#llmobservability search results

73% of teams lack insight into LLM performance, token usage, and failures. Without observability, you risk: - Costly silent failures - Prompt degradation - User issues found via support tickets - Lack of data for model optimization solution? 👇 #LLMObservability #LLMs #AI


Langfuse is redefining how teams evaluate and optimize LLM and Agentic AI systems. #Langfuse #AgenticAI #LLMObservability #PromptEngineering #AIevaluation #OpenSourceAI #AItools #AIDevelopment #LLMops #ScalableAI #AIworkflow #AIoptimization
🧵 Why LLM traces aren’t just another API request: - Regular API: Request → Process → Response - LLM API: Request → Context → Inference → Generation → Response - Regular API: Fixed latency and cost patterns - LLM API: Latency varies with output length #LLMObservability


Are you building an advanced #LLM? bit.ly/4i9v5xf Tackle hallucinations & inefficiencies before they derail performance with #LLMobservability & monitoring. Learn to equip your teams with deep visibility to detect & optimize AL models early with Langfuse. Read our blog!
🚀 Running LLMs on your own GPU? Monitor memory, temp & utilization with the first OpenTelemetry-based GPU monitoring for LLMs. ⚡ OpenLIT tracks GPU performance automatically — focus on your apps, not hardware. 👉 docs.openlit.io/latest/sdk/qui… #LLMObservability #OpenTelemetry


Why #LLMs Need #LLMObservability & #LLMEvaluation: Monitor performance in real-time Identify strengths, optimization areas Mitigate biases for fairness Benchmark & compare LLMs Use feedback for improvements Ensure compliance & build trust Contact Us #GenAIServices #GenAISolutions


Want to build smarter, safer, and more reliable AI agents? 👉 Dive deeper at hubs.la/Q03tCGb50 #AgenticAI #LLMObservability #AIInfra #PromptEngineering #RAG #AIagents #ProductionAI #MLops #AItools #ejento.ai





@symbldotai delivers conversation intelligence as a service to builders making observability critical for smooth operations and excellent customer experience. Read what their CTO had to say about LangKit 👇 #LLM #LLMObservability #DataScience #ResponsibleAI


Today Discovr.Ai enhances LLM's With Langtrace.Ai @Langtrace #AiDomainNames #LLMobservability #AIapplicationmonitoring #open-sourceAItools #OpenTelemetry #machinelearningpipelinetracing #AImodelevaluation #Langtrace.ai #SOC2TypeIIcompliance


Unveiling #Langfuse, the open-source powerhouse for non-stop #LLMObservability! Monitor, debug, & optimize your AI with ease. Ready for seamless integration, real-time insights, and cost management? Dive in now! 🌟 #AI #OpenSource #MachineLearning

💡 Struggling to keep your AI systems in check? Performance dips, biases, and blind spots in LLM-powered applications can derail even the best systems. Enter LLM Observability! 🔗 middleware.io/blog/llm-obser… #Middleware #LLMObservability #AIOptimization #AIObservability


✔️ LLM Monitoring and Observability - A summary of techniques and approaches for responsible AI: hubs.la/Q024HW2c0 #llmobservability #llmmonitoring #largelanguagemodels #generativeai
towardsdatascience.com
LLM Monitoring and Observability | Towards Data Science
A Summary of Techniques and Approaches for Responsible AI

