#databricksbasics search results

Want to update your data in Delta tables? It's as easy as this: #DataBricksBasics #Databricks #DeltaLake #DataEngineering

Want to delete rows from your Delta table? It’s built right in: Delta Lake makes deletions as simple as SQL, with ACID guarantees. Example: Delete records where status='inactive': #DataBricksBasics #Databricks #DeltaLake #DataEngineering

Need to trace how your Delta table changed and even query its past state? Delta Lake makes it simple, Full audit trail + time travel, built right into your table. #DataBricksBasics #DeltaLake #Databricks

Your dataset’s growing fast… but so are the duplicates. In Databricks, cleaning that up is one line away Keeps only the first unique row per key no loops, no hassle, just clean data at Spark scale. #DataBricksBasics #Databricks #DeltaLake #PySpark #DataCleaning

In Databricks, an external table means: You own the data. Databricks just knows where to find it. ✅ Drop it → data stays safe ✅ Reuse path across jobs ✅ Perfect for production pipelines ⚙️ #DataBricksBasics

Need to synchronize incremental data in Delta Lake? MERGE lets you update existing rows and insert new ones in a single atomic operation. No separate update or insert steps needed. #DataBricksBasics #DeltaLake #Databricks

Want to read a Parquet file as a table in Databricks? ✅ Table auto-registered ✅ Query instantly via SQL ✅ Works with Parquet or Delta #DataBricksBasics #Databricks #DataEngineering

Got tons of Parquet files lying around but want Delta’s ACID, power versioning, time travel, and schema enforcement? You don’t need to rewrite everything just convert them in place #DataBricksBasics #DeltaLake #Databricks #DataEngineering

Performing an UPSERT in Delta is just a MERGE with both update and insert logic perfect for handling incremental or slowly changing data. One command to merge, update, and insert your data reliably. #DataBricksBasics #DeltaLake #Databricks

When is repartition(1) acceptable? Exporting small CSV/JSON to downstream systems Test data generation Creating a single audit/control file #Databricks #DatabricksDaily #DatabricksBasics
What happens when you call repartition(1) before writing a table? Is it recommended? Calling repartition(1) forces Spark to shuffle all data across the cluster and combine it into a single partition. This means the final output will be written as a single file. It is like…
5/5 Verify & start building In your workspace: You now have a working UC hierarchy. Metastore → Catalog → Schema → Table #DataBricksBasics #UnityCatalog #Databricks #Azure #DataGovernance

Ever noticed .snappy.parquet files in your Delta tables? .parquet = columnar file format .snappy = compression codec Databricks uses Snappy by default 🔹 fast to read 🔹 light on CPU 🔹 great for analytics If you want to change you can change it as below #DataBricksBasics…

1/5 Creating Unity Catalog Metastore in Azure Databricks Prep the storage Create an ADLS Gen2 account with Hierarchical Namespace (HNS) enabled. This will hold your managed tables & UC metadata. Think of it as the “hard drive” for Unity Catalog. #DataBricksBasics…

A traditional managed table is fully controlled by Databricks , It decides where to store, how to track, and even when to delete. Drop it → data & metadata gone. Simple. Safe. Perfect for exploration. #DataBricksBasics
In production, DBFS stores system files, logs, and temp artifacts NOT your business data. All production data MUST go to ADLS/S3/GCS under governance of Unity Catalog. #DatabricksBasics
Did you know every table you create in Databricks is already a Delta table? Under the hood, Databricks = Delta Lake + extras: extras = ⚙️ Photon → faster queries 🧠 Unity Catalog → access control & lineage 🤖 DLT + Auto Loader → automated pipelines #DataBricksBasics…
3/12 Project only needed columns. Drop unused columns before join. Fewer columns → smaller rows → smaller network transfer during shuffle. #DataBricksBasics
4/5 Attach workspaces In the Account Console → Workspaces, select your workspace → Assign Metastore → choose the one you created. 🧭 All data access in that workspace now flows through Unity Catalog. #DataBricksBasics #UnityCatalog #Databricks #Azure #DataGovernance
Databricks doesn’t “store” your data it remembers it 🧠 The Hive Metastore keeps track of: Table names Schema File paths When you query, Databricks looks up metadata, finds your files, and reads from storage #DataBricksBasics
8/12 Collect table statistics. Compute stats so the planner makes better decisions (e.g., whether to shuffle/hint). For Delta/Hive tables, compute statistics / column stats to aid the optimizer. #DataBricksBasics

