#imobench resultados da pesquisa

We just released #IMOBench, a suite of advanced math reasoning benchmarks that were instrumental in our IMO Gold effort. It tests models for their abilities to write long-form rigorous proofs, solve complex problems, and accurately grade candidate solutions.

Continuing our IMO-gold journey, I’m delighted to share our #EMNLP2025 paper “Towards Robust Mathematical Reasoning”, which tells some of the key stories behind the success of our advanced Gemini #DeepThink at this year IMO. Finding the right north-star metrics was highly

Cool figure of #Gemini3 with #DeepThink on ARC-AGI-2. The big jump looks quite like the results on #IMOBench that we obtained previously with Gemini 2.5 x.com/lmthang/status…

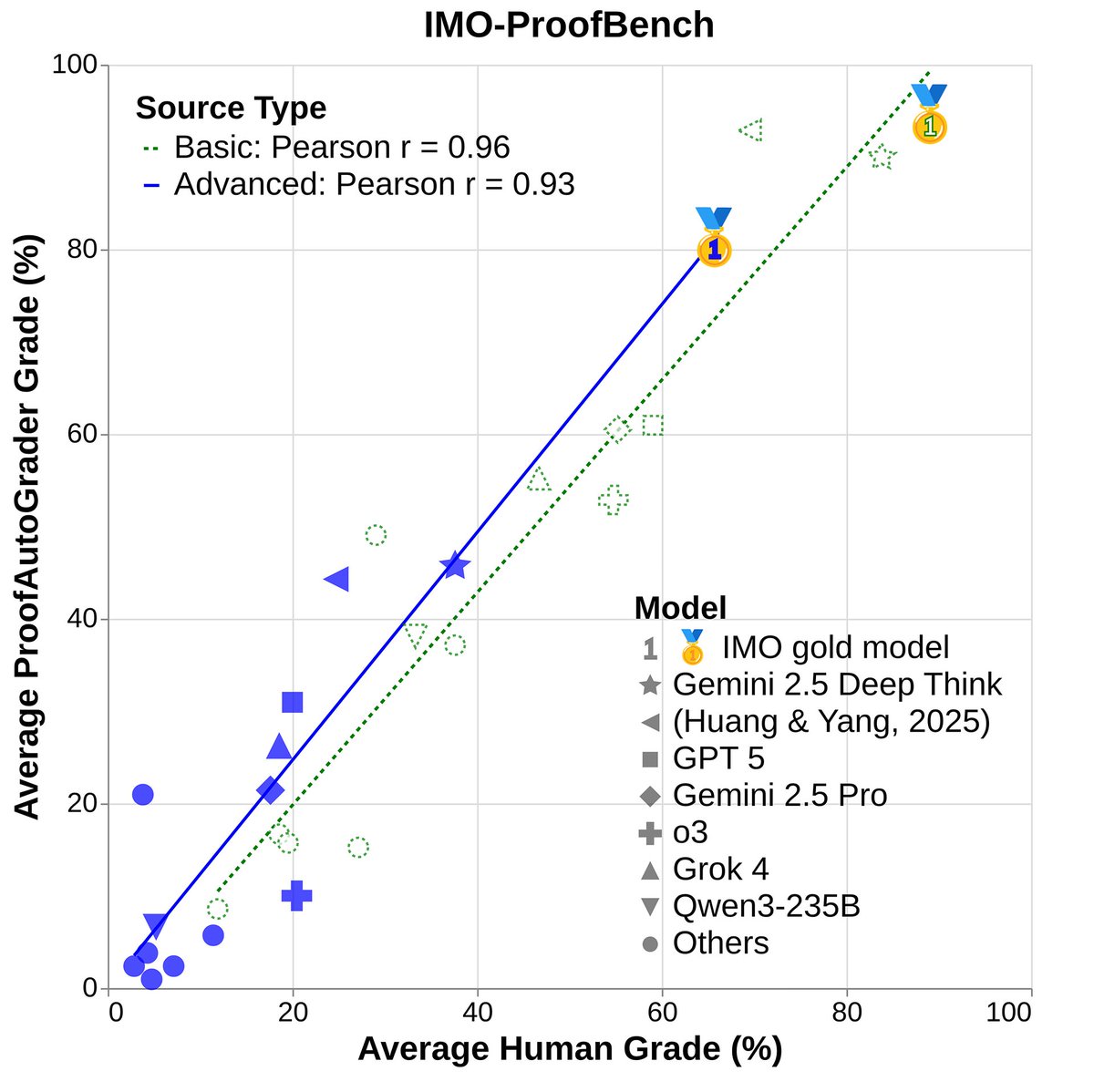
IMO-Bench consists of three benchmarks that judge models on diverse capabilities: IMO-AnswerBench, a large-scale test on getting the right answer; IMO-ProofBench, a next-level evaluation for proof writing; and IMO-GradingBench, a new benchmarkto enable further progress in
Cool figure of #Gemini3 with #DeepThink on ARC-AGI-2. The big jump looks quite like the results on #IMOBench that we obtained previously with Gemini 2.5 x.com/lmthang/status…
IMO-Bench consists of three benchmarks that judge models on diverse capabilities: IMO-AnswerBench, a large-scale test on getting the right answer; IMO-ProofBench, a next-level evaluation for proof writing; and IMO-GradingBench, a new benchmarkto enable further progress in
We just released #IMOBench, a suite of advanced math reasoning benchmarks that were instrumental in our IMO Gold effort. It tests models for their abilities to write long-form rigorous proofs, solve complex problems, and accurately grade candidate solutions.
Continuing our IMO-gold journey, I’m delighted to share our #EMNLP2025 paper “Towards Robust Mathematical Reasoning”, which tells some of the key stories behind the success of our advanced Gemini #DeepThink at this year IMO. Finding the right north-star metrics was highly

Cool figure of #Gemini3 with #DeepThink on ARC-AGI-2. The big jump looks quite like the results on #IMOBench that we obtained previously with Gemini 2.5 x.com/lmthang/status…
IMO-Bench consists of three benchmarks that judge models on diverse capabilities: IMO-AnswerBench, a large-scale test on getting the right answer; IMO-ProofBench, a next-level evaluation for proof writing; and IMO-GradingBench, a new benchmarkto enable further progress in
Something went wrong.
Something went wrong.
United States Trends
- 1. Strait of Iran N/A
- 2. #FursuitFriday N/A
- 3. #OnlyFriendsDreamOnEP8 N/A
- 4. #LastFourWatched N/A
- 5. #FanCashDropPromotion N/A
- 6. #LetterboxdFriday N/A
- 7. Kwanza Jones N/A
- 8. FISA N/A
- 9. Strait of America N/A
- 10. RED Friday N/A
- 11. PROHIBITED N/A
- 12. Chris Martin N/A
- 13. Hobi N/A
- 14. Happy Friyay N/A
- 15. First Take N/A
- 16. Completely Open N/A
- 17. Ben Shelton N/A
- 18. The Departed N/A
- 19. Clash of Clans N/A
- 20. I Feel So Free N/A