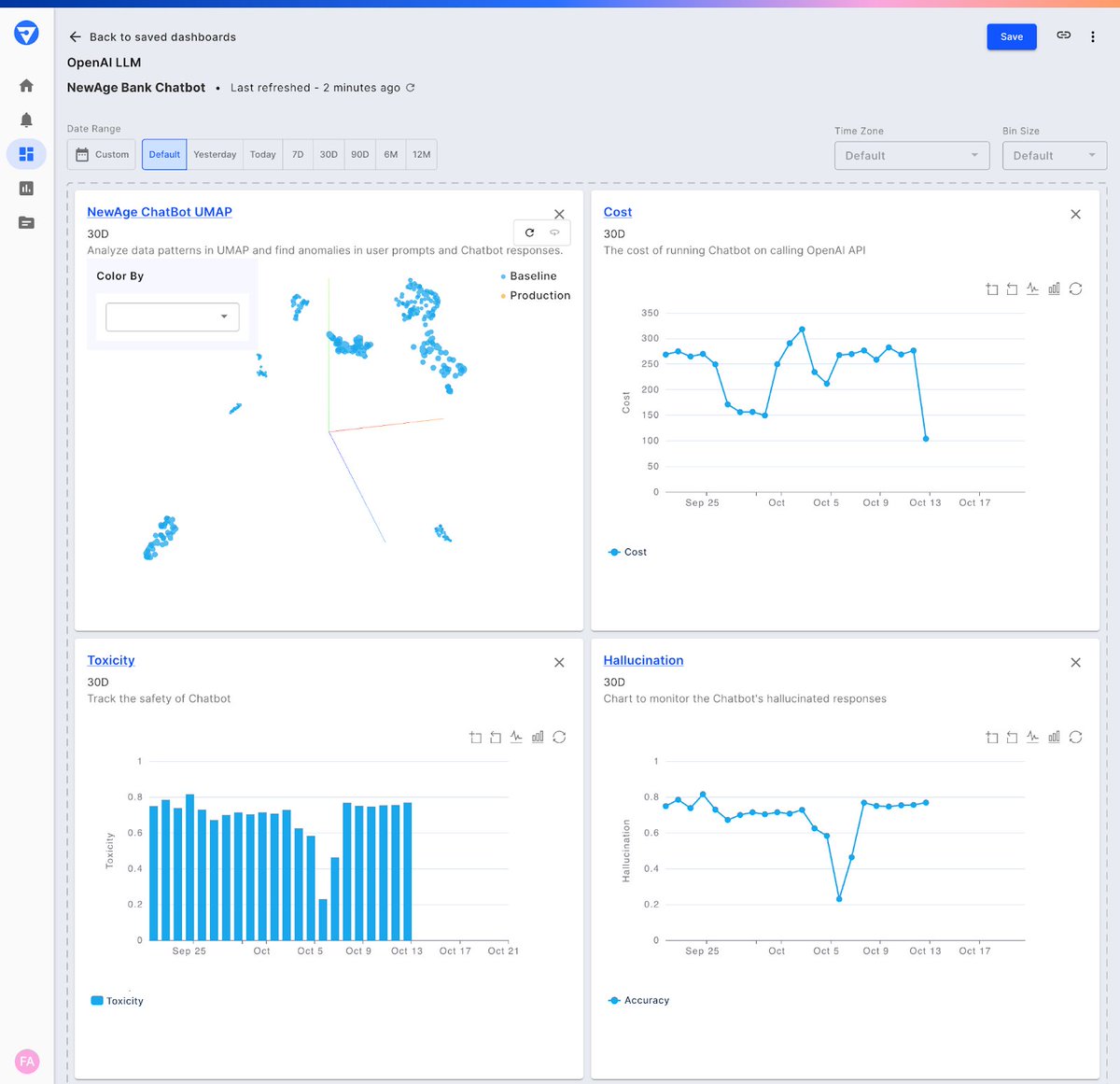
Improve your LLM apps with Fiddler's #LLMObservability platform! Featuring: 🛡️ #LLM evaluation for robustness 🌐 Real-time monitoring for #AI safety 🔍 Analytical insights with 3D UMAP 🤖 Customizable LLM metrics 📊 Improved reporting tools fiddler.ai/blog/monitor-a…

Deploying a model is easy. Deploying it responsibly means tracking every prompt, every output, every anomaly at scale. If you’re not logging what your LLMs do, you’re shipping code with your eyes shut. #AIops #LLMobservability
With LangKit, you can keep a watchful eye on your #LLM applications, ensuring smooth operations and responsible practices. Sign up for early access to the private beta now: bit.ly/3Wb50DJ #ML #LLMObservability


