#codequalitymetrics 搜尋結果

Monitor code coverage across all team projects, ensuring critical paths are well-tested. Set thresholds for desired coverage levels for both existing and fresh code. Take a look here: jetbrains.com/qodana/feature… #CodeCoverage #CodeQualityMetrics #Qodana

Data-mining for #CodeQualityMetrics - check this out here http://bit.ly/OIyRL

We continue our journey into #CodeQuality 📚 Discover about #codequalitymetrics and the 3 key aspects you should always be ⚠️ cautious with ⚠️ 👉 ponicode.com/shift-left/wha…

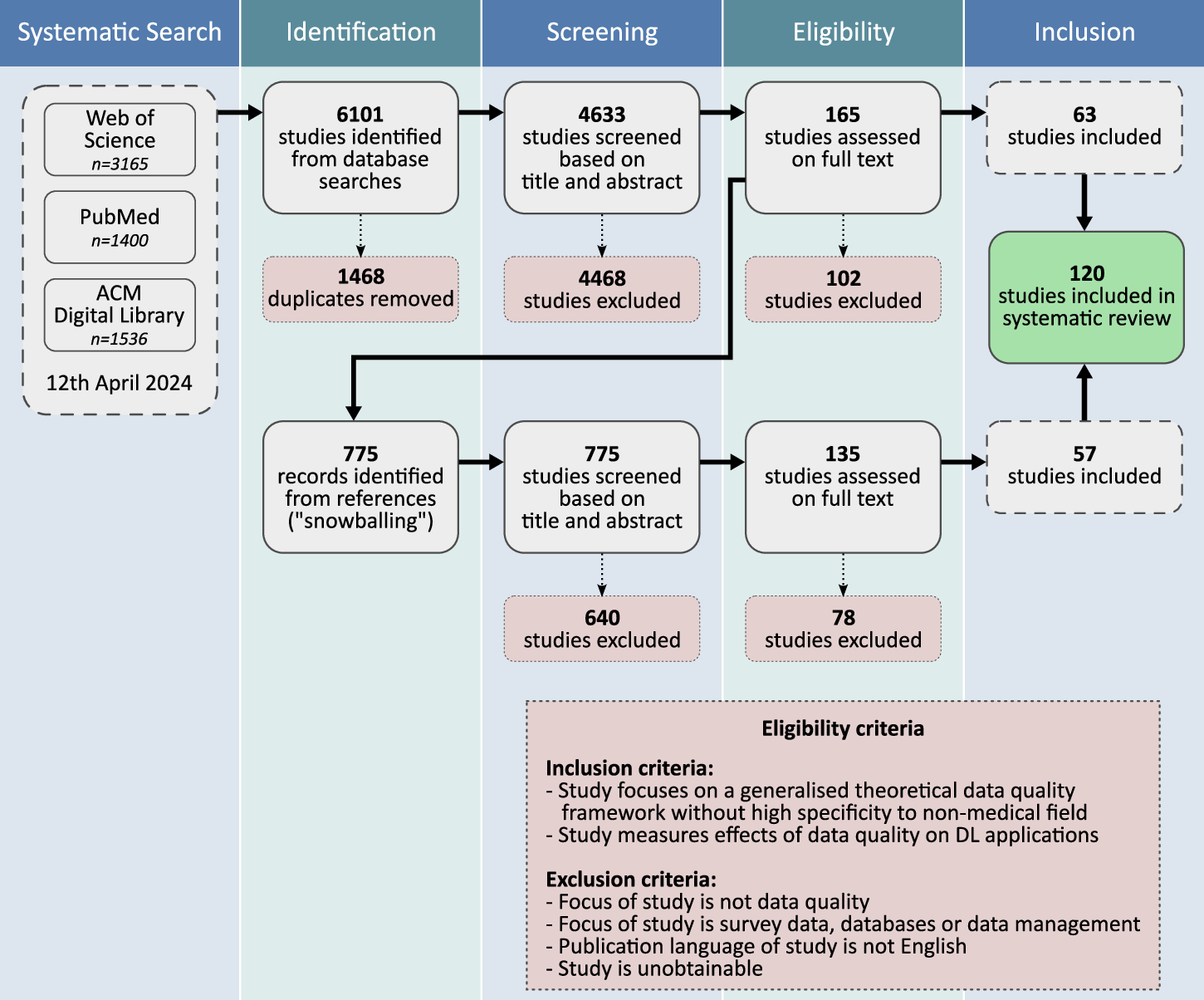
The METRIC-framework for assessing #data quality for trustworthy #AI in medicine: a systematic review | @npjDigitalMed #MedTech #TechHartford doi.org/10.1038/s41746…

