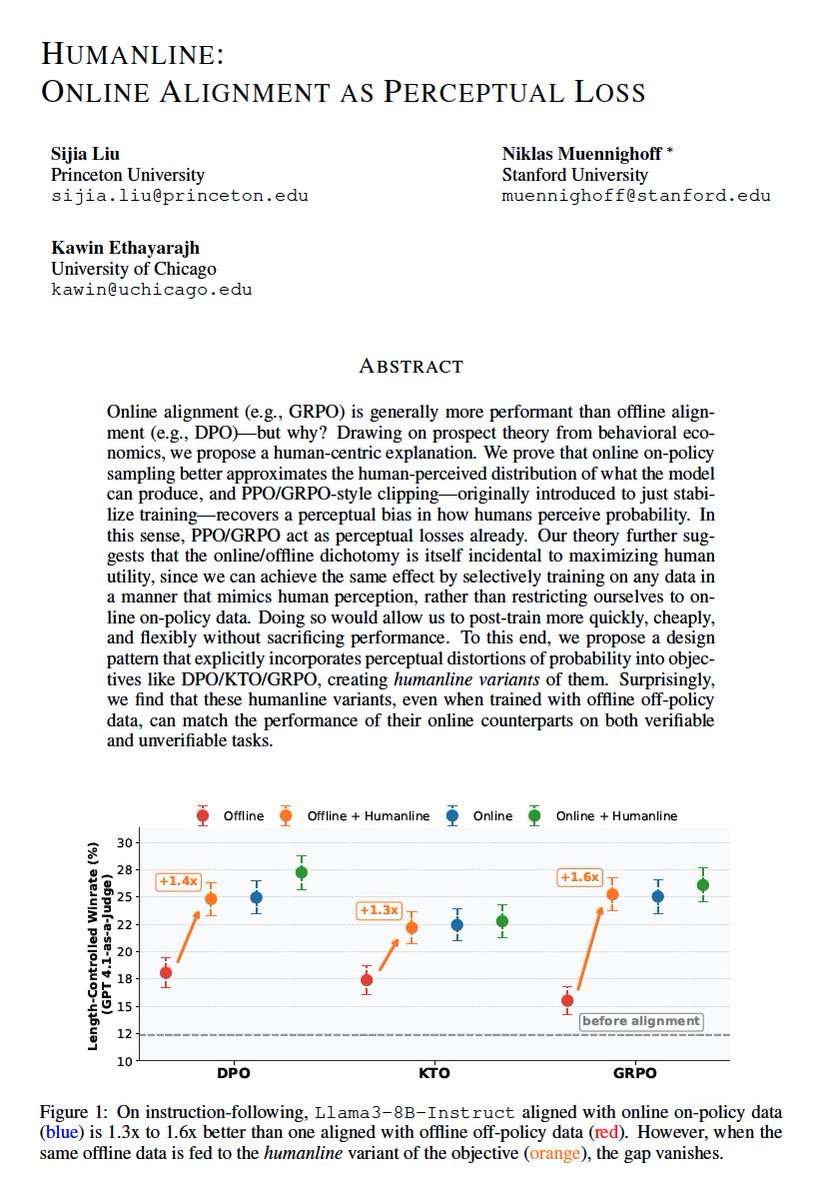

As we optimize model reasoning over verifiable objectives, how does this affect human understanding of said reasoning to achieve superior collaborative outcomes? In our new preprint, we investigate human-centric model reasoning for knowledge transfer 🧵:


Today we announced a set of major advances to our agent benchmark, 𝜏-bench. This new benchmark, 𝜏², introduces the notion of "dual control", where AI agents are challenged not just to reason and act, but to coordinate, guide, and assist a user in achieving a shared objective.…


Last year, we introduced 𝜏-bench, a benchmark for evaluating AI agents on realistic, multi-step tasks involving tool use and domain-specific constraints. It surfaced a critical limitation in LLM-based agents: low repeatability, even under identical conditions. Now, we’re…

Can GPT, Claude, and Gemini play video games like Zelda, Civ, and Doom II? 𝗩𝗶𝗱𝗲𝗼𝗚𝗮𝗺𝗲𝗕𝗲𝗻𝗰𝗵 evaluates VLMs on Game Boy & MS-DOS games given only raw screen input, just like how a human would play. The best model (Gemini) completes just 0.48% of the benchmark! 🧵👇
Successful agents are the result of collaboration between teams: engineering, operations, customer experience, and marketing. Yet every platform available today except Sierra forces businesses to optimize for one group over another. Our Agent OS enables both no code and…

Like all great products, the best agents are the product of many teams working together — some technical, some non-technical. Sierra’s Agent OS uniquely supports both no code and programmatic agent development, enabling customer experience and engineering teams alike to build…
Humans evolved to communicate so we could coordinate better. But these days, it feels like we communicate so much, yet coordinate so little.