Migrating from Redshift to Databricks: A Field Guide for Data Teams zurl.co/7n0mK

In production, DBFS stores system files, logs, and temp artifacts NOT your business data. All production data MUST go to ADLS/S3/GCS under governance of Unity Catalog. #DatabricksBasics

Databricks初心者のための完全学習ガイド:生成AI時代のデータ分析・機械学習・LLM入門 qiita.com/taka_yayoi/ite…

When is repartition(1) acceptable? Exporting small CSV/JSON to downstream systems Test data generation Creating a single audit/control file #Databricks #DatabricksDaily #DatabricksBasics
What happens when you call repartition(1) before writing a table? Is it recommended? Calling repartition(1) forces Spark to shuffle all data across the cluster and combine it into a single partition. This means the final output will be written as a single file. It is like…

Databricks Data Engineering books from @PacktDataML 1–Cookbook: amzn.to/3xbt6Gc 2–Modern Data Applications: amzn.to/3DbYgQF 3–Machine Learning: amzn.to/3XH24ld 4–Certified Developer for Apache Spark with Python: amzn.to/4fQigH8 🔵🟢🔴🔵🟢🔴





Databricks uses YAML to define metrics, aiming for human readability while maintaining machine computability. It makes a lot of sense when you're building things. #DataScience #Databricks youtube.com/watch?v=0XgHB0…

Databricks Infographic Nano Banana Pro 🍌 is an extraordinary model. [1]: Architecture Center - Databricks [2]: What is Databricks? [3]: What is Databricks and How to Use it?
![mycareersfeed's tweet image. Databricks Infographic
Nano Banana Pro 🍌 is an extraordinary model.
[1]: Architecture Center - Databricks
[2]: What is Databricks?
[3]: What is Databricks and How to Use it?](https://pbs.twimg.com/media/G6S_xK8bMAAewYl.jpg)
![mycareersfeed's tweet image. Databricks Infographic
Nano Banana Pro 🍌 is an extraordinary model.
[1]: Architecture Center - Databricks
[2]: What is Databricks?
[3]: What is Databricks and How to Use it?](https://pbs.twimg.com/media/G6S_xLGboAAG73d.jpg)

Building production data apps shouldn't mean juggling separate tools for deployment, databases, and ETL. See how Databricks Apps + Lakebase + Asset Bundles simplify the entire stack in one platform sprou.tt/1hfqS3B2OSH


Databricks users - transform your SCD1/SCD2 pipelines with Delta Lake, AUTO CDC, and Snapshot CDC for faster, cleaner, and fully automated data flows. Read the full technical guide → zurl.co/Xi0Z1 #Databricks #DeltaLake #DataEngineering #CDC #SimbusTech #Simbuzz


過去のQiita記事とClaude Codeを活用して、改めてDatabricksの学習ガイドを作りました。Databricks Free Editionやアシスタントを活用しながら徐々に理解を深めていく構成にしています。 Databricks初心者のための完全学習ガイド:生成AI時代のデータ分析・機械学習・LLM入門 qiita.com/taka_yayoi/ite…

Databricks初心者のための完全学習ガイド:生成AI時代のデータ分析・機械学習・LLM入門 qiita.com/taka_yayoi/ite… #Qiita @taka_akiより

【Databricks】Dashboard as Code: ソース管理+Lakeview APIによる新時代のAI/BIダッシュボード運用 - インテージテクノスフィア技術ブログ IT企業技術ブログ等アンテナより intage-ts.com/entry/2025/11/…


Struggling with SAP data latency, schema changes or integration complexity? 🧐 This guide from @CDataSoftware shows how to build a secure, scalable SAP → Databricks pipeline that keeps analytics fresh and reliable. sprou.tt/1GlR90RtTqe
So what does this look like in practice? Here are the 3 approaches I keep coming back to in Databricks #Databricks #DataEngineering #SCD #DataBricksBasics #DataCleaning
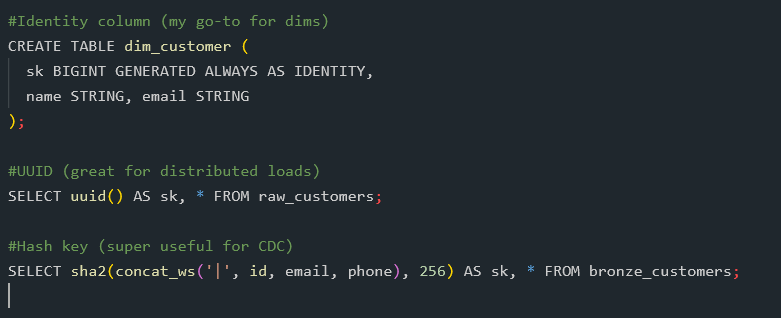
Ever had a source system change an ID halfway through a project and break all your joins? Happened to me last month… and it reminded me why surrogate keys are a lifesaver in Databricks. They give you one simple thing: a stable ID you can trust, no matter how chaotic the…

