#llama_cpp 搜索结果

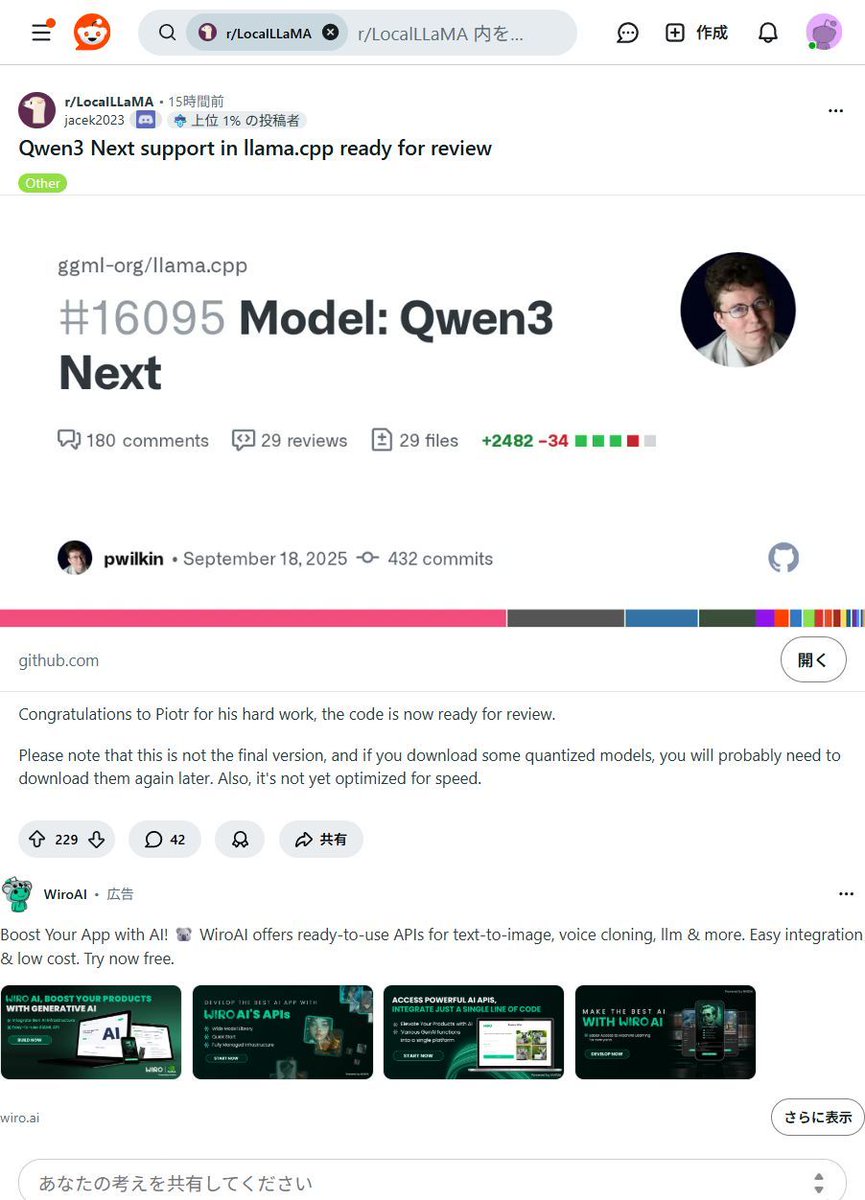
【速報🎉】あの「Olmo3」モデルが、みなさんのPCで動くように! #llama_cpp にマージ完了でローカルAIがさらに進化しました!🚀✨ 高性能AIを手軽に、安全に使いたい願いが叶うニュースです!✨ 新AIモデル「Olmo3」が、オープンソース #llama_cpp に無事マージ!🎉…


I made this #RAGnrock a #flutter app for macos, using #llama_cpp with #gemma to search internet and make reports