I’m at ICLR to present a poster and give a talk, both related to the second half blogpost. See you there if you wanna chat about it :)


I finally wrote another blogpost: ysymyth.github.io/The-Second-Hal… AI just keeps getting better over time, but NOW is a special moment that i call “the halftime”. Before it, training > eval. After it, eval > training. The reason: RL finally works. Lmk ur feedback so I’ll polish it.
Interesting tidbits on using dedicated "thinking" steps in agents from @AnthropicAI Also loved seeing full pass^k curves for τ-bench - measuring this was the primary motivation of the benchmark, not just avg scores!

We’re launching a new blog: Engineering at Anthropic. A hub where developers can find practical advice and our latest discoveries on how to get the most from Claude.

In the AI age, agent reliability is key, and Sierra’s 𝜏-bench is setting the standard—shaping academic research, industry applications and next-generation development. Read more: sierra.ai/blog/tau-bench….

The best thing about SWE-agents and tools like cursor is the amount of additional agency they provide us

SWE-agent 1.0 is the open-source SOTA on SWE-bench Lite! Tons of new features: massively parallel runs; cloud-based deployment; extensive configurability with tool bundles; new command line interface & utilities.

The biggest mistake we can make right now is not dreaming big enough, especially w.r.t AI

Today we're releasing Common Sense Agents, a new backbone for agentic creative computing: 💻 Windows VMs for safe and repeatable workflows 🔧 Long workflows broken down into reusable tasks 🦾Support for off the shelf agents like Claude ⌛️ Data recording + finetuning infra
Today we're excited to announce a new way to interact with Sierra agents: voice. Learn more about how this new capability is transforming customer interactions in our latest blog post.: sierra.ai/blog/sierra-sp…

We're launching SWE-bench Multimodal to eval agents' ability to solve visual GitHub issues. - 617 *brand new* tasks from 17 JavaScript repos - Each task has an image! Existing agents struggle here! We present SWE-agent Multimodal to remedy some issues Led w/ @_carlosejimenez 🧵

Sierra partnered with @Casper to launch Luna 2.0, their AI agent delivering 24/7 personalized customer support. From helping with mattress purchases to driving lifelong loyalty, Luna 2.0 is transforming the shopping experience!💤✨️ Learn more: sierra.ai/customers/casp…

In a year or two from now, 'fine-tuning' will become synonymous with 'training' (as used in the good old ML days). LLMs will be seen more widely as starting points, just like weight initialization or choosing the number of layers for a Transformer. Pick a starting point, curate…
























































































































United States Trends
- 1. Chiefs 102K posts
- 2. Branch 30K posts
- 3. Mahomes 31.1K posts
- 4. #TNABoundForGlory 50.9K posts
- 5. #LoveCabin N/A
- 6. LaPorta 10.1K posts
- 7. Goff 13.4K posts
- 8. Bryce Miller 4,241 posts
- 9. Kelce 15.8K posts
- 10. #OnePride 6,291 posts
- 11. #LaGranjaVIP 48.3K posts
- 12. Dan Campbell 3,411 posts
- 13. #DETvsKC 4,834 posts
- 14. Butker 8,362 posts
- 15. Mariners 48.3K posts
- 16. Gibbs 5,511 posts
- 17. Baker 54K posts
- 18. Pacheco 4,900 posts
- 19. collinsworth 2,936 posts
- 20. Mike Santana 3,995 posts
You might like
-
 Jacob Andreas
Jacob Andreas
@jacobandreas -
 Sam Bowman
Sam Bowman
@sleepinyourhat -
 Hanna Hajishirzi
Hanna Hajishirzi
@HannaHajishirzi -
 Kai-Wei Chang
Kai-Wei Chang
@kaiwei_chang -
 Sewon Min
Sewon Min
@sewon__min -
 Luke Zettlemoyer
Luke Zettlemoyer
@LukeZettlemoyer -
 Mohit Bansal
Mohit Bansal
@mohitban47 -
 Danqi Chen
Danqi Chen
@danqi_chen -
 Jason Weston
Jason Weston
@jaseweston -
 Weiyan Shi
Weiyan Shi
@shi_weiyan -
 Graham Neubig
Graham Neubig
@gneubig -
 Yoav Artzi
Yoav Artzi
@yoavartzi -
 rishi
rishi
@RishiBommasani -
 He He
He He
@hhexiy -
 JHU CLSP
JHU CLSP
@jhuclsp
Something went wrong.
Something went wrong.