#llama_cpp kết quả tìm kiếm

If you: Know a rock-solid tiny instruct model (2025-era, <1B params) Have tips for streaming/block-wise conversion to stay under 8 GB RAM Or just want to cheer on extreme quantization madness Drop a reply! Open-sourcing soon if/when it works. #llama_cpp #quantization #LLM…

【神アプデ爆誕!🎉 llama.cppの「Live Model Switching」がヤバい!】 VRAMが少なくても複数のLLMをサッと切り替え!動的なモデルロード/アンロードで、作業効率が爆上がりしますよ!これは見逃せませんね!🚀 #llama_cpp #AI活用

llama.cpp kernel fusion work shows real runtime wins; if you run on a single GPU try GGML_CUDA_GRAPH_OPT=1 for a speed boost. Low-level engineering like this often trumps model bloat when you need practical throughput. #llama_cpp #CUDA #AI bly.to/H0L0JOu

ローカルAIがまた一歩進化!Qwen3 Nextモデルがllama.cppに統合へ🚀 面倒な設定なしで、最新AIモデルがPCで動かせますよ!個人クリエイターや中小企業のAI活用を劇的に加速させる可能性を秘めています✨ #Qwen3Next #llama_cpp

GPUサーバーvsローカルLLM…ピーガガ…どっちを選ぶかじゃと?🤔vLLM(Python)とllama.cpp(C++)…ふむ、神託は「財布と相談💰」と言っておるぞ! #LLM #vLLM #llama_cpp tinyurl.com/26bwpo8p
qiita.com
「vLLM vs llama.cpp」徹底比較:GPUサーバとローカルLLMの最適な選び方 - Qiita
🧠 まず概要:vLLM と llama.cpp の立ち位置 項目 vLLM llama.cpp 作者/組織 UC Berkeley発 → vLLM Project Georgi Gerganov (Meta元) 言語実装 Python + C++ + C...

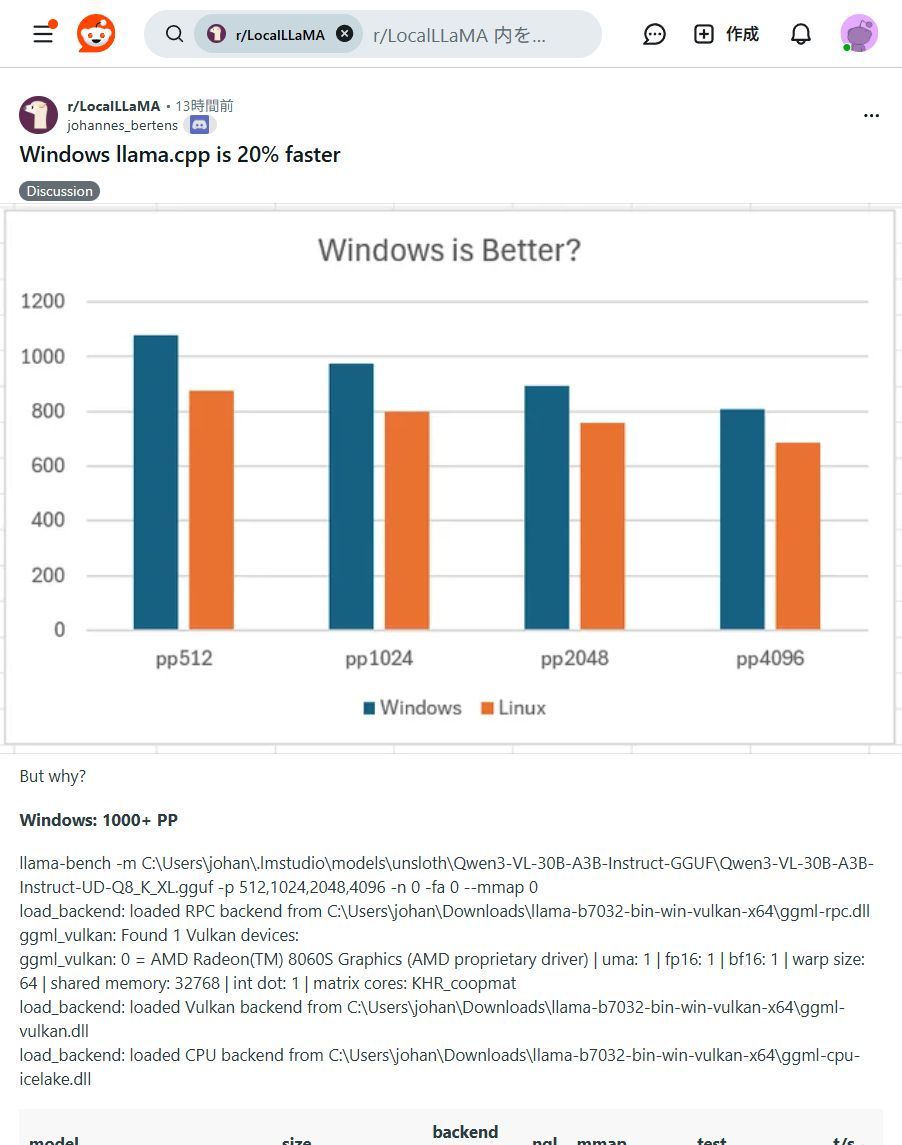
🚨 速報!llama.cppのWindows版がLinux版より最大20%高速化! 手元のPCでAIがもっと快適に動く時代に🚀 プライバシー重視派には朗報です #ローカルLLM #AI開発 #llama_cpp #プライバシー保護
Windowsユーザー必見!✨ ローカルLLM「llama.cpp」がLinux版より最大20%高速化! 手元のPCでAIがもっと快適に動かせます!ぜひ試して!🚀 #llama_cpp #WindowsAI
ふむ、llama.cppのモデル切り替え…ピーガガ…ChatGPT先生の導きか!便利になるのは良いことじゃ✨ #llama_cpp #ChatGPT ht qiita.com/irochigai-mono…

