#computervisionmodels 搜索结果

Say hello to DINOv3 🦖🦖🦖 A major release that raises the bar of self-supervised vision foundation models. With stunning high-resolution dense features, it’s a game-changer for vision tasks! We scaled model size and training data, but here's what makes it special 👇





new research from Meta FAIR: Code World Model (CWM), a 32B research model we encourage the research community to research this open-weight model! pass@1 evals, for the curious: 65.8 % on SWE-bench Verified 68.6 % on LiveCodeBench 96.6 % on Math-500 76.0 % on AIME 2024 🧵


Announcing our State of Generative Media Survey Report 2025! Based on responses from the community, we’ve put together a report covering the key trends in media generation adoption Responses are based on our survey of ~300 developers and creators to understand how the community…

Is computer vision “solved”? Not yet Current models score 0% on ZeroBench 🧵1/6


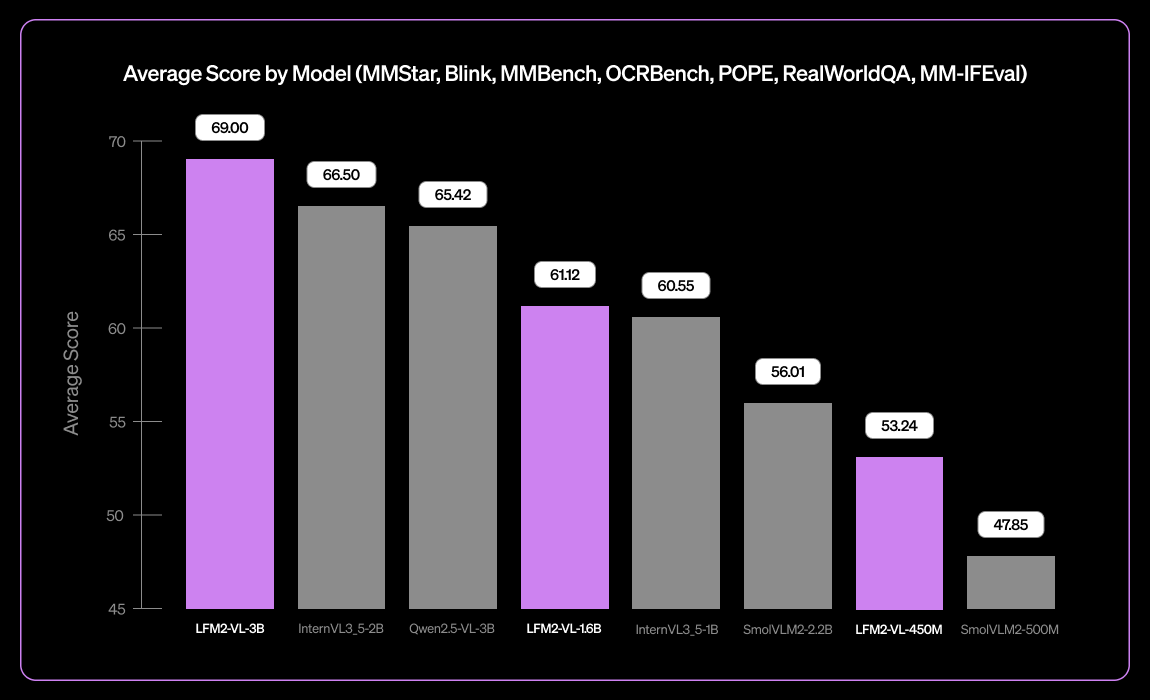
Introducing our new tiny vision language model: LFM2-VL-3B 👀 > Expanded multilingual visual understanding: English, Japanese, French, Spanish, German, Italian, Portuguese, Arabic, Chinese, Korean > 51.8% on MM-IFEval (instruction following) > 71.4% on RealWorldQA (real-world…

15 ChatGPT prompts for better research _____________ P.S. Meet Dreamina — the world’s #1 AI image model. It lets you create cinematic visuals, edit interactively, and export in 4K quality all in one seamless experience. bit.ly/MuhammadAyan


1/4 What is Computer Vision ? Computer Vision is a branch of AI that enables machines to see, identify, and process images and videos in a way similar to human vision . The goal is not just to "see" but to understand the visual world by interpreting and making decisions based…
Compute is the most valuable resource of the digital age. It’s time to redefine our digital infrastructure. Introducing @cysic_xyz Network, making the #ComputeFi vision a reality : ✅ Owned, not rented A novel Proof of Compute consensus allows contributors with computing…

