#100daysofcuda search results

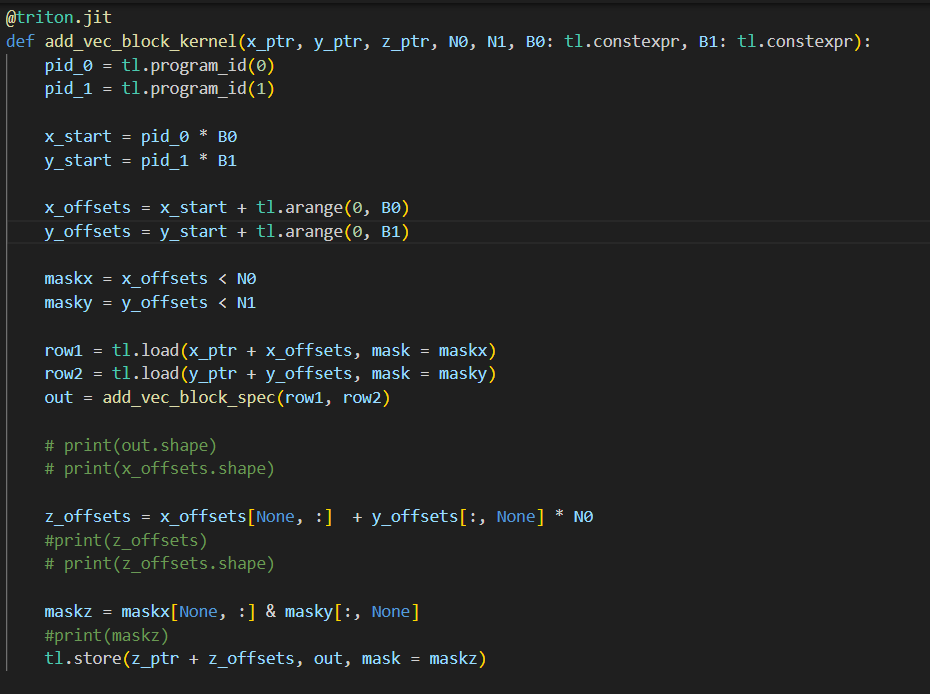
day17 #100daysofcuda Today implemented naive outer vector add and a block wise outer vector add. Also spending some time reading pytorch graph computation. Code - github.com/JINO-ROHIT/adv…

I did it!!! I did it guys. It was a nice run. All thanks to @hkproj for starting #100DaysofCuda CC: @salykova_
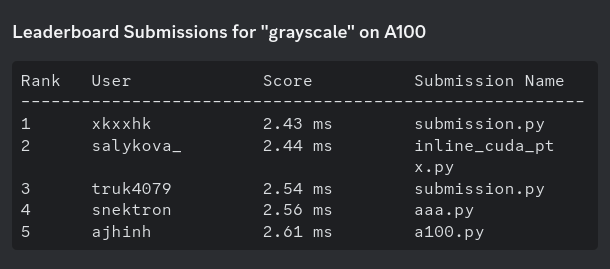

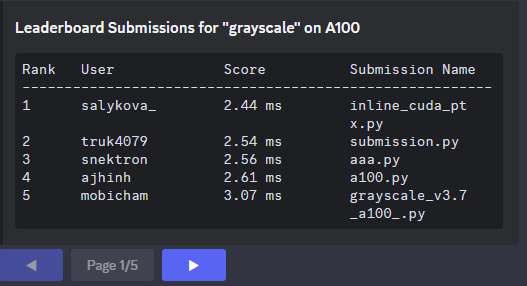
It's your turn now @mobicham @ajhinh. Towards SOTA grayscale kernel 🤣💀 Jokes aside, the GPU Kernel Leaderboard is a great place to sharpen your CUDA skills and learn how to build the fastest kernels. Maybe @__tinygrad__ will make a comeback. Lets see. Link below
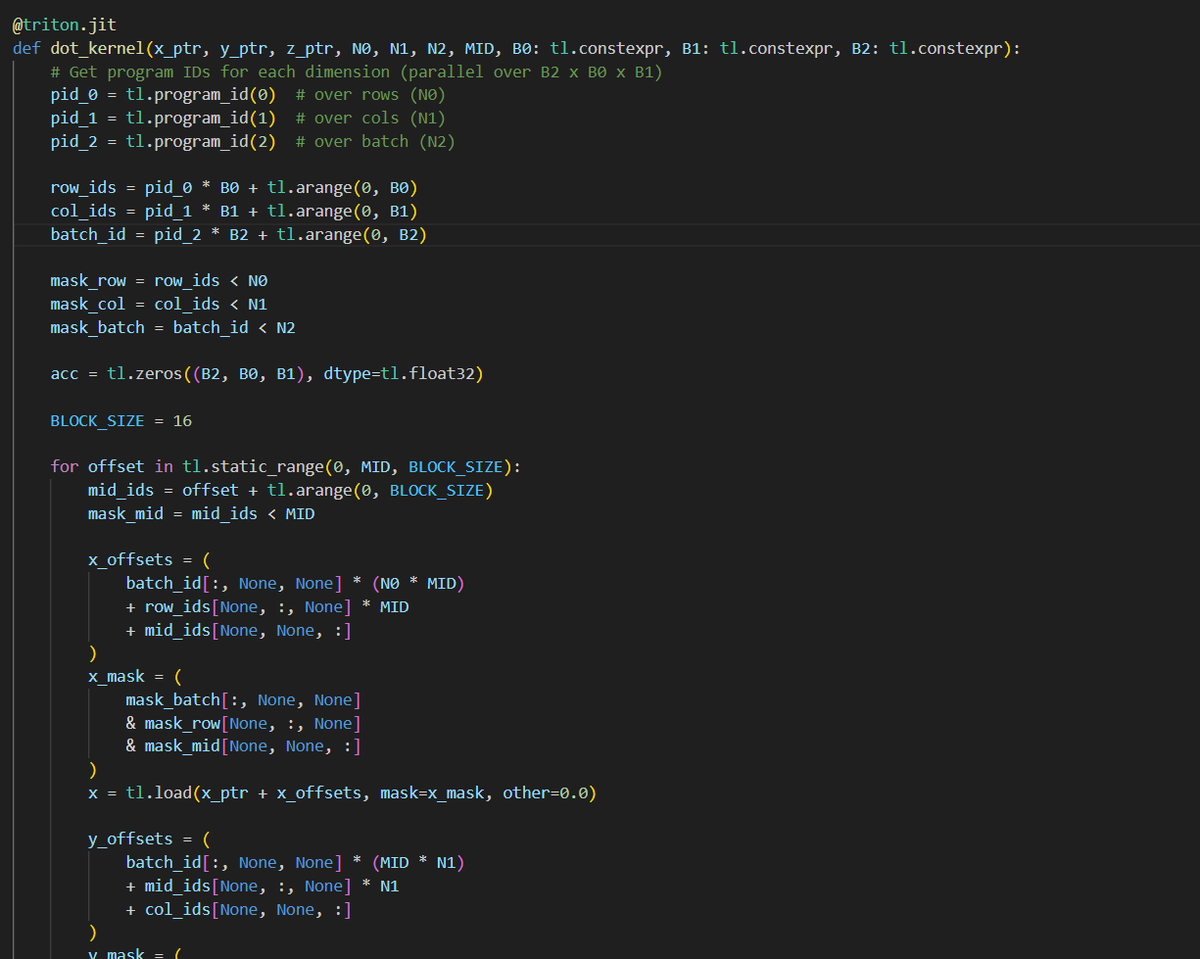
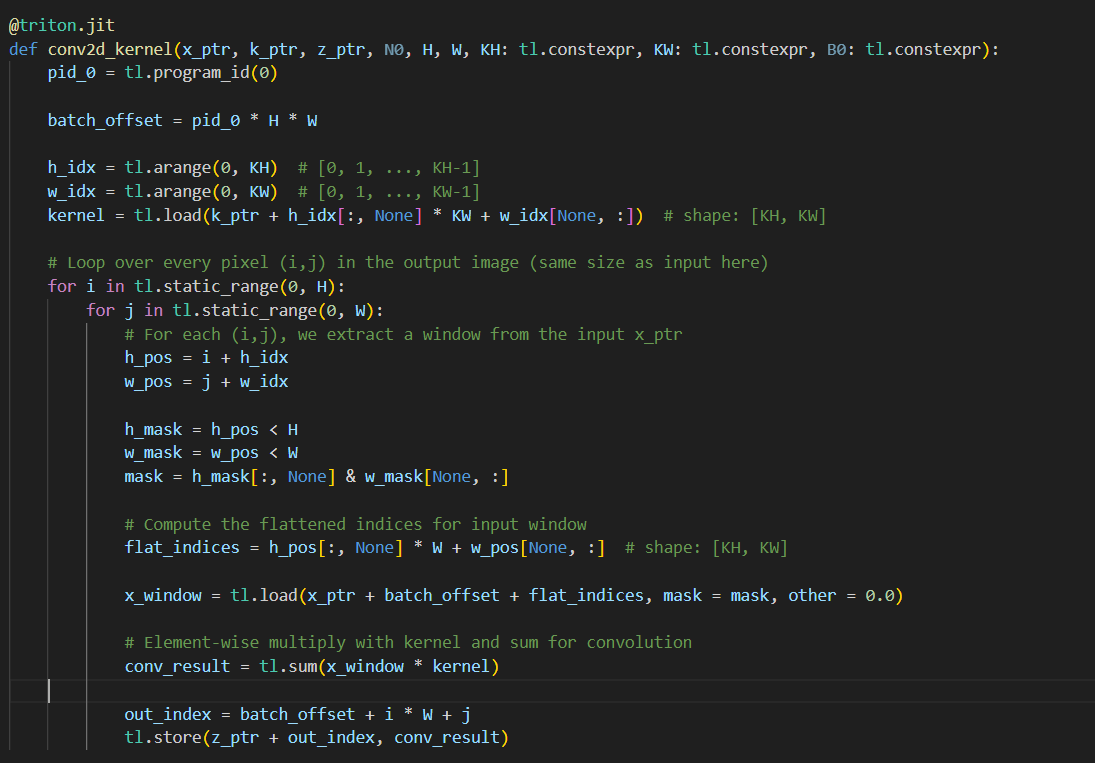
day23 #100daysofcuda Implemented matrix multiplication over batches. Code - github.com/JINO-ROHIT/adv…
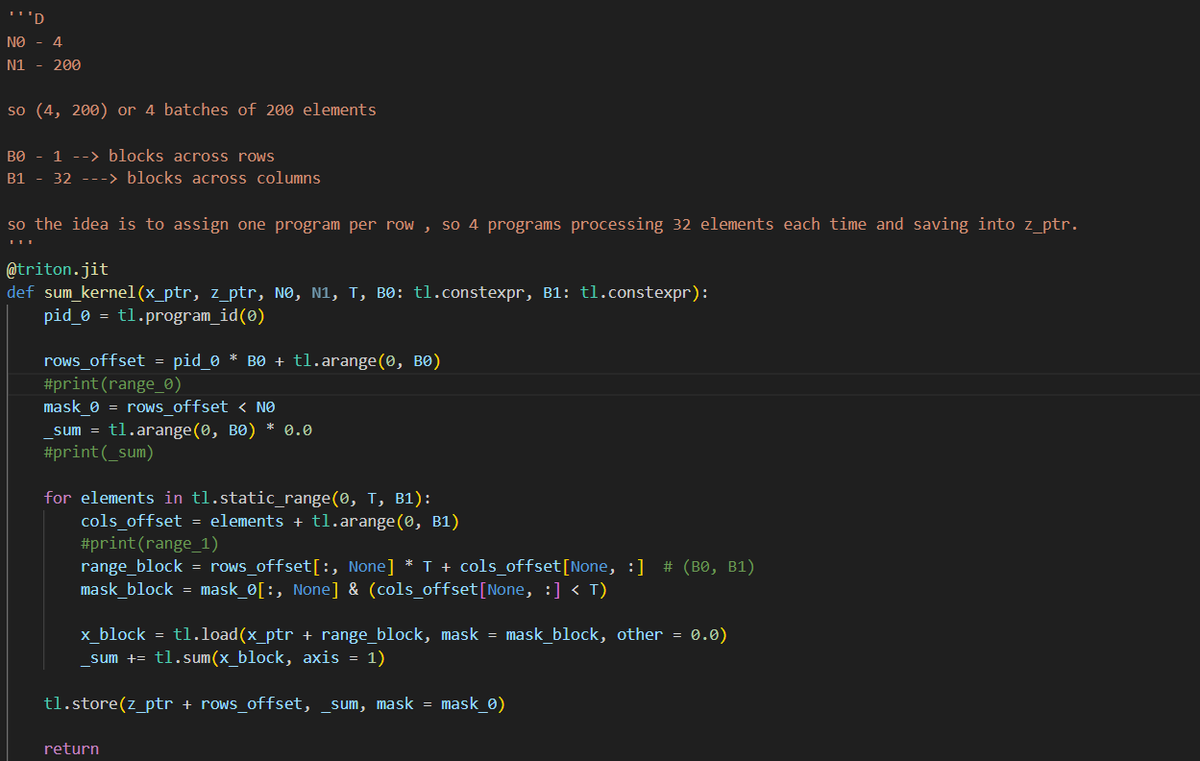
day22 #100daysofcuda Implemented a convolution2d kernel in triton :) Code - github.com/JINO-ROHIT/adv…

"10 days into CUDA, and I’ve earned my first badge of honor! 🚀 From simple kernels to profiling, every day is a step closer to mastering GPU computing. Onward to 100! #CUDA #GPUProgramming #100DaysOfCUDA"

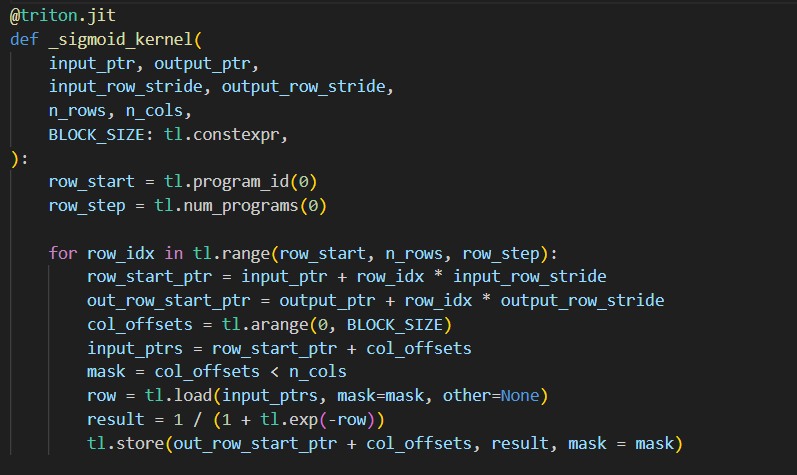
day10 #100daysofcuda This marks 1/10th of journey in consistently learning cuda and triton kernels. The goal is to write for unsloth and learn to make an optimal inference engine. Wrote a triton kernel for sigmoid. Code - github.com/JINO-ROHIT/adv…
