#extractwebcrawling 搜尋結果

3. Firecrawl is an advanced, AI-powered web data extraction tool designed to turn websites into clean, structured, and LLM-ready data formats such as Markdown, JSON, and more. agentspointee.com/listing/firecr…
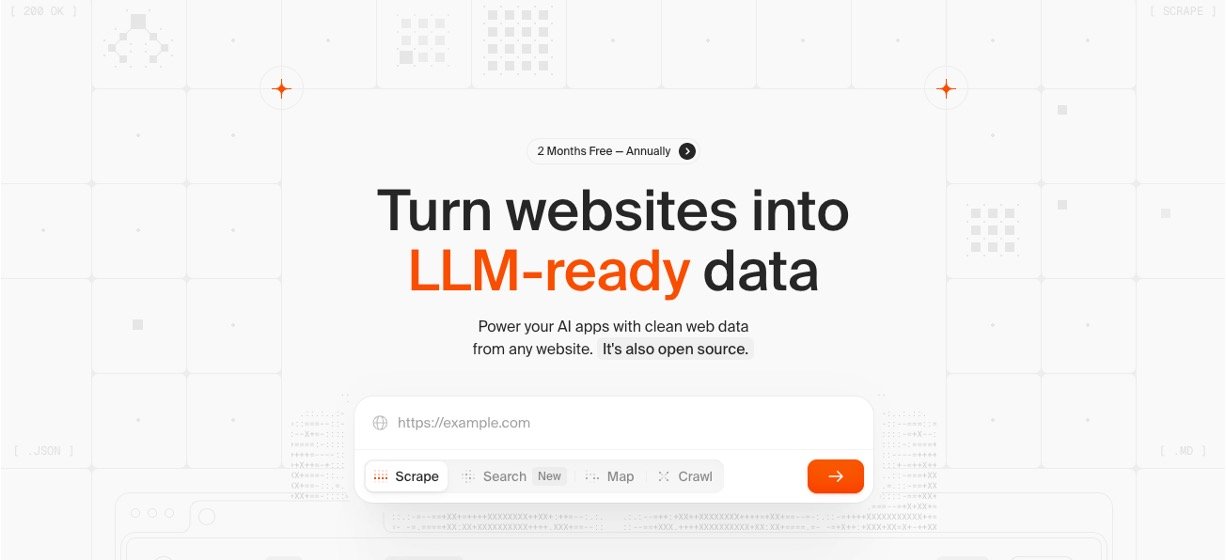
2. AI-Crawler is an advanced AI-powered web crawling tool designed to extract relevant data from websites starting from any given URL. agentspointee.com/listing/ai-cra…

another day, another new thing from @p0 - our extract API is live extract fetches any URL and returns tokens agents can actually use - dense snippets or full contents it's a tool for agents that can be used with our Search API when your agents needs more context from a single…

Today, we're launching Parallel Extract, a new API in our Agent Tools bundle. When given a URL, Extract fetches all content from that page and returns it in markdown, either in full detail or in a compressed form for better token efficiency. parallel.ai/blog/introduci…
How customers have been using Extract: - Pull complete API docs and code examples - Extract methodology from research papers - Retrieve specific sections from 10-Ks and financial filings - Get complete product details from ecom sites
Extract is built on the same proprietary web index and retrieval infrastructure that powers our Search, Task, FindAll, and Monitor APIs. This means reliable extraction from the most challenging sites— JavaScript-heavy pages, multi-page PDFs with images, and dynamic content that…
Today, we're launching Parallel Extract, a new API in our Agent Tools bundle. When given a URL, Extract fetches all content from that page and returns it in markdown, either in full detail or in a compressed form for better token efficiency. parallel.ai/blog/introduci…

The 2-click scraping is insane. Select what you want → Click extract → Done. It automatically detects patterns and grabs exactly what you need. No XPath gymnastics. No regex nightmares. Just pure, instant data extraction.

Web scraping isn’t hard when we’re by your side. Just one API call turns any URL into clean, structured data. No more patching proxies. No more battling bots. Unlock effortless scraping, get started today 💡eu1.hubs.ly/H0pP6dV0


@juliadruck inspired me with here n8n workflow check it here content.createwith.com/posts/web-scra…


Excellent article on running YaCy #DecentralizedSearch #WebScraping in a professional, secure, and scalable way for web scraping and data extraction: scrapingant.com/blog/decentral… It covers everything needed for serious deployments.


Introducing TagX’s Web Scraper — one platform to scrape it all. Collect data from: 📄 Web pages 📑 PDFs 🖼️ Images 🔗 Linked subpages Explore how TagX can power your data needs #TagX #WebScraping #DataExtraction #AI #DataAutomation #DataTools

👋 Building ultimatewebscraper.com It’s a chrome extension that allows you to easily scrape from inside your browser. Cloud version is being built at the moment 🛠️

Step 2: Enter the URL you want to scrape and tell Crawlbyte what data to extract. Product prices? Flight schedules? Reviews? Just point and click.
🚨 BREAKING: Web scraping just got 10x faster (and actually works now) - NO browser headaches - NO CAPTCHA nightmares - NO weekly maintenance hell Here's how smart developers are extracting millions of data points while you're still debugging Selenium:

automated web crawlers repeatedly visit and copy web pages to create a snapshot of a website's content at a specific time. These snapshots( text, images, and other assets, are then stored in a format like WARC (Web ARChive) for long-term preservation

3/ Use case 2: 🔍 Data Extraction! Scrape valuable information like job listings, real estate data, or contact details from *any* website. Export to spreadsheets or integrate with your favorite tools. Data at your fingertips! 📊"
🤯 Think you can't extract data from *any* website without coding? Think again! Automate web scraping with zero code and unlock insights instantly. Check out the thread 👇 #AItools #productivity #datascience
Something went wrong.
Something went wrong.
United States Trends
- 1. Josh Allen 37.6K posts
- 2. Texans 58.4K posts
- 3. Bills 151K posts
- 4. Joe Brady 5,213 posts
- 5. #MissUniverse 425K posts
- 6. #MissUniverse 425K posts
- 7. Anderson 28K posts
- 8. McDermott 4,583 posts
- 9. Troy 12.5K posts
- 10. #StrayKids_DO_IT_OutNow 48.6K posts
- 11. Maxey 13.2K posts
- 12. #TNFonPrime 3,783 posts
- 13. Cooper Campbell N/A
- 14. Dion Dawkins N/A
- 15. Al Michaels N/A
- 16. Stroud 3,649 posts
- 17. #criticalrolespoilers 2,107 posts
- 18. Costa de Marfil 25.1K posts
- 19. Shakir 5,664 posts
- 20. Fátima 190K posts