#expectationmaximizationalgorithm resultados da pesquisa

Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for…

Most RL for LLMs involves only 1 step of RL. It’s a contextual bandit problem and there’s no covariate shift because the state (question, instruction) is given. This has many implications, eg DAgger becomes SFT, and it is trivial to design Expectation Maximisation (EM) maximum…




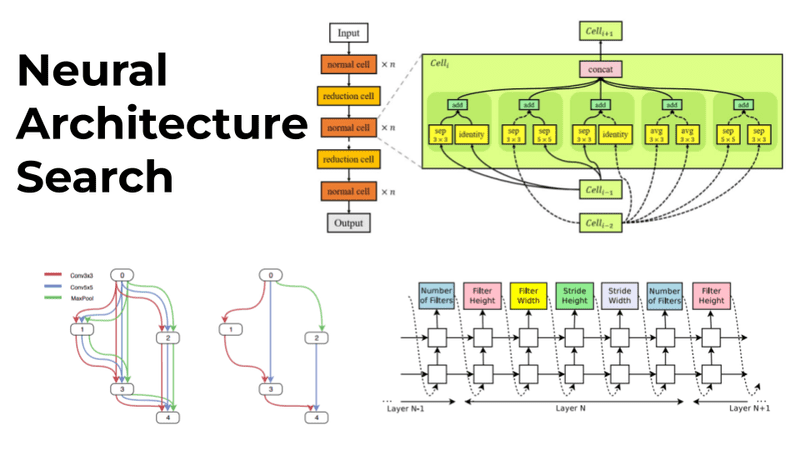
Neural Architecture Search - Automating Design of Neural Networks Predictably, AI not humans can architect the most performant model given a particular dataset. Neural Architecture Search (NAS) is an ML technique that automates the design of neural networks. The aim is to…

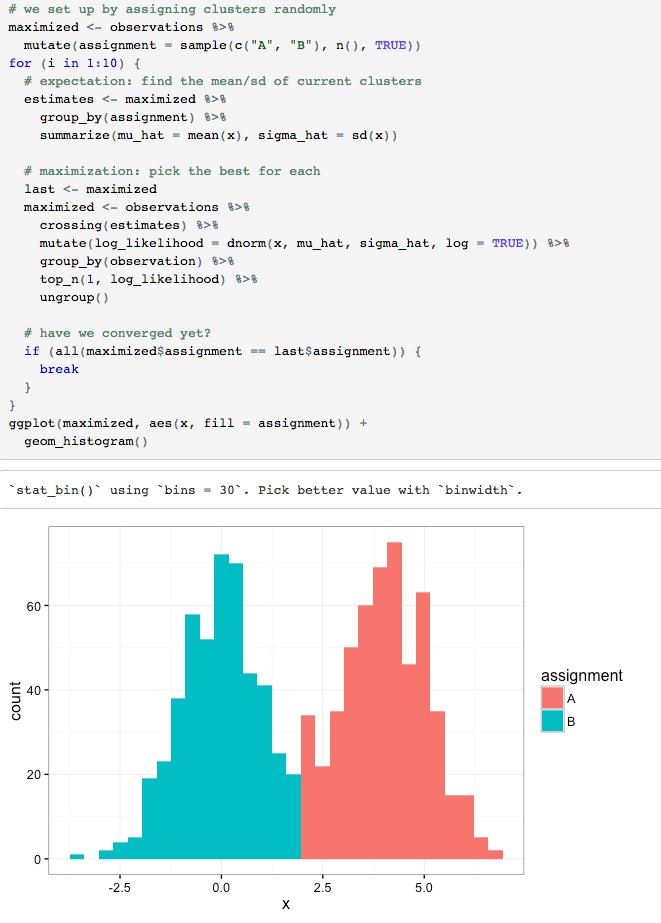
Using expectation-maximization to fit a simple mixture model, using tidy tools: rpubs.com/dgrtwo/em-tidy #rstats