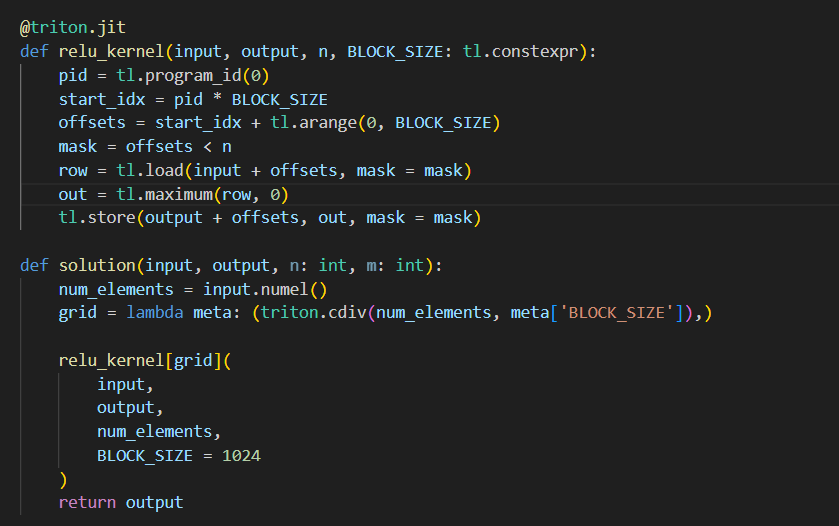
day15 #100daysofcuda Implemented leaky relu and elu kernels in triton. Code - github.com/JINO-ROHIT/adv…
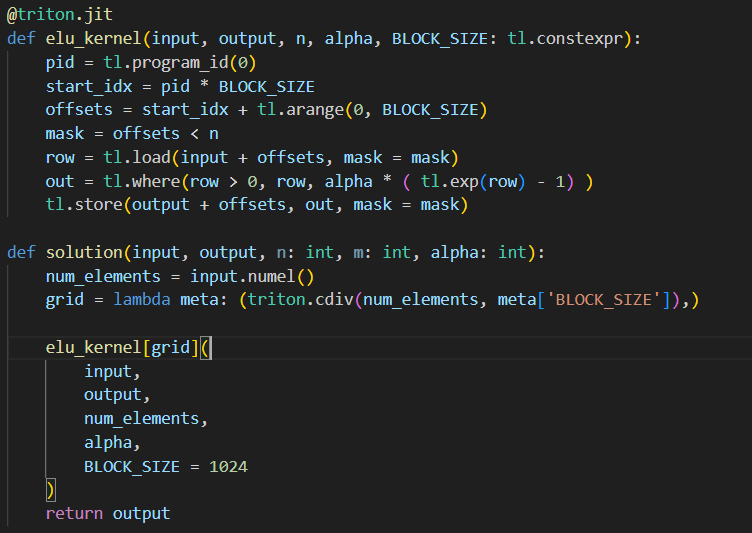
day20 #100daysofcuda Today, I implemented softmax, actually a numerically stable version of softmax. Code - github.com/JINO-ROHIT/adv…
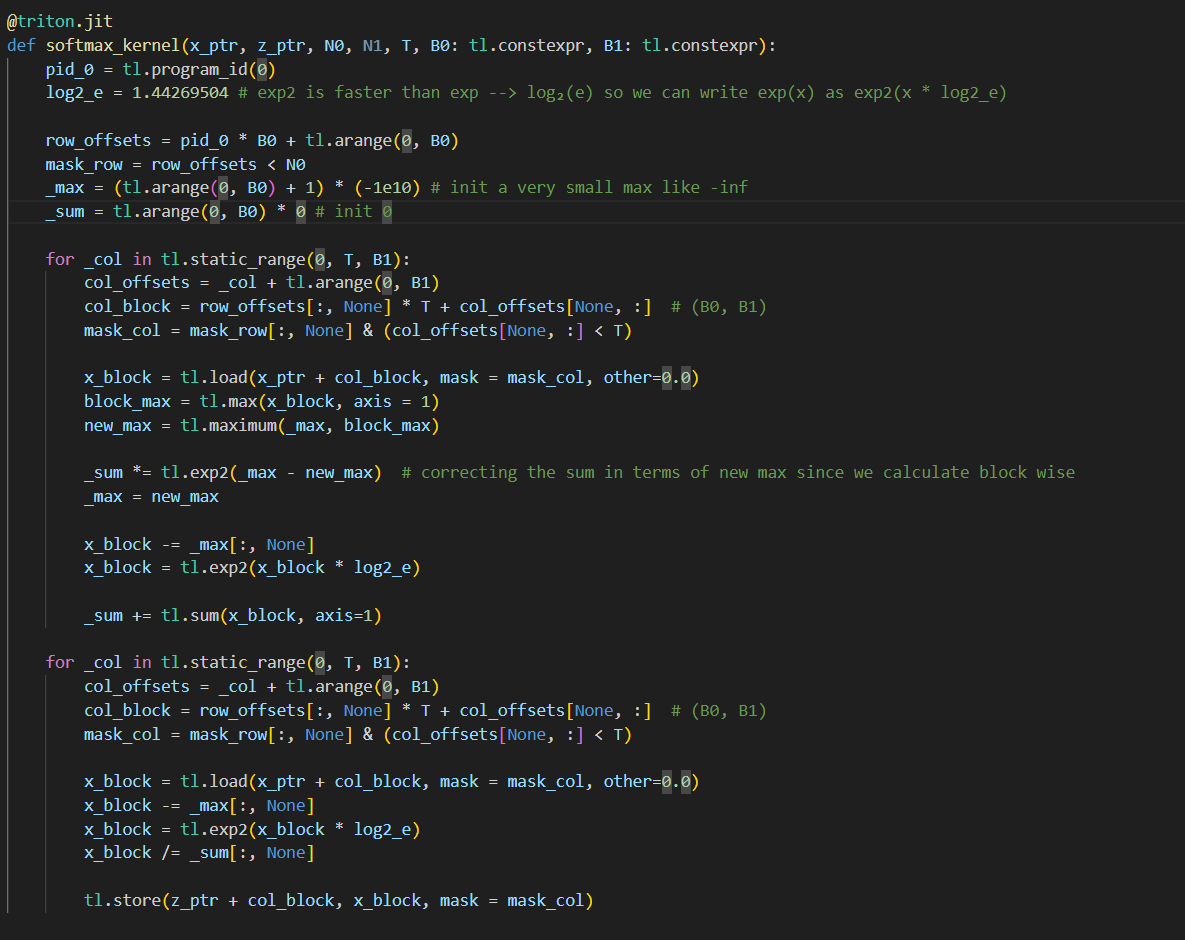
day21 #100daysofcuda Implementing a scalar version of flash attention. Should be quite simple to read and understand. Code - github.com/JINO-ROHIT/adv…
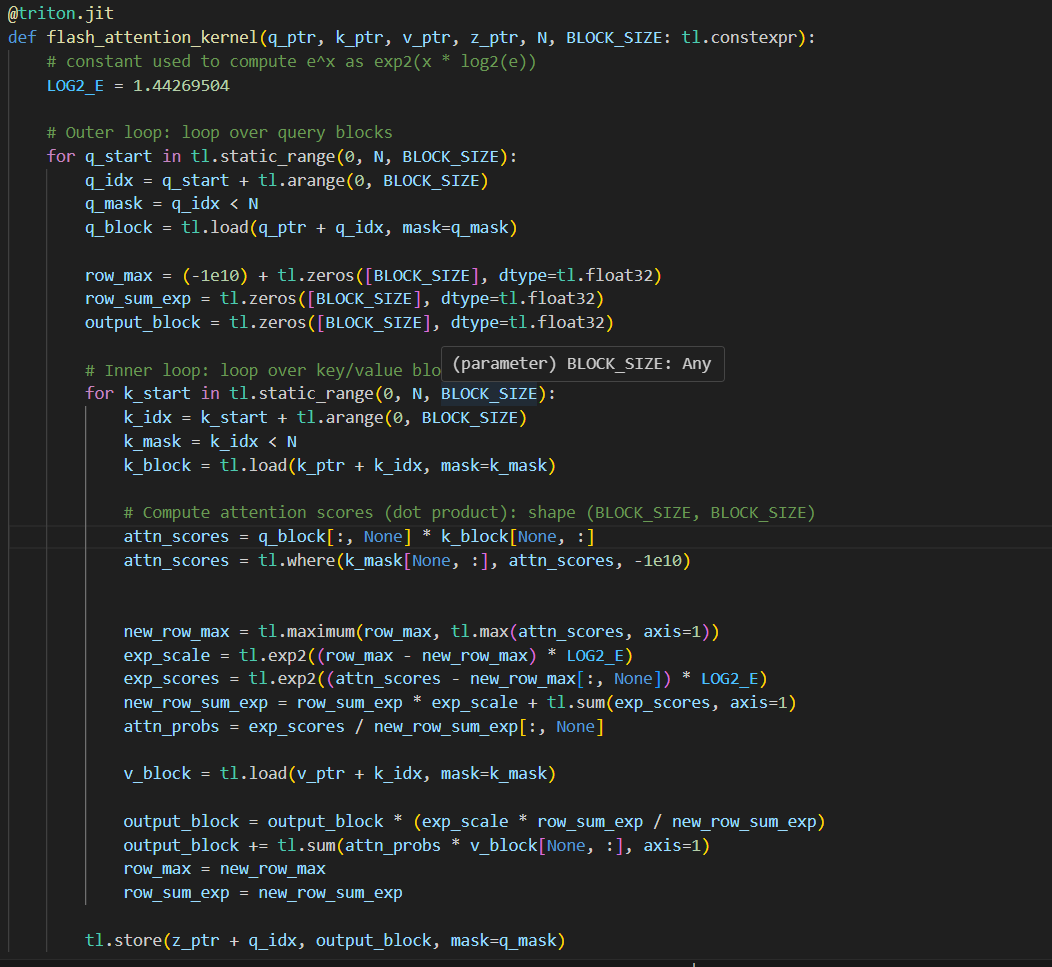
day9 #100daysofcuda Wrote a triton kernel for tanh activation. Going to focus on getting more submissions on tensara and further optimize it. Code - github.com/JINO-ROHIT/adv…
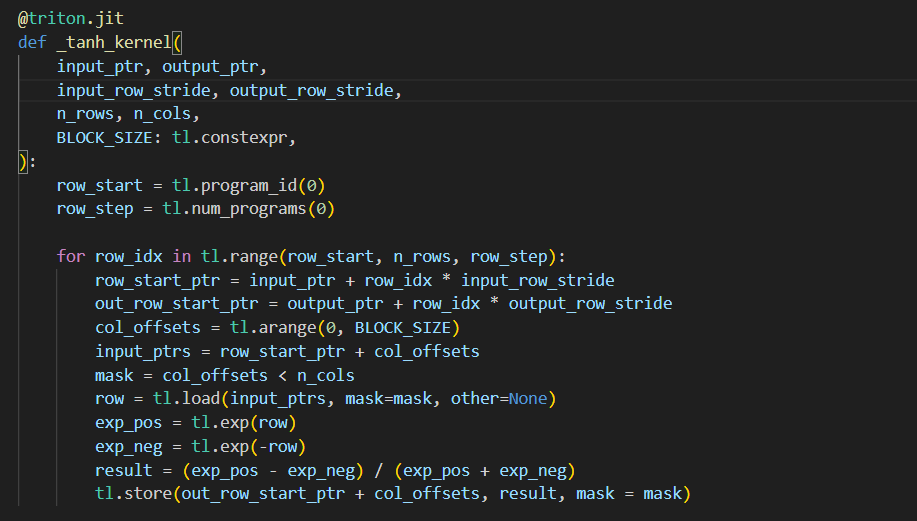
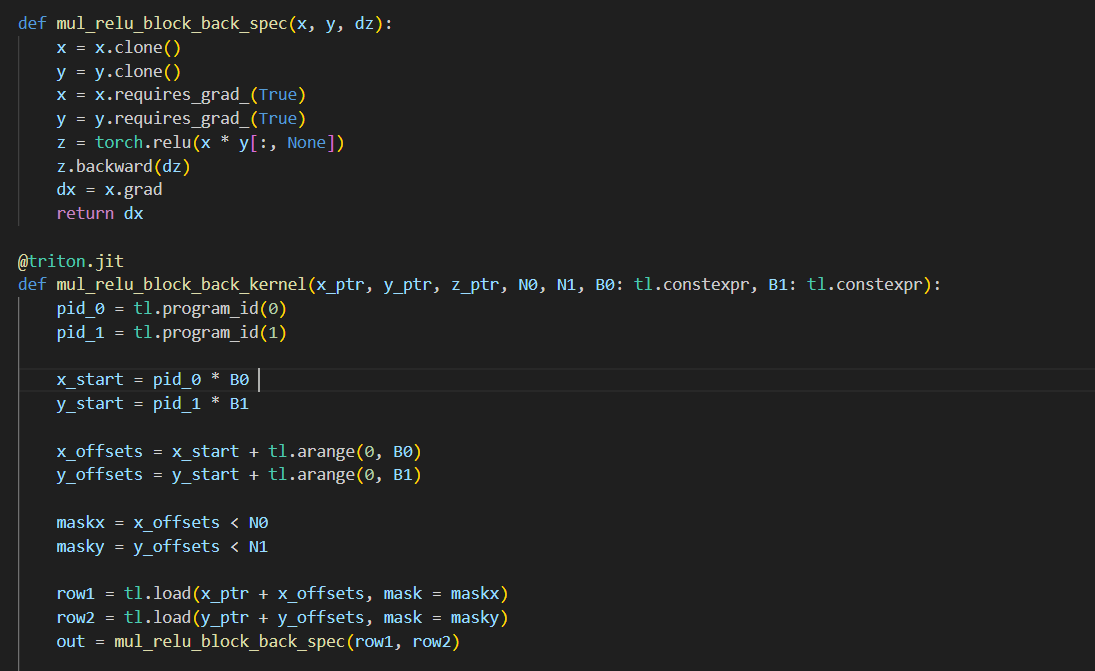
day18 #100daysofcuda 1. Implemented fused outer multiplication along with backward pass. 2. Going through some liger kernels. Code - github.com/JINO-ROHIT/adv…

Today I completed the #100daysofcuda github.com/Ruhaan838/100D…
github.com
GitHub - Ruhaan838/100Day-GPU: I am trying to Learn CUDA in 100 Days. (inspired by @hkproj)
I am trying to Learn CUDA in 100 Days. (inspired by @hkproj) - Ruhaan838/100Day-GPU
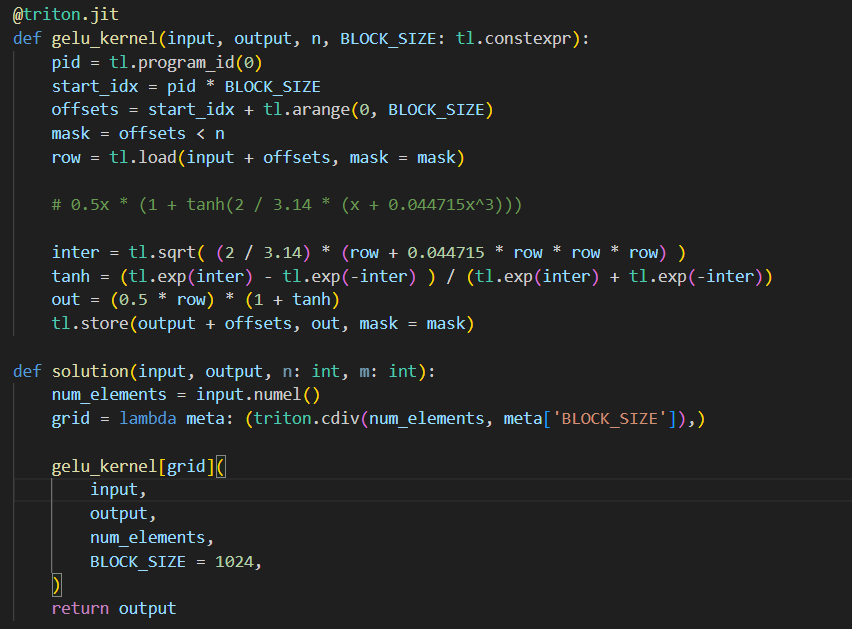
Day16 #100daysofcuda 1. Kept it simple and implemented a gelu kernel. 2. Spent a lot more time understanding the intuition for multiple programs/blocks/threads. Code - github.com/JINO-ROHIT/adv…