High-concurrency, low-latency data warehousing is critical for real-time decisions. Get practical guidance on architecting a production-grade warehouse. Key considerations, implementation practices, and tuning techniques to help you balance speed, scale, and cost:…
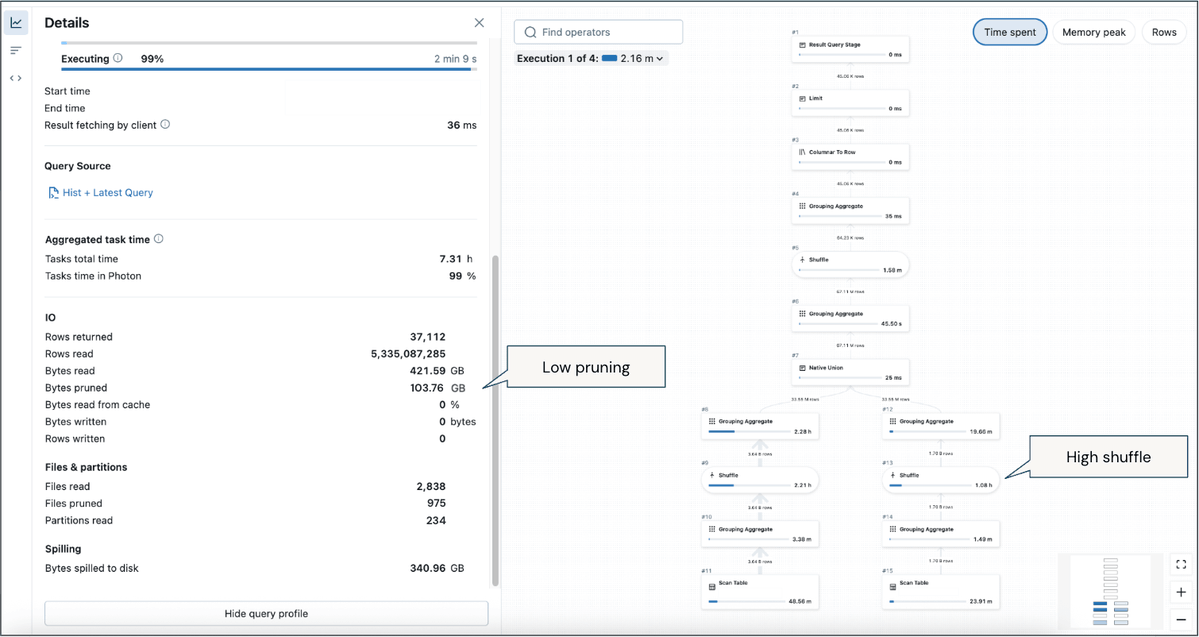

Learn how to implement end-to-end data governance and MLOps using Databricks’ Unity Catalog for secure, scalable, and compliant machine learning workflows. bit.ly/4liOOvF


Databricksが提供する「データ インテリジェンス プラットフォーム」ですが、多岐にわたる機能を前にして、「どこから手を付ければいいのか…」と悩む方も少なくないはず 今回ご紹介する『はじめてのデータブリックス』は、まさにその悩みを解消してくれる一冊でした。…


Databricks. One of the best platforms for Analytics, Data, and AI. And in this weeks lesson we are learning how to use SQL and build Visualizations! We will use SQL to get the data we need, build Visualizations in a dashboard, and work with Filters! youtube.com/watch?v=3DZQop…

youtube.com
YouTube
Analyzing Data with SQL and Visualizations in Databricks

techebo.com/databricks-ai-… Databricks AI: What the Company Does, Products, Funding, and Market Impact #Databricks #AI #bigdata #Lakehouse #MachineLearning #CloudComputing #MosaicML #DataEngineering