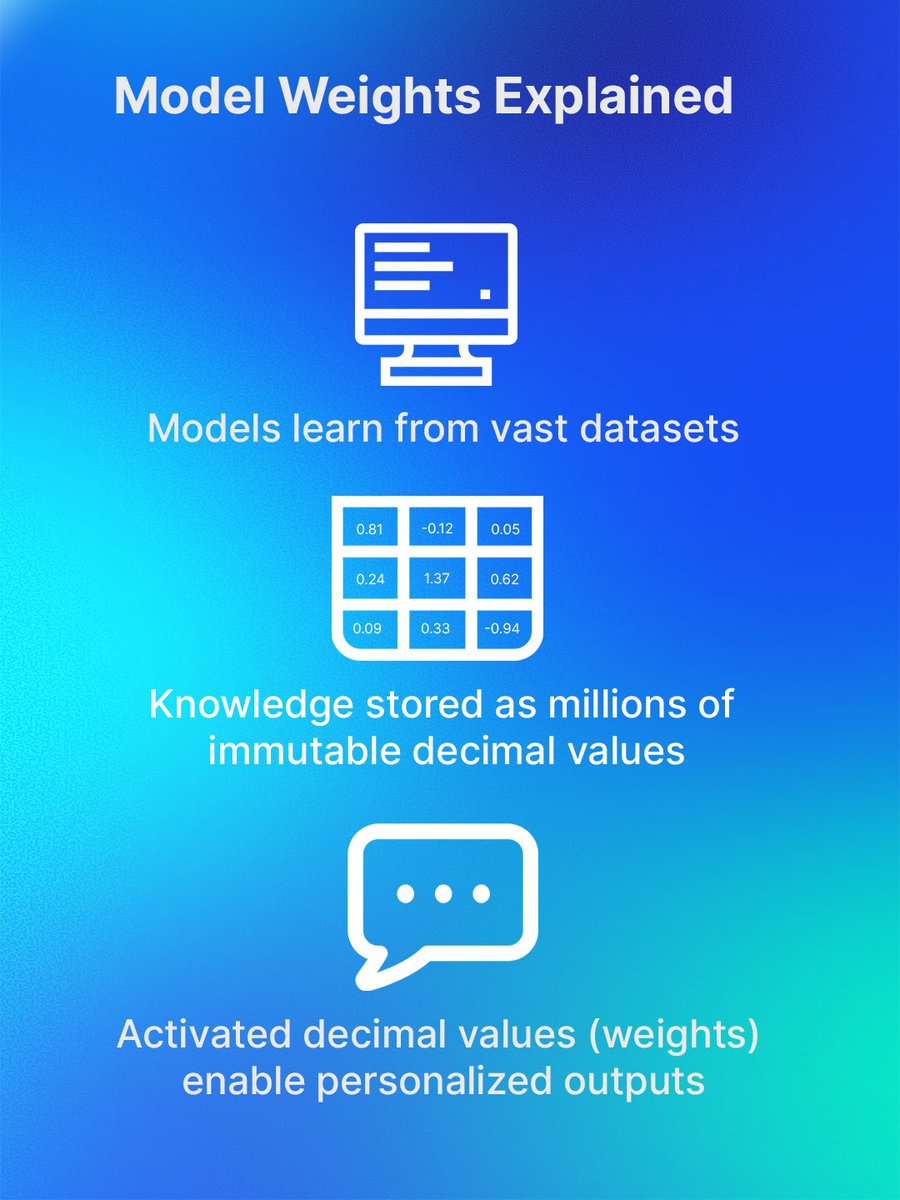
AI Models learn patterns through training, which sets fixed rules (weights). During responses, they use attention mechanisms to dynamically focus on relevant parts of your specific input.

Tired of blindly tweaking layout parameters to visualize your graph? Our #MachineLearning model builds a WYSIWYG interface for you to intuitively produce a layout you want! Check out our #IEEEVIS paper (arxiv.org/abs/1904.12225) and demo (kwonoh.net/dgl). #NetworkScience

There is no god tier video model. Ideal use cases for each model: (Full piece by @venturetwins in the a16z newsletter)


We released CWM, a 32B LLM for code reasoning, agents, and world modeling research🚀 (pre/mid/post checkpoints, tech report, RL envs, inference stack): github.com/facebookresear…. I'm fortunate to lead Agentic RL and co-lead joint RL training, empowering CWM as a reasoning agent 🧵


these are some computer vision papers that everyone must go through atleast once: 1. ResNets: arxiv.org/pdf/1512.03385… 2. YOLO: arxiv.org/abs/1506.02640 3. DeConv: lxu.me/mypapers/dcnn_… 4. GAN: arxiv.org/abs/1406.2661 5. Unet: arxiv.org/abs/1505.04597 6. Focal Loss:…

how a computer vision researcher sees the world (and solves most problems in vision).




CNNs vs. Vision Transformers vs. Hybrids: Which image classification model reigns supreme? Our latest blog breaks down the pros & cons to help you choose the right architecture! buff.ly/iTZyH5O #ImageClassification #DeepLearning #CNN


Practical #MachineLearning for #ComputerVision — End-to-End ML for Images: amzn.to/4ajfVSf ———— #BigData #DataScience #AI #DeepLearning #NeuralNetworks


Introducing DINOv3: a state-of-the-art computer vision model trained with self-supervised learning (SSL) that produces powerful, high-resolution image features. For the first time, a single frozen vision backbone outperforms specialized solutions on multiple long-standing dense…