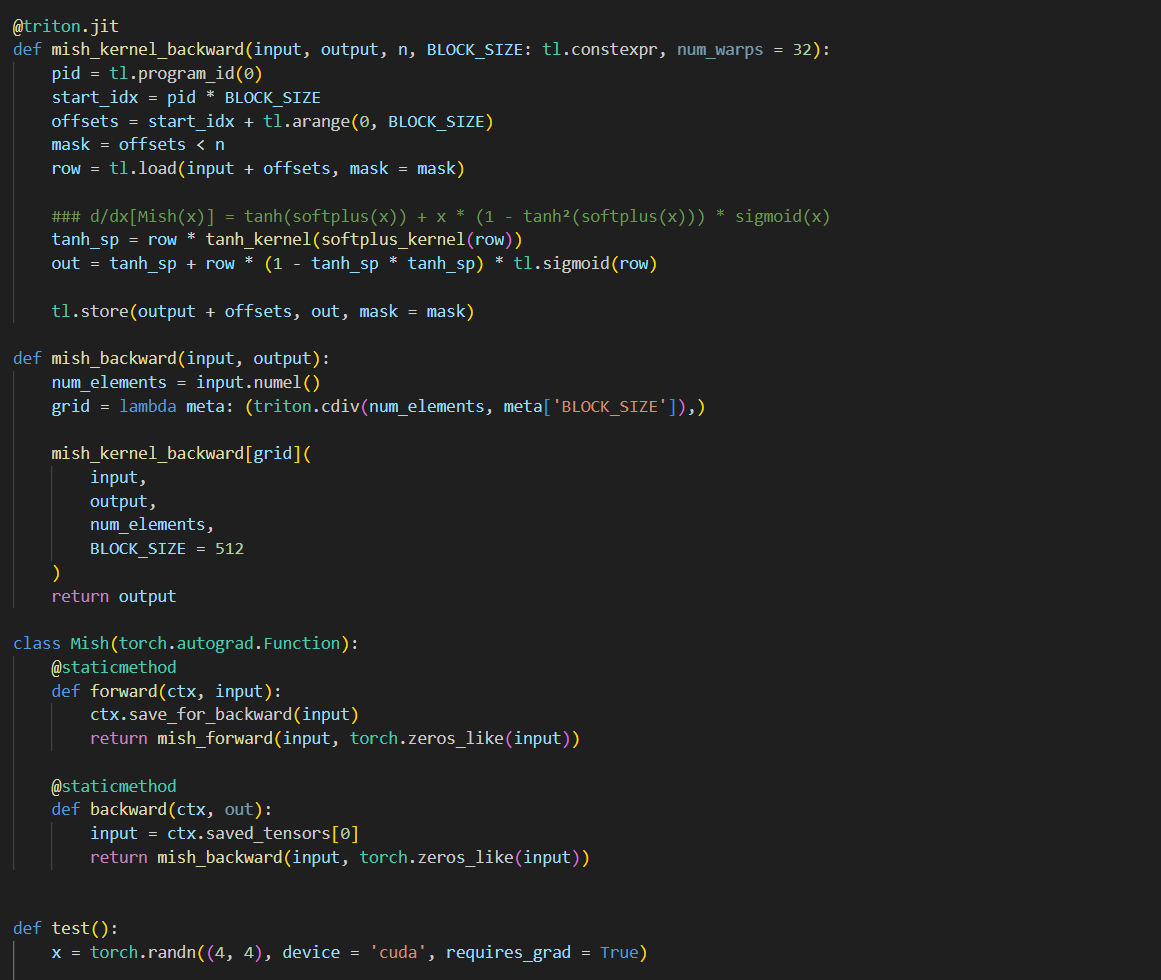
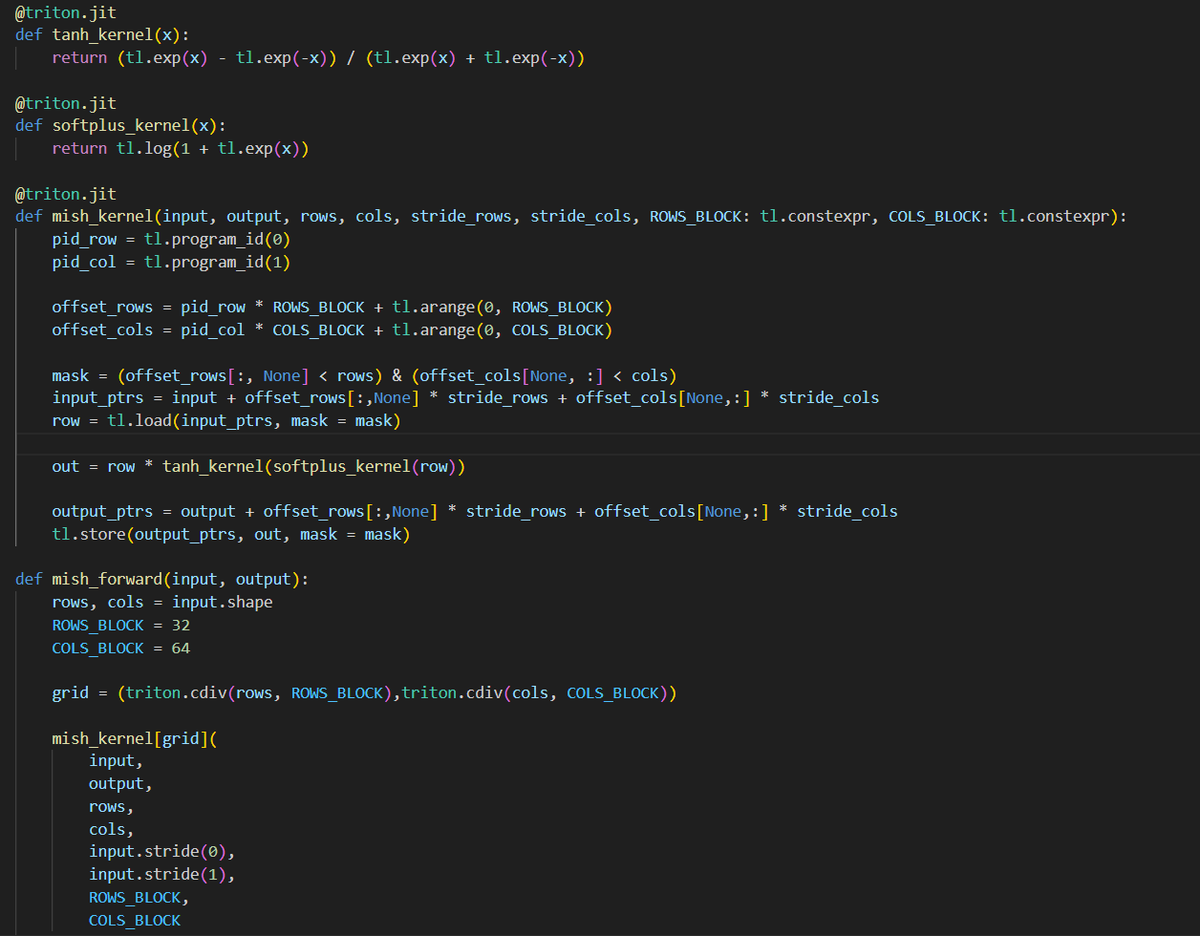
day 28 #100daysofcuda Implemented backward pass for mish kernel and compared it with torch backward gradients! Almost fully equipped with using custom triton kernels for pytorch modules Code - github.com/JINO-ROHIT/adv…

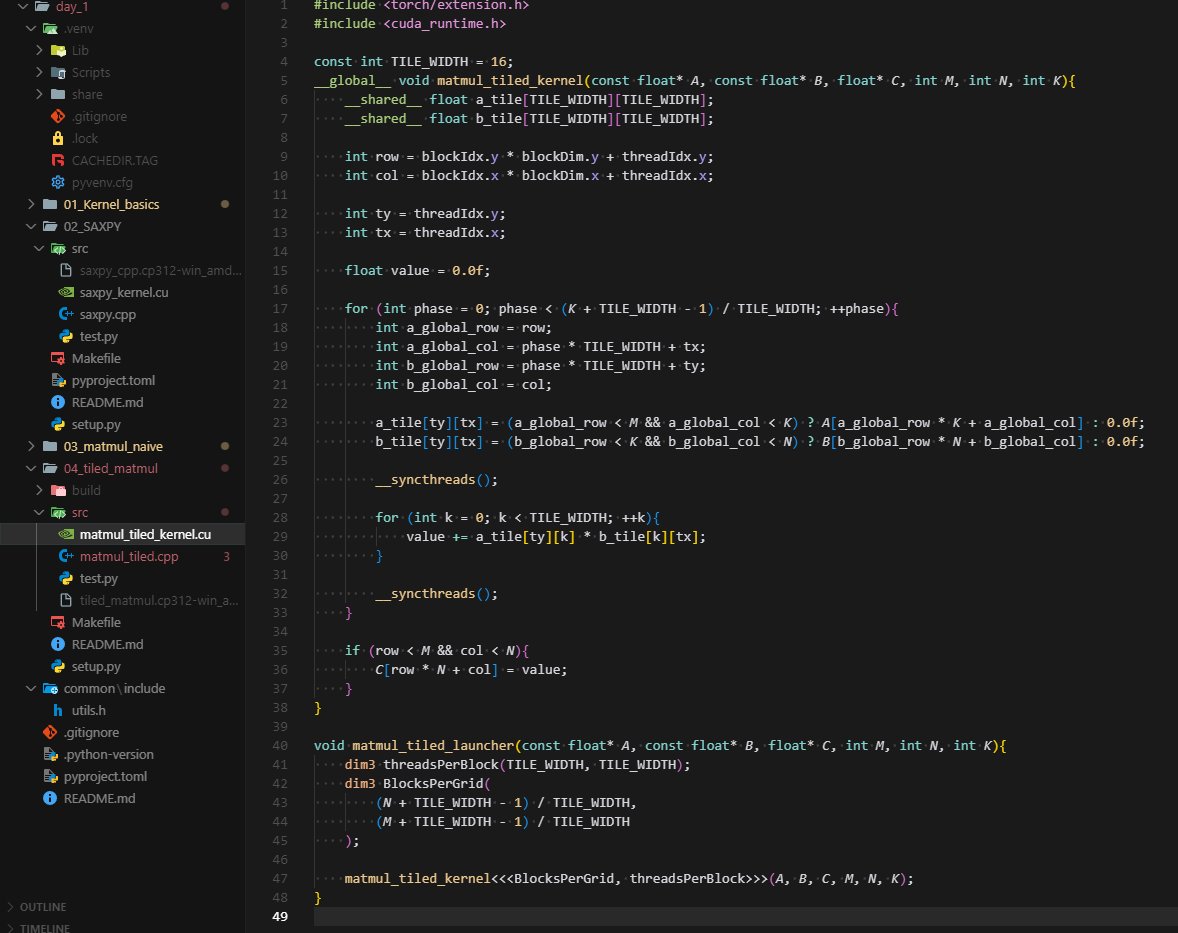
Day 2/100 of my #100DaysOfCUDA challenge: Optimizing Matrix Multiplication! Yesterday's "naive" kernel was slow. Why? Global memory latency. Today, I implemented a tiled MatMul using shared memory. The strategy: fetch data from the slow "warehouse" (VRAM) in chunks (tiles)
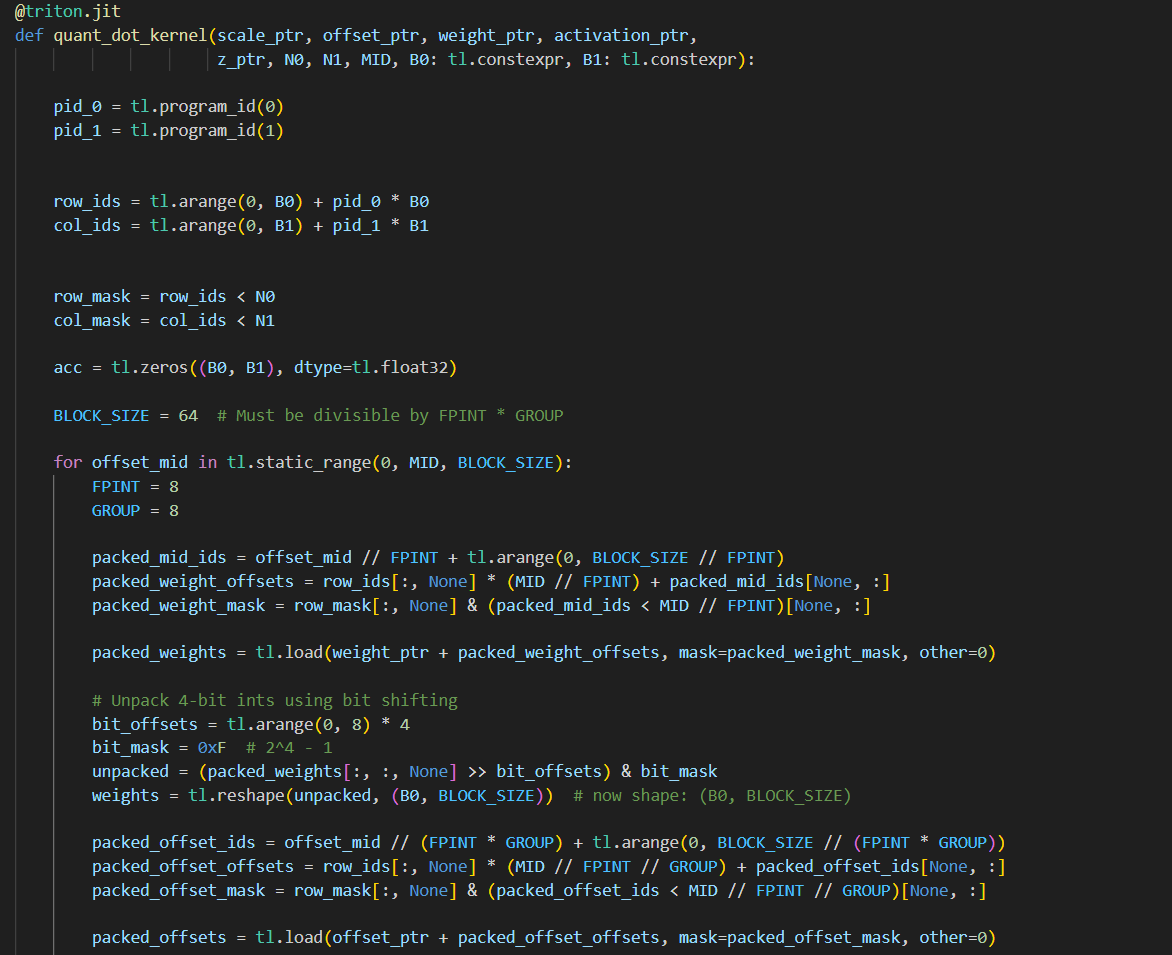
day24 #100daysofcuda Implementing quantized matrix multiplication in triton. When doing matrix multiplication with quantized neural networks a common strategy is to store the weight matrix in lower precision, with a shift and scale term. Code - github.com/JINO-ROHIT/adv…
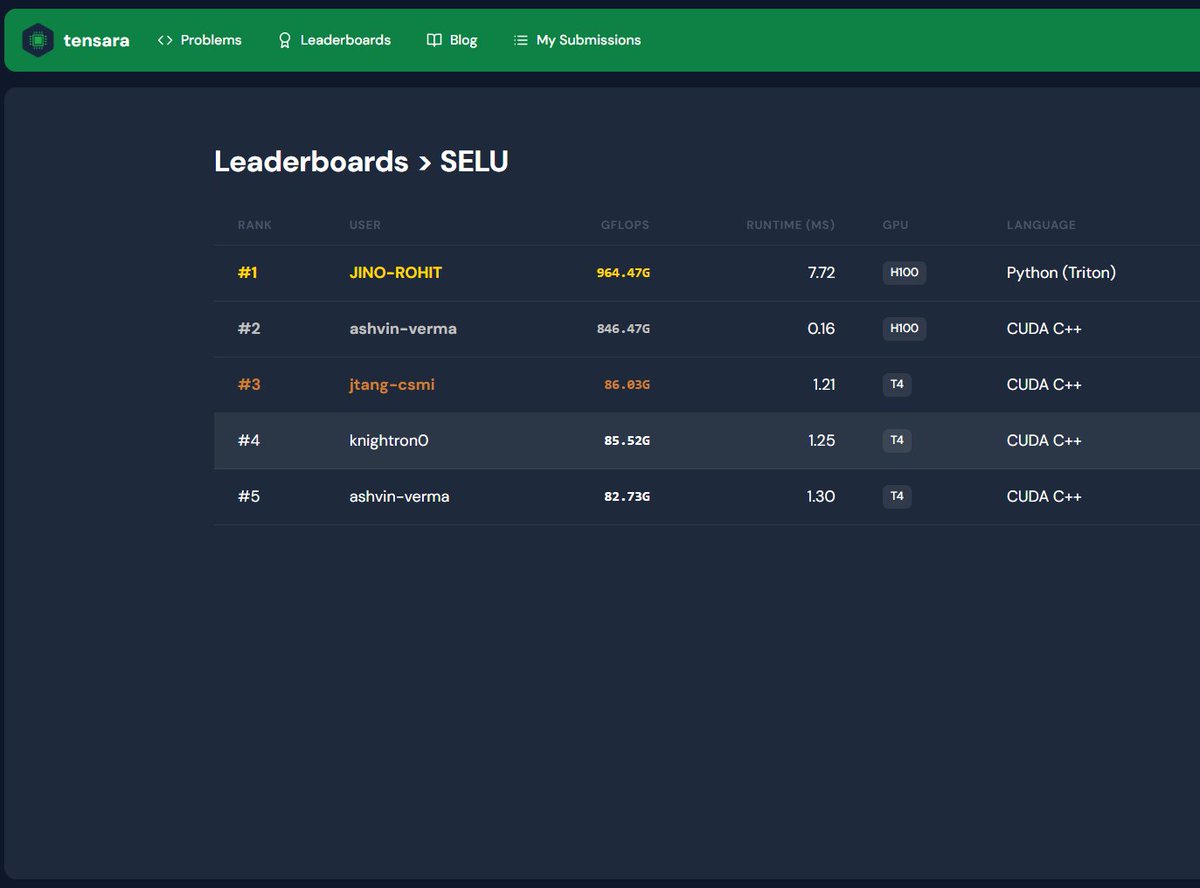
day11 #100daysofcuda Today I had some help from tensara team on debugging my previous kernels, realized it had a critical flaw. Fixed those two today. For kernels today, I wrote a selu kernel and topped the tensara leaderboard. Code - github.com/JINO-ROHIT/adv…
day 29 #100daysofcuda 1. Implementing mish activation forward and backward pass using a 2d launch grid in triton. 2. Looking into pytorch graph compilation . Code - github.com/JINO-ROHIT/adv…