そんな!!!!「はじめてのデータブリックス」はこちら!!!! ぜひ読んでみてね!!! techbookfest.org/product/xk5DMn… 【実践レビュー】『はじめてのデータブリックス』を読んで Databricksの全機能を「ゼロから体験」してみた - APC 技術ブログ techblog.ap-com.co.jp/entry/2025/11/…
Need to trace how your Delta table changed and even query its past state? Delta Lake makes it simple, Full audit trail + time travel, built right into your table. #DataBricksBasics #DeltaLake #Databricks
Your dataset’s growing fast… but so are the duplicates. In Databricks, cleaning that up is one line away Keeps only the first unique row per key no loops, no hassle, just clean data at Spark scale. #DataBricksBasics #Databricks #DeltaLake #PySpark #DataCleaning
Want to delete rows from your Delta table? It’s built right in: Delta Lake makes deletions as simple as SQL, with ACID guarantees. Example: Delete records where status='inactive': #DataBricksBasics #Databricks #DeltaLake #DataEngineering
Need to synchronize incremental data in Delta Lake? MERGE lets you update existing rows and insert new ones in a single atomic operation. No separate update or insert steps needed. #DataBricksBasics #DeltaLake #Databricks
Want to update your data in Delta tables? It's as easy as this: #DataBricksBasics #Databricks #DeltaLake #DataEngineering
Performing an UPSERT in Delta is just a MERGE with both update and insert logic perfect for handling incremental or slowly changing data. One command to merge, update, and insert your data reliably. #DataBricksBasics #DeltaLake #Databricks
In Databricks, an external table means: You own the data. Databricks just knows where to find it. ✅ Drop it → data stays safe ✅ Reuse path across jobs ✅ Perfect for production pipelines ⚙️ #DataBricksBasics
1/12 Instead of accepting slow joins, tune your data & layout first. Left/right/outer joins can be heavy they usually trigger shuffles. These tips help reduce shuffle, memory pressure, and runtime on Databricks. #DataBricksBasics

Got tons of Parquet files lying around but want Delta’s ACID, power versioning, time travel, and schema enforcement? You don’t need to rewrite everything just convert them in place #DataBricksBasics #DeltaLake #Databricks #DataEngineering
Instead of doing a regular inner join... have you tried a broadcast join? ⚡ When one DataFrame is small, Spark can broadcast it to all workers no shuffle, no waiting. One keyword. Massive performance boost. #DataBricksBasics #Spark #Databricks

Want to read a Parquet file as a table in Databricks? ✅ Table auto-registered ✅ Query instantly via SQL ✅ Works with Parquet or Delta #DataBricksBasics #Databricks #DataEngineering
5/5 Verify & start building In your workspace: You now have a working UC hierarchy. Metastore → Catalog → Schema → Table #DataBricksBasics #UnityCatalog #Databricks #Azure #DataGovernance
Ever noticed .snappy.parquet files in your Delta tables? .parquet = columnar file format .snappy = compression codec Databricks uses Snappy by default 🔹 fast to read 🔹 light on CPU 🔹 great for analytics If you want to change you can change it as below #DataBricksBasics…
1/5 Creating Unity Catalog Metastore in Azure Databricks Prep the storage Create an ADLS Gen2 account with Hierarchical Namespace (HNS) enabled. This will hold your managed tables & UC metadata. Think of it as the “hard drive” for Unity Catalog. #DataBricksBasics…
Something went wrong.
Something went wrong.
United States Trends
- 1. Syracuse 7,537 posts
- 2. Mason 33K posts
- 3. #RiyadhSeason 2,294 posts
- 4. Arch Manning 2,217 posts
- 5. Oregon 26.2K posts
- 6. Stoops 1,508 posts
- 7. Harden 29.7K posts
- 8. Jeremiyah Love 3,111 posts
- 9. Joe Jackson 1,007 posts
- 10. Fran Brown N/A
- 11. Arkansas 9,352 posts
- 12. Lincoln Riley 1,045 posts
- 13. Sadiq 7,928 posts
- 14. Dante Moore N/A
- 15. #UFCQatar 73.1K posts
- 16. #TheRingIV 2,347 posts
- 17. #GoIrish 4,816 posts
- 18. Diego Pavia 1,309 posts
- 19. Maiava 1,078 posts
- 20. Kansas State 2,720 posts