🎙️ Just dropped: a captivating episode of the Generation AI podcast featuring the brilliant @AstronomerAmber from @arizeai! Join us on a stellar journey from the cosmos to the core of AI, shining a light on the power of #LLMObservability. 🎧 open.spotify.com/episode/6xDZQm…

ミドルウェアが LLM オブザーバビリティと Query Genie ツールを発表 #Middleware #LLMObservability #QueryGenie #AIobservability prompthub.info/67901/
prompthub.info
ミドルウェアが LLM オブザーバビリティと Query Genie ツールを発表 - プロンプトハブ
Summary in Japanese 要約: Middlewareは、Large Language Mode

Looking for a better way to evaluate and track your LLM apps? Try out TruLens - we've just passed 10,000 downloads of our open source #LLMObservability library. And give us a star while you're at it... loom.ly/1oQECN8 #LLMapps #LLMtesting #GenAI


Langfuse isn’t the only option. Check out the Top Langfuse Alternatives & LLM Observability Tools for 2025 Compare tools like Helicone, LangSmith & TruLens for your AI stack. 👉 digitaltekblog.com/30/10/2025/lan… #Langfuse #LLMObservability #AItools #LangChain #AIDevelopers #AITrends2025

🚀 Running LLMs on your own GPU? Monitor memory, temp & utilization with the first OpenTelemetry-based GPU monitoring for LLMs. ⚡ OpenLIT tracks GPU performance automatically — focus on your apps, not hardware. 👉 docs.openlit.io/latest/sdk/qui… #LLMObservability #OpenTelemetry
🧵 Why LLM traces aren’t just another API request: - Regular API: Request → Process → Response - LLM API: Request → Context → Inference → Generation → Response - Regular API: Fixed latency and cost patterns - LLM API: Latency varies with output length #LLMObservability
Langfuse is redefining how teams evaluate and optimize LLM and Agentic AI systems. #Langfuse #AgenticAI #LLMObservability #PromptEngineering #AIevaluation #OpenSourceAI #AItools #AIDevelopment #LLMops #ScalableAI #AIworkflow #AIoptimization
73% of teams lack insight into LLM performance, token usage, and failures. Without observability, you risk: - Costly silent failures - Prompt degradation - User issues found via support tickets - Lack of data for model optimization solution? 👇 #LLMObservability #LLMs #AI
Deploying a model is easy. Deploying it responsibly means tracking every prompt, every output, every anomaly at scale. If you’re not logging what your LLMs do, you’re shipping code with your eyes shut. #AIops #LLMobservability
Are you building an advanced #LLM? bit.ly/4i9v5xf Tackle hallucinations & inefficiencies before they derail performance with #LLMobservability & monitoring. Learn to equip your teams with deep visibility to detect & optimize AL models early with Langfuse. Read our blog!
Langfuse isn’t the only option. Check out the Top Langfuse Alternatives & LLM Observability Tools for 2025 Compare tools like Helicone, LangSmith & TruLens for your AI stack. 👉 digitaltekblog.com/30/10/2025/lan… #Langfuse #LLMObservability #AItools #LangChain #AIDevelopers #AITrends2025
Something went wrong.
Something went wrong.
United States Trends
- 1. $APDN $0.20 Applied DNA N/A
- 2. $SENS $0.70 Senseonics CGM N/A
- 3. $LMT $450.50 Lockheed F-35 N/A
- 4. Good Friday 36.9K posts
- 5. #CARTMANCOIN 1,979 posts
- 6. yeonjun 277K posts
- 7. Broncos 68.5K posts
- 8. Raiders 67.2K posts
- 9. Blockchain 200K posts
- 10. #FridayVibes 2,668 posts
- 11. #iQIYIiJOYTH2026 1.51M posts
- 12. Bo Nix 18.8K posts
- 13. Geno 19.6K posts
- 14. Tammy Faye 1,824 posts
- 15. Kehlani 12K posts
- 16. MIND-BLOWING 22.8K posts
- 17. daniela 57.9K posts
- 18. John Wayne 1,151 posts
- 19. #Pluribus 3,205 posts
- 20. Danny Brown 3,386 posts