Today I completed the #100daysofcuda github.com/Ruhaan838/100D…
github.com
GitHub - Ruhaan838/100Day-GPU: I am trying to Learn CUDA in 100 Days. (inspired by @hkproj)
I am trying to Learn CUDA in 100 Days. (inspired by @hkproj) - Ruhaan838/100Day-GPU
day 29 #100daysofcuda 1. Implementing mish activation forward and backward pass using a 2d launch grid in triton. 2. Looking into pytorch graph compilation . Code - github.com/JINO-ROHIT/adv…
day 28 #100daysofcuda Implemented backward pass for mish kernel and compared it with torch backward gradients! Almost fully equipped with using custom triton kernels for pytorch modules Code - github.com/JINO-ROHIT/adv…
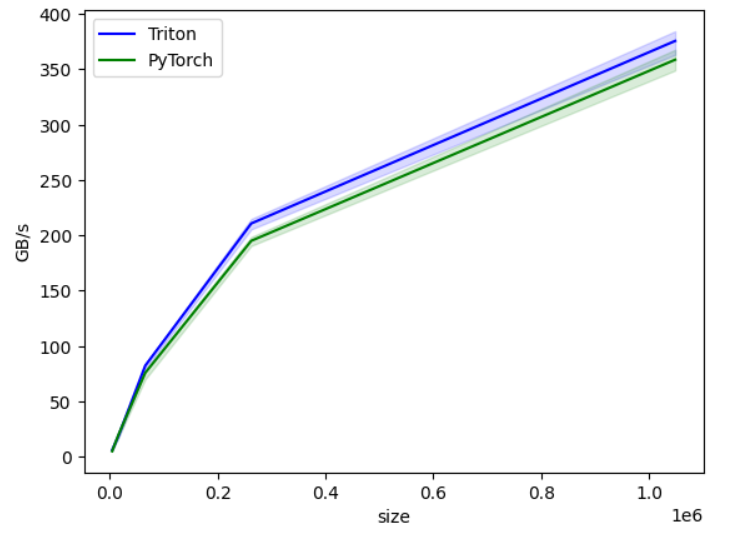
day27 #100daysofcuda Today I implemented the mish activation function in triton and bechmarked vs pytorch implementation. Was ~ 5-8% consistently better than torch implementation. Code - github.com/JINO-ROHIT/adv… Should i write beginner friendly blogs for triton?
day25 #100daysofcuda Today I put together the solutions for the triton puzzles from professor @srush_nlp . Amazing puzzles, they start from basic principles and work you up to flash attention and complex matrix multiplications. Solutions here - github.com/JINO-ROHIT/adv…
day24 #100daysofcuda Implementing quantized matrix multiplication in triton. When doing matrix multiplication with quantized neural networks a common strategy is to store the weight matrix in lower precision, with a shift and scale term. Code - github.com/JINO-ROHIT/adv…
