#languagemodelfinetuning 搜索结果

I will finetune large language mode, deploy it and build rag system #LanguageModelFineTuning #DeployAIModels #RAGSystem #AIDevelopment #Fiverr #Gigs #FiverrGigs #GigFiverr #BuyGigs #GigsOfTheDay #MadeOnFiverr💯 Check out my Gig ⤵️and🔃 go.fiverr.com/visit/?bta=969…

Large language models require careful operations to maximize their potential, including fine tuning and regular model updates to ensure accuracy and relevance in changing environments.

I also think we need to do more work to assess why these models are so sensitive to the specific phrasing. I've been examining this qualitatively lately but it should probably be done quantitatively: x.com/0xfdf/status/1…




Hey, no finetuning atm, just context eng. Some finetuning would be necessary to improve perf btw

Fine tuned models for specific languages would be nice! But you'll need them for specific combinations of libraries and tools as well. The drift is real and I'm not sure a fine tune will be enough. I think due to the possible combinations in code, you'll always be underfit.

How to Build and Fine-Tune a Small Language Model: A Step-by-Step Guide for Beginners, Researchers, and Non-Programmers。 1) Paper Version: amazon.com/dp/B0G3MYWTJK 2) PDF version: leanpub.com/howtobuildandf…


##LargeLanguageModels can rely on grammatical shortcuts rather than true understanding, leading to unexpected errors and potential safety risks in critical applications. New benchmarks aim to address this. @MIT @arxiv doi.org/hbcnv9 techxplore.com/news/2025-11-l…


yesterday completed learn.deeplearning.ai/courses/finetu… learned about finetuning llms to respond in certain ways, save the model, use inference. it won't help solve accuracy but it will help solve the way llms respond in a certain way.

AIモデルのファインチューニングは、その名の通り、特定のタスクに合わせてAIを微調整するプロセスです🌸基本的に、大まかな知識を持ったモデルを用意して、そこに新しいデータを加えることで、特定の目的により適したAIを作るんです。例えば、一般的な言語モデルを使って、特定の業界の専門用語を学ば…
you're not a real ML engineer if you've never finetuned a model stop API-maxxing and actually train something challenge [IMPOSSIBLE] github.com/nikhilkulkarni…
![nsk1755's tweet image. you're not a real ML engineer if you've never finetuned a model
stop API-maxxing and actually train something challenge [IMPOSSIBLE]
github.com/nikhilkulkarni…](https://pbs.twimg.com/media/G6guEU0asAALt0V.png)

4. Fine-tuning You reshape a general model into your model. Brand voice, industry language, workflows—encoded into weights. This is how companies create “AI that feels like us.”

4. Fine-tuning You reshape a general model into your model. Brand voice, industry language, workflows—encoded into weights. This is how companies create “AI that feels like us.”