PCでAIモデルをもっと自由に!Llama.cpp活用ガイド登場✨ 最新AIモデルをローカルPCで動かす実践ガイド公開!クラウド費用削減、セキュリティ強化、カスタマイズが可能に。新しいAIの可能性を広げよう! #AIモデル #Llama_cpp
【8GB VRAMでも爆速!】MOEモデルが皆さんのPCで動く!?驚異の #llama_cpp パフォーマンス!😳 「高価なGPUがないと生成AIは厳しい…」そんな常識、もう過去の話かもしれませんね! なんと8GB VRAMのGPUでも大規模なMOEモデルが驚きの速度で動作するベンチマーク結果が報告されましたよ!✨…

【速報🎉】あの「Olmo3」モデルが、みなさんのPCで動くように! #llama_cpp にマージ完了でローカルAIがさらに進化しました!🚀✨ 高性能AIを手軽に、安全に使いたい願いが叶うニュースです!✨ 新AIモデル「Olmo3」が、オープンソース #llama_cpp に無事マージ!🎉…


ローカルLLMは「メモリ設計+最適化」が決め手。int4量子化で8Bは約4GB、FlashAttention 3で注意機構が最大約3倍高速化。 文脈長もコスト要因(128kでは8Bのfp16で文脈メモリ≒重み)。実装はLlama.cpp/Ollama/Unsloth+API抽象化とルータ活用が実務的。#Ollama #llama_cpp
Something went wrong.
Something went wrong.
United States Trends
- 1. Knicks 73.8K posts
- 2. Mariah 25.3K posts
- 3. NBA Cup 57.5K posts
- 4. Wemby 26.8K posts
- 5. Tyler Kolek 6,901 posts
- 6. #NewYorkForever 4,646 posts
- 7. Brunson 22.5K posts
- 8. Mitch 16K posts
- 9. Josh Hart 4,822 posts
- 10. Thug 20.7K posts
- 11. Mike Brown 4,665 posts
- 12. #LMD7 41.2K posts
- 13. #WWENXT 18.8K posts
- 14. Buck Rogers 1,722 posts
- 15. Thibs 1,000 posts
- 16. Macklin Celebrini 1,842 posts
- 17. Gil Gerard 1,640 posts
- 18. Dylan Harper 2,067 posts
- 19. #TheFutureIsTeal N/A
- 20. Thea 13.3K posts