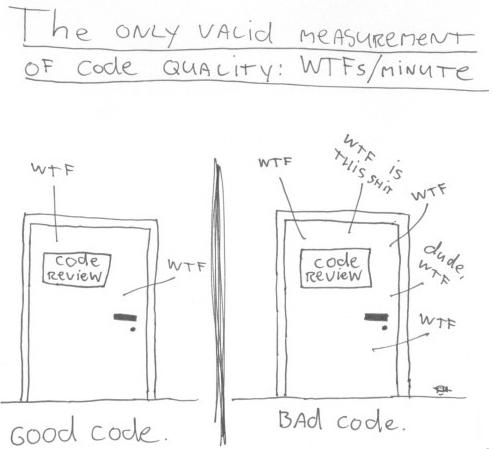
Unless what you are working on is performance-sensitive or already needs a large amount of memory, none of these metrics are useful. The code should primarily be well organized and easy to understand

Well, yes, th thing is Torvalds is right, it's a horrible metric either way. You could evaluate it's funcionality, speed, cost and a million other metrics and all of them would be better. Lines of code is absolutely meaningless.



GitHub Code Quality試したかったけど、これ無料だけど対象はOrganization所有リポジトリだけなのね docs.github.com/en/code-securi…

There were few issues with metrics, we have fixed most of them, I'll backfill it for you in a bit!
Lines of code are not a valid metric for software. Didnt you fucking listen to Linus???

It really isn't. The valid metrics are features/business value delivered, number of regressions and scalability. Focus on lines of code then maintainability drops and ends up tanking those metrics.

🎛️ Discover techniques to reduce noise, improve clarity, and eliminate nested try/catch. #CodeQuality

We examined benchmarks for 'construct validity' (how well a benchmark captures an abstract phenomenon), assessing each paper using a structured codebook of validity standards. 2/n



Lines of code only useful metric is to gauge complexity and size. It was never a good metric to value a developer by.

High-signal code reviews are a game-changer – Codex nailing precision over recall means devs spend 30-50% less time on false positives in my tests. Trade-off nailed: Scale without noise. Your biggest code review pain point?

New from our alignment blog: How we trained Codex models to provide high-signal code reviews We break down our research approach, the tradeoffs, and what we’ve learned from deploying code review at scale. alignment.openai.com/scaling-code-v…

That metric has been gone for ages. Productive error-free code is what matters.

😀Welcome to cite this article😀 Chen LG, Xiao Z, Xu YJ et al. CodeRankEval: Benchmarking and analyzing LLM performance for code ranking. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY, 40(5): 1220−1233, Sept. 2025. DOI: 10.1007/s11390-025-5514-9
CodeRankEval: Benchmarking and Analyzing LLM Performance for Code Ranking Paper: jcst.ict.ac.cn/article/doi/10… Dataset: doi.org/10.57760/scien… #LLM #CodeRanking #benchmark #dataset #EmpiricalStudy @PKU1898 @Tsinghua_Uni


When code review becomes measurable, things change: 🔹Bottlenecks become visible 🔹Patterns emerge from the noise 🔹You finally know what to fix (2/4)
Your code review process might be harming your engineering metrics. High-performing engineering teams focus on metrics like cycle time, change failure rate, and lead time for changes. (1/4)
Something went wrong.
Something went wrong.
United States Trends
- 1. Caleb 41.1K posts
- 2. Bears 57.9K posts
- 3. Packers 41.6K posts
- 4. Notre Dame 157K posts
- 5. Browns 73.3K posts
- 6. Shedeur 97.2K posts
- 7. Raiders 30.9K posts
- 8. Nixon 7,755 posts
- 9. Ravens 48K posts
- 10. #GoPackGo 7,541 posts
- 11. Parsons 5,151 posts
- 12. Josh Jacobs 3,722 posts
- 13. Stefanski 28.7K posts
- 14. ESPN 114K posts
- 15. Christian Watson 4,560 posts
- 16. Bengals 43K posts
- 17. Jordan Love 10.9K posts
- 18. Titans 35.1K posts
- 19. Josh Allen 21.6K posts
- 20. Puka 6,889 posts