day23 #100daysofcuda Implemented matrix multiplication over batches. Code - github.com/JINO-ROHIT/adv…
day22 #100daysofcuda Implemented a convolution2d kernel in triton :) Code - github.com/JINO-ROHIT/adv…
day21 #100daysofcuda Implementing a scalar version of flash attention. Should be quite simple to read and understand. Code - github.com/JINO-ROHIT/adv…

I am going to start #100DaysofCUDA , i know things in it but let's become consistent again so let's do it Got motivation by @jino_rohit Amazing repo !!!!!! SIR Let's good
day20 #100daysofcuda Today, I implemented softmax, actually a numerically stable version of softmax. Code - github.com/JINO-ROHIT/adv…
day18 #100daysofcuda 1. Implemented fused outer multiplication along with backward pass. 2. Going through some liger kernels. Code - github.com/JINO-ROHIT/adv…
day17 #100daysofcuda Today implemented naive outer vector add and a block wise outer vector add. Also spending some time reading pytorch graph computation. Code - github.com/JINO-ROHIT/adv…
Day16 #100daysofcuda 1. Kept it simple and implemented a gelu kernel. 2. Spent a lot more time understanding the intuition for multiple programs/blocks/threads. Code - github.com/JINO-ROHIT/adv…
day15 #100daysofcuda Implemented leaky relu and elu kernels in triton. Code - github.com/JINO-ROHIT/adv…
day14 #100daysofcuda We made it to two weeks of writing a cuda kernel everyday! Wrote a triton kernel for softplus. Code - github.com/JINO-ROHIT/adv…