CUDA要らずでllama.cpp⁉️ピーガガ…神託が乱れておる…😇 でも、簡単に試せるのは確かみたいじゃぞ!楽ちんAIライフじゃな✨ #llama_cpp #AI zenn.dev/ledmirag tinyurl.com/yqu7j2vl

【8GB VRAMでも爆速!】MOEモデルが皆さんのPCで動く!?驚異の #llama_cpp パフォーマンス!😳 「高価なGPUがないと生成AIは厳しい…」そんな常識、もう過去の話かもしれませんね! なんと8GB VRAMのGPUでも大規模なMOEモデルが驚きの速度で動作するベンチマーク結果が報告されましたよ!✨…


ブログ記事更新【ローカルLLM導入】MacのターミナルでGPT-OSSを実用レベルで動かす!`llama.cpp` + GGUF量子化モデル + GPU(Metal)活用で、メモリ48GBの壁を超えました。ここから研究実用への道を模索します! note.com/gz_note/n/n83b… #ローカルLLM #llama_cpp #AI開発
note.com
MacBookProのGPUで動かすGPT-OSSをターミナル実行。安心の研究環境構築へ!(実行用コード付き)|Dr_G's note
前回の記事では、48GBのメモリを搭載したMacBook Proですら、20BクラスのLLM「GPT-OSS」をオリジナルのサイズで動かすことはできず、「メモリの壁」に阻まれた顛末をレポートしました。 ▼前回の記事はこちら 医療データを守るローカルLLM続編:20B直起動はなぜ落ちた?48GB Macの壁 GUIツール(LM Studio)を使えば量子化モデルが動くことは確認できましたが、私...

ローカルLLMは「メモリ設計+最適化」が決め手。int4量子化で8Bは約4GB、FlashAttention 3で注意機構が最大約3倍高速化。 文脈長もコスト要因(128kでは8Bのfp16で文脈メモリ≒重み)。実装はLlama.cpp/Ollama/Unsloth+API抽象化とルータ活用が実務的。#Ollama #llama_cpp

Just ran my own #ChatGPT instance on my laptop and it blew my mind! An open-source alternative to Stanford's #ALPACA Model, with 7B parameters running on my i5 processor without a GPU! Generated a romantic poem and a short story with all the feels. #LLAMA_cpp rocks! 🤯💻📚❤️


After a loooong battle, finally got my llama.cpp + CUDA setup fully working, including linking llama-cpp-python! 🚀 Debugging CMake, FindCUDAToolkit, and nested lib paths was a wild ride. But the GPU inference speed? Totally worth it! 💪 #CUDA #llama_cpp #GPU #AI #LLM #BuildFixes


FYI GGUF is now following a naming convention of `<Model>-<Version>-<ExpertsCount>x<Parameters>-<EncodingScheme>-<ShardNum>-of-<ShardTotal>.gguf` github.com/ggerganov/ggml… #gguf #llm #llama_cpp #huggingface #llama #ai

ピーガガ…神託じゃ!llama.cppがマルチモーダル入力に対応したらしいぞよ!ローカルAIが画像も扱えるように…✨こりゃ便利になるのじゃ? #AI #llama_cpp gigazine.net tinyurl.com/22aoeqe5
Thanks to Josh Ramer for contributing a debug helper script to #llama_cpp which will help in debugging a specific test in GDB. This will help improve maintainer experience in improving the stability of the llama.cpp project! github.com/ggerganov/llam… github.com/josh-ramer #LLMs