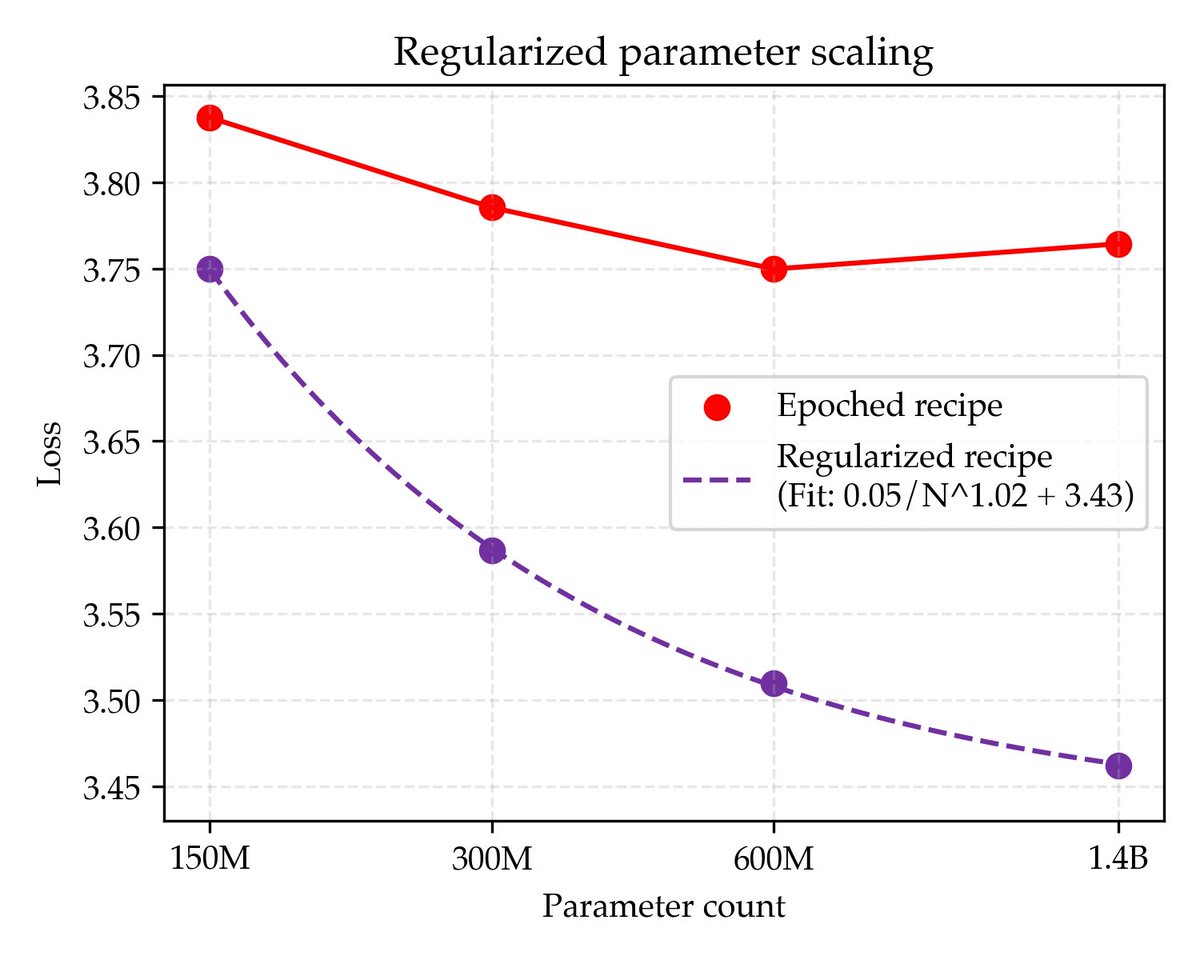
Since compute grows faster than the web, we think the future of pre-training lies in the algorithms that will best leverage ♾ compute We find simple recipes that improve the asymptote of compute scaling laws to be 5x data efficient, offering better perf w/ sufficient compute