day11 #100daysofcuda Today I had some help from tensara team on debugging my previous kernels, realized it had a critical flaw. Fixed those two today. For kernels today, I wrote a selu kernel and topped the tensara leaderboard. Code - github.com/JINO-ROHIT/adv…
day23 #100daysofcuda Implemented matrix multiplication over batches. Code - github.com/JINO-ROHIT/adv…
day17 #100daysofcuda Today implemented naive outer vector add and a block wise outer vector add. Also spending some time reading pytorch graph computation. Code - github.com/JINO-ROHIT/adv…
I did it!!! I did it guys. It was a nice run. All thanks to @hkproj for starting #100DaysofCuda CC: @salykova_
It's your turn now @mobicham @ajhinh. Towards SOTA grayscale kernel 🤣💀 Jokes aside, the GPU Kernel Leaderboard is a great place to sharpen your CUDA skills and learn how to build the fastest kernels. Maybe @__tinygrad__ will make a comeback. Lets see. Link below
day22 #100daysofcuda Implemented a convolution2d kernel in triton :) Code - github.com/JINO-ROHIT/adv…
day15 #100daysofcuda Implemented leaky relu and elu kernels in triton. Code - github.com/JINO-ROHIT/adv…
day20 #100daysofcuda Today, I implemented softmax, actually a numerically stable version of softmax. Code - github.com/JINO-ROHIT/adv…
day10 #100daysofcuda This marks 1/10th of journey in consistently learning cuda and triton kernels. The goal is to write for unsloth and learn to make an optimal inference engine. Wrote a triton kernel for sigmoid. Code - github.com/JINO-ROHIT/adv…