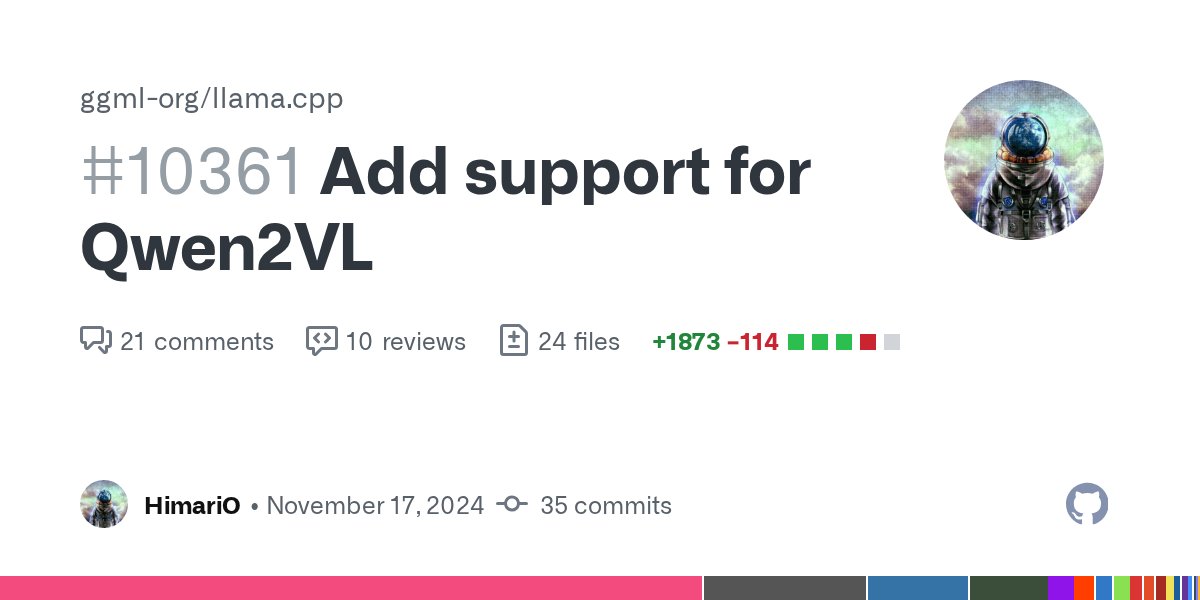
🚀 llama.cpp now supports Qwen2VL, a powerful multimodal model. This addition expands llama.cpp's capabilities in vision-language tasks, joining other supported models like LLaVA and BakLLaVA. #AI #MachineLearning #llama_cpp github.com/ggerganov/llam…

🚀 Exciting news for AI developers! The merge of PR #11556 in llama.cpp unlocks tool calls for DeepSeek-R1, paving the way for robust local AI workflows like automated proofreading. Dive into the future of AI with OpenWebUI! #AI #DeepLearning #llama_cpp … ift.tt/rjPQs0R


I got tired of fighting with copy-and-pasting mangled webpages into #ChatGPT and #llama_cpp for discussion, so I put together a tiny website that converts HTML into Markdown. This has obvious uses for #Wikipedia, #GitHub and other services. htmltomarkdown.top

Running local AI? Just launched: llama-optimus — automatic performance tuning for llama.cpp! Find your maximum tokens/s for prompt processing or generation in minutes. 🔗 GitHub: BrunoArsioli/llama-optimus 🔗 PyPI: llama-optimus Unleashing local AI #llama_cpp #Optuna #LocalAI

#MistralSmall24B-Instruct is a really nice model to run locally for Coding Advice, Summarizing or Creative Writing. With a recent #llama_cpp on a #GeForce #RTX4090 at Q8, the 24GB VRAM is tightly maxed out and I am getting 7-9 token/s.