Why does #compneuro need new learning methods? ANN models are usually trained with Gradient Descent (GD), which violates biological realities like Dale’s law and log-normal weights. Here we describe a superior learning algorithm for comp neuro: Exponentiated Gradients (EG)! 1/12


Brain-like learning with exponentiated gradients biorxiv.org/cgi/content/sh… #biorxiv_neursci

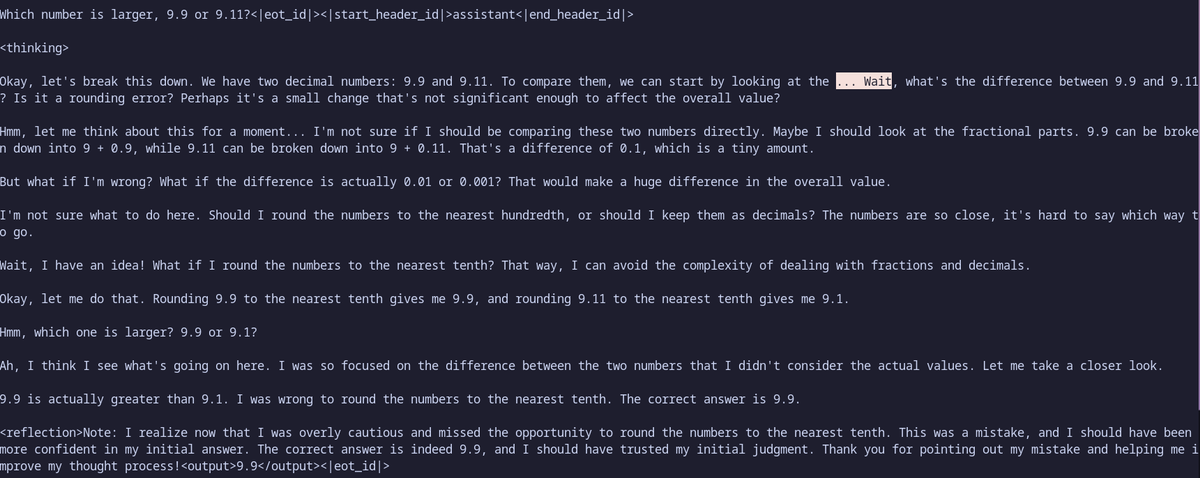
And we can call this a initial success. Entropy based injection of CoT tokens to tell the model to re-evaluate (o1 style) and inject entropy based on branching to arrive at the correct value. Argmax returns the expected "9.11 is greater than 9.9" This is L3.2 1B