day9 #100daysofcuda Wrote a triton kernel for tanh activation. Going to focus on getting more submissions on tensara and further optimize it. Code - github.com/JINO-ROHIT/adv…
day21 #100daysofcuda Implementing a scalar version of flash attention. Should be quite simple to read and understand. Code - github.com/JINO-ROHIT/adv…
day18 #100daysofcuda 1. Implemented fused outer multiplication along with backward pass. 2. Going through some liger kernels. Code - github.com/JINO-ROHIT/adv…
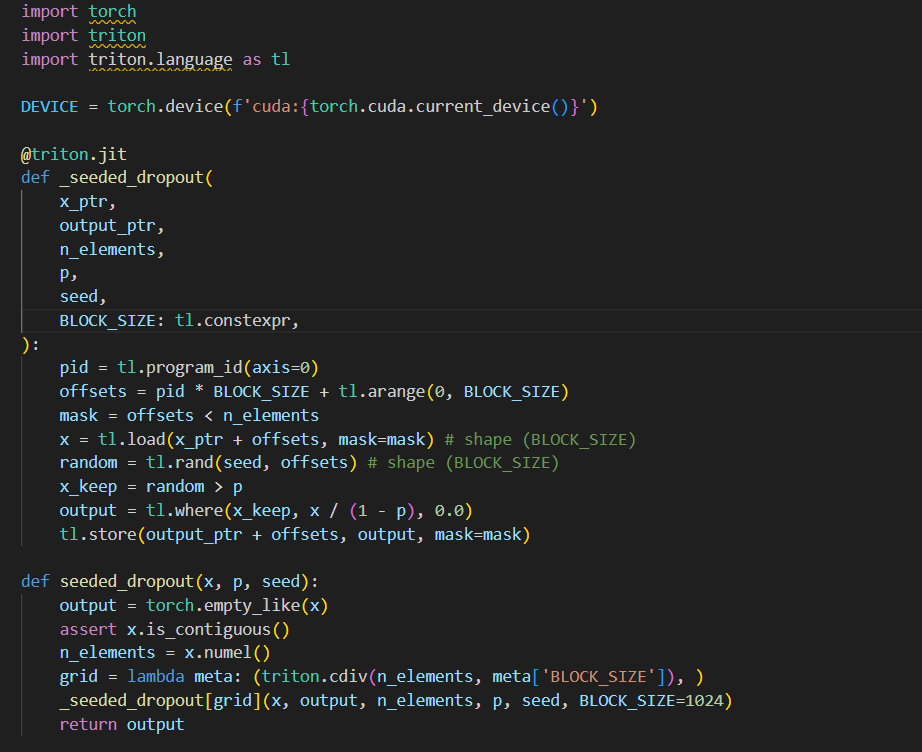
day8 #100daysofcuda Implemented a memory efficient version of dropout in triton. Code - github.com/JINO-ROHIT/adv…
"10 days into CUDA, and I’ve earned my first badge of honor! 🚀 From simple kernels to profiling, every day is a step closer to mastering GPU computing. Onward to 100! #CUDA #GPUProgramming #100DaysOfCUDA"
Day16 #100daysofcuda 1. Kept it simple and implemented a gelu kernel. 2. Spent a lot more time understanding the intuition for multiple programs/blocks/threads. Code - github.com/JINO-ROHIT/adv…
Day6 #100daysofcuda Implemented a naive softmax kernel and spent some time learning the quirks of triton kernels. Planning to optimize this kernel for the next following days. Code - github.com/JINO-ROHIT/adv…
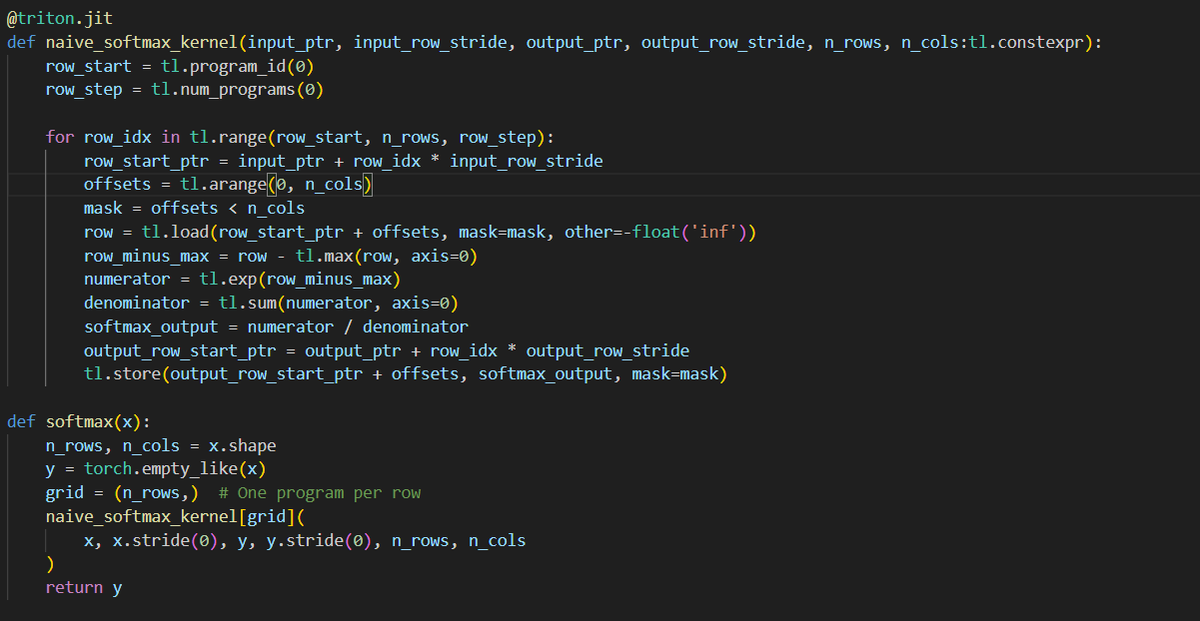
day7 #100daysofcuda Made to day 7, today certain concepts clicked on how triton passes in data via meta, kernel warmup striding etc. Implemented the fused softmax from the triton guide . Code - github.com/JINO-ROHIT/adv…