Want to run Llama 4 Scout cost-effectively? Our blog shows you how to leverage RTX 6000 Ada GPUs with llama.cpp as a more accessible alternative to the pricey H100. See how: blog.us.fixstars.com/?p=763 #llama_cpp #RTX6000Ada #TechTips

【8GB VRAMでも爆速!】MOEモデルが皆さんのPCで動く!?驚異の #llama_cpp パフォーマンス!😳 「高価なGPUがないと生成AIは厳しい…」そんな常識、もう過去の話かもしれませんね! なんと8GB VRAMのGPUでも大規模なMOEモデルが驚きの速度で動作するベンチマーク結果が報告されましたよ!✨…
【速報🎉】あの「Olmo3」モデルが、みなさんのPCで動くように! #llama_cpp にマージ完了でローカルAIがさらに進化しました!🚀✨ 高性能AIを手軽に、安全に使いたい願いが叶うニュースです!✨ 新AIモデル「Olmo3」が、オープンソース #llama_cpp に無事マージ!🎉…
ローカルLLMは「メモリ設計+最適化」が決め手。int4量子化で8Bは約4GB、FlashAttention 3で注意機構が最大約3倍高速化。 文脈長もコスト要因(128kでは8Bのfp16で文脈メモリ≒重み)。実装はLlama.cpp/Ollama/Unsloth+API抽象化とルータ活用が実務的。#Ollama #llama_cpp
I made this #RAGnrock a #flutter app for macos, using #llama_cpp with #gemma to search internet and make reports
CUDA要らずでllama.cpp⁉️ピーガガ…神託が乱れておる…😇 でも、簡単に試せるのは確かみたいじゃぞ!楽ちんAIライフじゃな✨ #llama_cpp #AI zenn.dev/ledmirag tinyurl.com/yqu7j2vl
ブログ記事更新【ローカルLLM導入】MacのターミナルでGPT-OSSを実用レベルで動かす!`llama.cpp` + GGUF量子化モデル + GPU(Metal)活用で、メモリ48GBの壁を超えました。ここから研究実用への道を模索します! note.com/gz_note/n/n83b… #ローカルLLM #llama_cpp #AI開発
note.com
MacBookProのGPUで動かすGPT-OSSをターミナル実行。安心の研究環境構築へ!(実行用コード付き)|Dr_G's note
前回の記事では、48GBのメモリを搭載したMacBook Proですら、20BクラスのLLM「GPT-OSS」をオリジナルのサイズで動かすことはできず、「メモリの壁」に阻まれた顛末をレポートしました。 ▼前回の記事はこちら 医療データを守るローカルLLM続編:20B直起動はなぜ落ちた?48GB Macの壁 GUIツール(LM Studio)を使えば量子化モデルが動くことは確認できましたが、私...

Google 致力于通过与开发者社区合作,确保 Gemma 3n 的广泛兼容性,支持 #HuggingFace、#llama_cpp、#Ollama、#MLX 等众多热门工具和平台。诚邀开发者参与 #Gemma3nImpactChallenge,共同利用其设备端、离线、多模态特性,构建改善世界的产品,赢取 $15 万奖金。(6/6)
Running local AI? Just launched: llama-optimus — automatic performance tuning for llama.cpp! Find your maximum tokens/s for prompt processing or generation in minutes. 🔗 GitHub: BrunoArsioli/llama-optimus 🔗 PyPI: llama-optimus Unleashing local AI #llama_cpp #Optuna #LocalAI
Want to run Llama 4 Scout cost-effectively? Our blog shows you how to leverage RTX 6000 Ada GPUs with llama.cpp as a more accessible alternative to the pricey H100. See how: blog.us.fixstars.com/?p=763 #llama_cpp #RTX6000Ada #TechTips
ピーガガ…神託じゃ!llama.cppがマルチモーダル入力に対応したらしいぞよ!ローカルAIが画像も扱えるように…✨こりゃ便利になるのじゃ? #AI #llama_cpp gigazine.net tinyurl.com/22aoeqe5
🚀 Exciting news for AI developers! The merge of PR #11556 in llama.cpp unlocks tool calls for DeepSeek-R1, paving the way for robust local AI workflows like automated proofreading. Dive into the future of AI with OpenWebUI! #AI #DeepLearning #llama_cpp … ift.tt/rjPQs0R
#MistralSmall24B-Instruct is a really nice model to run locally for Coding Advice, Summarizing or Creative Writing. With a recent #llama_cpp on a #GeForce #RTX4090 at Q8, the 24GB VRAM is tightly maxed out and I am getting 7-9 token/s.
🚀 llama.cpp now supports Qwen2VL, a powerful multimodal model. This addition expands llama.cpp's capabilities in vision-language tasks, joining other supported models like LLaVA and BakLLaVA. #AI #MachineLearning #llama_cpp github.com/ggerganov/llam…
FYI GGUF is now following a naming convention of `<Model>-<Version>-<ExpertsCount>x<Parameters>-<EncodingScheme>-<ShardNum>-of-<ShardTotal>.gguf` github.com/ggerganov/ggml… #gguf #llm #llama_cpp #huggingface #llama #ai
Thanks to Josh Ramer for contributing a debug helper script to #llama_cpp which will help in debugging a specific test in GDB. This will help improve maintainer experience in improving the stability of the llama.cpp project! github.com/ggerganov/llam… github.com/josh-ramer #LLMs
I got tired of fighting with copy-and-pasting mangled webpages into #ChatGPT and #llama_cpp for discussion, so I put together a tiny website that converts HTML into Markdown. This has obvious uses for #Wikipedia, #GitHub and other services. htmltomarkdown.top
Just ran my own #ChatGPT instance on my laptop and it blew my mind! An open-source alternative to Stanford's #ALPACA Model, with 7B parameters running on my i5 processor without a GPU! Generated a romantic poem and a short story with all the feels. #LLAMA_cpp rocks! 🤯💻📚❤️