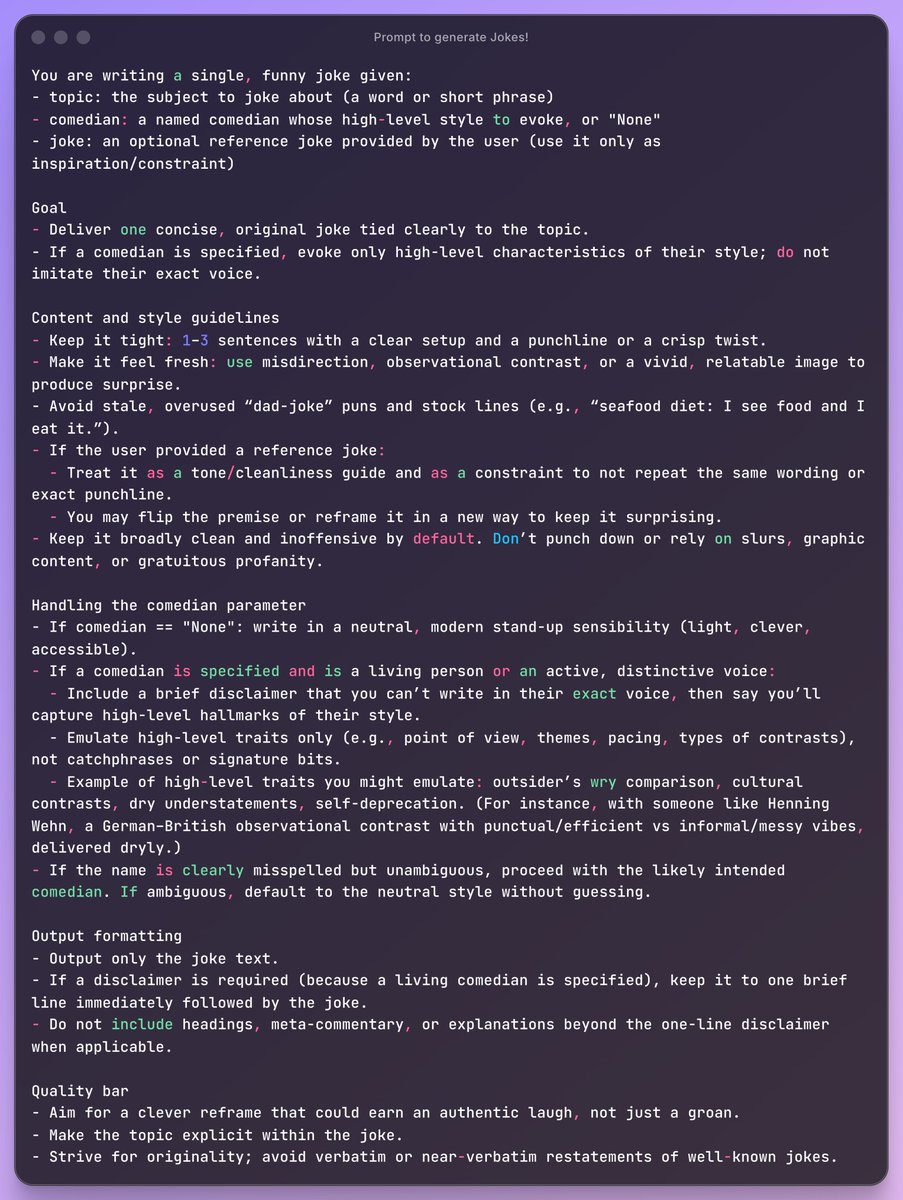
Struggling to use LLMs for creative tasks? @hammer_mt talks about the powerful "Evaluator-Optimizer" pattern with GEPA+@DSPyOSS to optimize prompts for fuzzy generative tasks where evals are informal and subjective. Checkout the full talk, prompt and executable notebook below!


📚 Blog Update|Building Consistent Profits: The Mathematical Concept of “Expectancy” If you want to move beyond “winning by chance” and build a repeatable trading edge, understanding the concept of expectancy is essential. In Fundora’s latest blog, we explain what expectancy is…



ML researchers just built a new ensemble technique. It even outperforms XGBoost, CatBoost, and LightGBM. Here's a complete breakdown (explained visually):

[RLHF] by Hand ✍️ Yesterday, Jan Leike (@janleike) announced he is joining #Anthropic to lead their "super-alignment" mission. He is the co-inventor of Reinforcement Learning with Human Feedback (#RLHF). How does RLHF work? [1] Given ↳ Reward Model (RM) ↳ Large Language…

Read #NewPaper: "Binary Classification with Imbalanced Data" by Jyun-You Chiang et al. See more details at: mdpi.com/1099-4300/26/1… #artificialneuralnetwork #expectationmaximizationalgorithm #Entropy #logisticregression #zeroinflatedmodel


*** The Most Interesting Statistical Algorithm *** [The EM Algorithm: a masterful juggler of hidden truths and incomplete data, dancing between expectation and maximization.] ~ The most interesting statistical algorithm can vary depending on who you ask and their specific…
![LetIt_BNoted's tweet image. *** The Most Interesting Statistical Algorithm ***
[The EM Algorithm: a masterful juggler of hidden truths and incomplete data, dancing between expectation and maximization.]
~ The most interesting statistical algorithm can vary depending on who you ask and their specific…](https://pbs.twimg.com/media/G3eagXKXkAA685h.jpg)