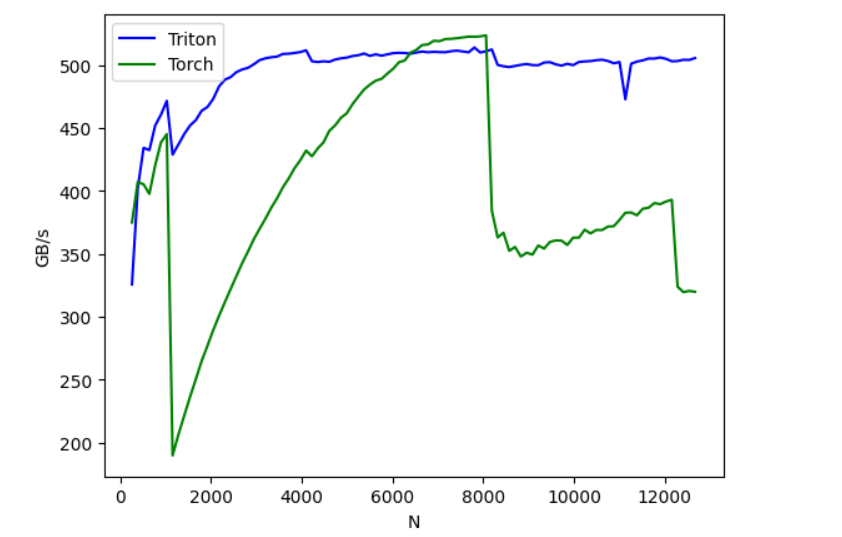
day 28 #100daysofcuda Implemented backward pass for mish kernel and compared it with torch backward gradients! Almost fully equipped with using custom triton kernels for pytorch modules Code - github.com/JINO-ROHIT/adv…
day11 #100daysofcuda Today I had some help from tensara team on debugging my previous kernels, realized it had a critical flaw. Fixed those two today. For kernels today, I wrote a selu kernel and topped the tensara leaderboard. Code - github.com/JINO-ROHIT/adv…
day24 #100daysofcuda Implementing quantized matrix multiplication in triton. When doing matrix multiplication with quantized neural networks a common strategy is to store the weight matrix in lower precision, with a shift and scale term. Code - github.com/JINO-ROHIT/adv…
Something went wrong.
Something went wrong.
United States Trends
- 1. #socideveloper_com N/A
- 2. ARMY Protect The 8thDaesang 46.1K posts
- 3. #lip_bomb_RESCENE N/A
- 4. #DaesangForJin 44.1K posts
- 5. #2025MAMAVOTE 71.6K posts
- 6. #ENHYPEN 124K posts
- 7. Black Friday 281K posts
- 8. ilya 19K posts
- 9. Shane 23.1K posts
- 10. Ravens 59.7K posts
- 11. Lamar 47.1K posts
- 12. Bengals 53.3K posts
- 13. Mnet 170K posts
- 14. Third World Countries 32.4K posts
- 15. Sarah Beckstrom 235K posts
- 16. Joe Burrow 21.7K posts
- 17. Connor 15.5K posts
- 18. BNB Chain 8,112 posts
- 19. Hudson 12.2K posts
- 20. Jungwoo 129K posts