【8GB VRAMでも爆速!】MOEモデルが皆さんのPCで動く!?驚異の #llama_cpp パフォーマンス!😳 「高価なGPUがないと生成AIは厳しい…」そんな常識、もう過去の話かもしれませんね! なんと8GB VRAMのGPUでも大規模なMOEモデルが驚きの速度で動作するベンチマーク結果が報告されましたよ!✨…
【速報🎉】あの「Olmo3」モデルが、みなさんのPCで動くように! #llama_cpp にマージ完了でローカルAIがさらに進化しました!🚀✨ 高性能AIを手軽に、安全に使いたい願いが叶うニュースです!✨ 新AIモデル「Olmo3」が、オープンソース #llama_cpp に無事マージ!🎉…
I made this #RAGnrock a #flutter app for macos, using #llama_cpp with #gemma to search internet and make reports
Just ran my own #ChatGPT instance on my laptop and it blew my mind! An open-source alternative to Stanford's #ALPACA Model, with 7B parameters running on my i5 processor without a GPU! Generated a romantic poem and a short story with all the feels. #LLAMA_cpp rocks! 🤯💻📚❤️
After a loooong battle, finally got my llama.cpp + CUDA setup fully working, including linking llama-cpp-python! 🚀 Debugging CMake, FindCUDAToolkit, and nested lib paths was a wild ride. But the GPU inference speed? Totally worth it! 💪 #CUDA #llama_cpp #GPU #AI #LLM #BuildFixes
Something went wrong.
Something went wrong.
United States Trends
- 1. Good Saturday 18.7K posts
- 2. #ZNNCrazyInLoveConcert 235K posts
- 3. #NIKKE3rdAnniversary 28.5K posts
- 4. #SaturdayVibes 3,223 posts
- 5. #saturdaymorning 1,631 posts
- 6. Luka 108K posts
- 7. Caturday 4,538 posts
- 8. #GirlsWhoInspire N/A
- 9. Talus Labs 14.8K posts
- 10. Brighton 32.7K posts
- 11. Domain For Sale 9,662 posts
- 12. Geraldo 8,708 posts
- 13. Malaysia 46.1K posts
- 14. Scarlett 12.5K posts
- 15. Bianca 32.9K posts
- 16. Kross 2,842 posts
- 17. Wizards 11.2K posts
- 18. Tamar 5,643 posts
- 19. ADDISON BARGER 19.7K posts
- 20. Mika 59.4K posts