Humans see text — but LLMs don’t. I wrote a short blog post exploring how models can perceive text visually rather than tokenize it: 🔗 csu-jpg.github.io/Blog/people_se… From PIXEL, CLIPPO, VisInContext, VIST to DeepSeek-OCR, this is a quick story of how vision-centric modeling is…

want to fine-tune models for OCR/document??? 📑 two tutorials for you 🫡 > fine-tune Kosmos2.5 with grounding: if you have data with bounding boxes + text inside > fine-tune Florence-2 on DocVQA: if you search for answers in a document plug and play with other VLMs! 💗


🤔 Wondering how your competitors use #ComputerVision solutions and whether your company could benefit from the technology, too? ⬇️ Our latest article will give you a hint! bit.ly/CV-applications #ComputerVisionApplications #ComputerVisionModels #AI


Many preventable car accidents happen each year because drivers lose focus. Car companies like #BMW are using #computervisionmodels and #annotateddatasets with #keypoints and #boundingboxes to improve driver monitoring systems and reduce accidents. #AI linkedin.com/feed/update/ur…

Top 7 Vision Models Transforming the Future of AI in 2023 bit.ly/4alBW39 #artificialintelligence #computervisionmodels #YOLO #EfficientViT #augmentation #MUnit #APIs #integrations #neuralnetwork #SmartSystems


By identifying a fundamental property called #PerceptualStraightness, #MIT researchers have made strides in training #ComputerVisionModels to learn like humans. How? By enhancing the computer's ability to represent the visual world in a predictable manner: bit.ly/448EwFT
news.mit.edu
Training machines to learn more like humans do
MIT researchers discovered that a specific training technique can enable certain types of computer vision models to learn more stable, predictable visual representations, which are more similar to...

Top 10 Platforms to Find Computer Vision Models in 2022 zcu.io/ZFnY #ComputerVision #ComputerVisionModels #TranslateVisualData #MachineLearning #Data #ComputerVisionSoftware #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine


Betterview Data Scientist Sean Ridge will be at InsurTech NY Spring Conference this year! Sean is an expert on Betterview’s #PredictiveAnalytics and #ComputerVisionModels which help #PredictAndPRevent losses. Set up time to talk with Sean today. hubs.ly/Q0153dMd0

Object-recognition dataset stumped the world’s best computer vision models news.mit.edu/2019/object-re… #Object-recognition #WorldS #ComputerVisionModels

This new Object-Recognition Dataset, ‘ObjectNet’, stumped the leading Computer Vision Models marktechpost.com/2019/12/11/thi… #ComputerVisionModels


Gregory S. Dawson, Kevin C. Desouza, and James S. Denford. Read more 👉 aikn.co/560eb0 #ExistingBiases #CommercialSystems #ComputerVisionModels #VisionModels

UNDERSTANDING ARTIFICIAL INTELLIGENCE SPENDING Read more 👉 aikn.co/517dba #CommercialSystems #ComputerVisionModels #VisionModels #Pre-trained

NONRESIDENT FELLOW - GOVERNANCE STUDIES, CENTER FOR TECHNOLOGY INNOVATION. Read more 👉 aikn.co/b2a69b #CommercialSystems #ComputerVisionModels #VisionModels #Pre-trained

Top 7 Vision Models Transforming the Future of AI in 2023 bit.ly/4alBW39 #artificialintelligence #computervisionmodels #YOLO #EfficientViT #augmentation #MUnit #APIs #integrations #neuralnetwork #SmartSystems

Make-it-3D: Generating 3D objects from a single image Through AI #AI #artificialintelligence #computervisionmodels #Design #Generating3Dobjects #implicit3Dknowledge #Limitations #llm #machinelearning #Makeit3D #reconstructingfinegeometry multiplatform.ai/make-it-3d-gen…

In comparison, faces of men were autocompleted with suits or career-related attire 42 percent of the time. Read more 👉 aikn.co/71b667 #CommercialSystems #ComputerVisionModels #VisionModels #Pre-trained

Top 10 Platforms to Find Computer Vision Models in 2022 zcu.io/ZFnY #ComputerVision #ComputerVisionModels #TranslateVisualData #MachineLearning #Data #ComputerVisionSoftware #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine
This new Object-Recognition Dataset, ‘ObjectNet’, stumped the leading Computer Vision Models marktechpost.com/2019/12/11/thi… #ComputerVisionModels
Something went wrong.
Something went wrong.
United States Trends
- 1. #SmackDown 25.7K posts
- 2. #WorldSeries 71K posts
- 3. Snell 8,941 posts
- 4. Paolo 12.2K posts
- 5. Halo 139K posts
- 6. Celtics 18.9K posts
- 7. #BostonBlue 1,723 posts
- 8. Cole Anthony 1,636 posts
- 9. #TheLastDriveIn 1,674 posts
- 10. Darryn Peterson 1,896 posts
- 11. Jade Cargill 6,441 posts
- 12. Grizzlies 3,808 posts
- 13. Knicks 22.9K posts
- 14. Purdue 6,604 posts
- 15. Kyshawn George N/A
- 16. PlayStation 65.7K posts
- 17. Hugo 46.8K posts
- 18. Yesavage 7,309 posts
- 19. Daulton Varsho 2,404 posts
- 20. Zelina 1,869 posts