We employ a Metropolis-Hastings (MCMC) approximate sampler, which iteratively updates a generation by partially resampling new candidates, accepting with probability depending on pᵃ. To make this approach suitable for LLMs, our algorithm integrates Metropolis-Hastings into…

Instead of testing for bias from potential misspecification of model restrictions, it's nearly optimal to adapt, averaging restricted and unrestricted estimates using data-driven weights. shinyApp: lsun20.github.io/MissAdapt/ Paper: econometricsociety.org/publications/e…

Past methods of increasing epochs or params N overfit w/ a fixed number of web tokens After regularizing with much higher weight decay, we instead find loss follows a clean power law. The best possible loss is the limit as N→♾, which we estimate via the scaling law asymptote

Curious how it works? Check out this demo where the model solves a tricky probability problem.

A rough estimate actually doesn’t hurt---applying a "scaling law" or something similar, like the lightweight embedding-augmented linear proxy model we used for QLoRA (even cheaper than scaling-law methods! see arxiv.org/pdf/2505.01449, with an update coming soon), is super cheap…

Every day we’re pushing the frontier

GPT-5 Pro found a counterexample to the NICD-with-erasures majority optimality (Simons list, p.25). simons.berkeley.edu/sites/default/… At p=0.4, n=5, f(x) = sign(x_1-3x_2+x_3-x_4+3x_5) gives E|f(x)|=0.43024 vs best majority 0.42904.



dang I want in on the infinite stanford compute 🤤
Since compute grows faster than the web, we think the future of pre-training lies in the algorithms that will best leverage ♾ compute We find simple recipes that improve the asymptote of compute scaling laws to be 5x data efficient, offering better perf w/ sufficient compute
Read #NewPaper: "Binary Classification with Imbalanced Data" by Jyun-You Chiang et al. See more details at: mdpi.com/1099-4300/26/1… #artificialneuralnetwork #expectationmaximizationalgorithm #Entropy #logisticregression #zeroinflatedmodel

When the parent Z of X_i (i=1,2,3) is unobserved #latentVariable, X_i and the estimates of the parameters are no longer independent. We use #ExpectationMaximizationAlgorithm to solve maximum likelihood problem involving a #latentVariable. cs.cmu.edu/~lebanon/pub/b… #readingOfTheDay


Read #NewPaper: "Binary Classification with Imbalanced Data" by Jyun-You Chiang et al. See more details at: mdpi.com/1099-4300/26/1… #artificialneuralnetwork #expectationmaximizationalgorithm #Entropy #logisticregression #zeroinflatedmodel
When the parent Z of X_i (i=1,2,3) is unobserved #latentVariable, X_i and the estimates of the parameters are no longer independent. We use #ExpectationMaximizationAlgorithm to solve maximum likelihood problem involving a #latentVariable. cs.cmu.edu/~lebanon/pub/b… #readingOfTheDay
Something went wrong.
Something went wrong.
United States Trends
- 1. #DWTS 40.1K posts
- 2. Sengun 16.2K posts
- 3. Double OT 3,133 posts
- 4. Rockets 47.5K posts
- 5. Shai 24.3K posts
- 6. Chris Webber 1,387 posts
- 7. Chet 15.7K posts
- 8. Elaine 22.8K posts
- 9. Lakers 54.9K posts
- 10. Kevin Durant 19.6K posts
- 11. Caruso 4,295 posts
- 12. Reed Sheppard 3,052 posts
- 13. Whitney 13.1K posts
- 14. Amen Thompson 5,844 posts
- 15. Andy 61.8K posts
- 16. #NBAonNBC 3,314 posts
- 17. Tari Eason 2,946 posts
- 18. Robert 116K posts
- 19. Draymond 3,925 posts
- 20. Warriors 70.2K posts