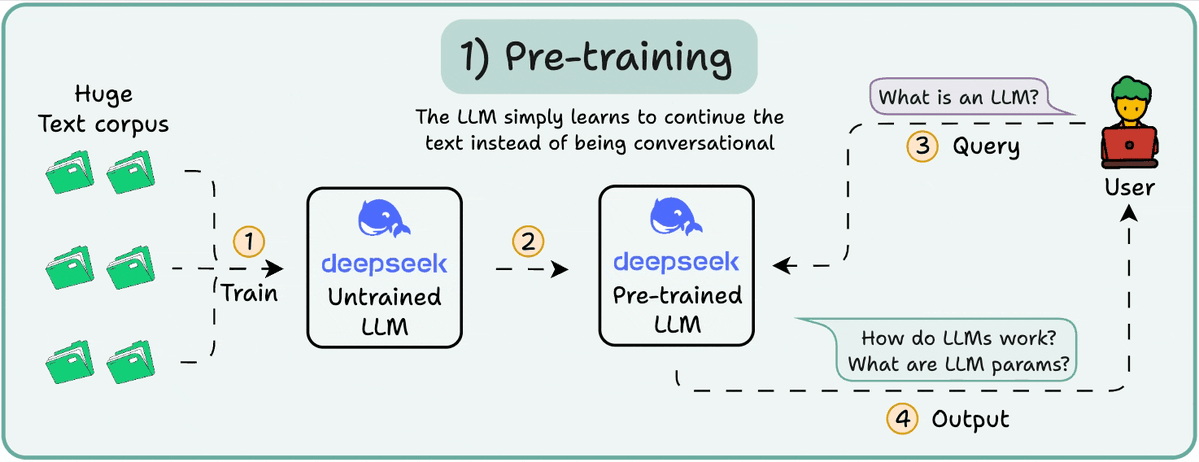
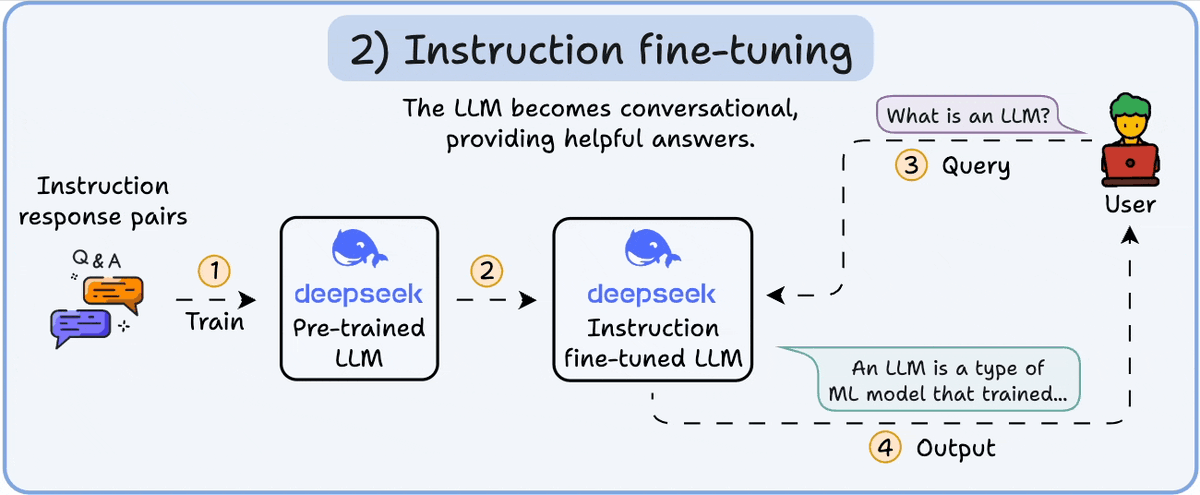
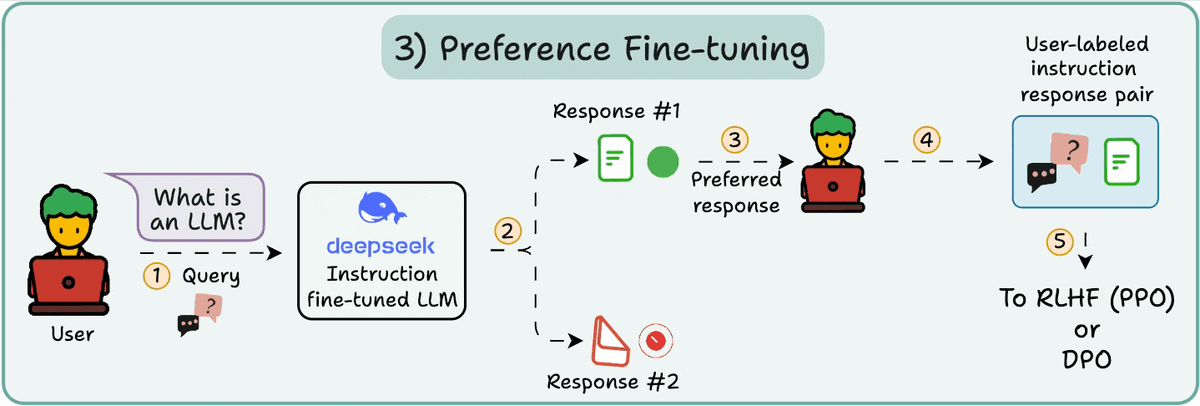
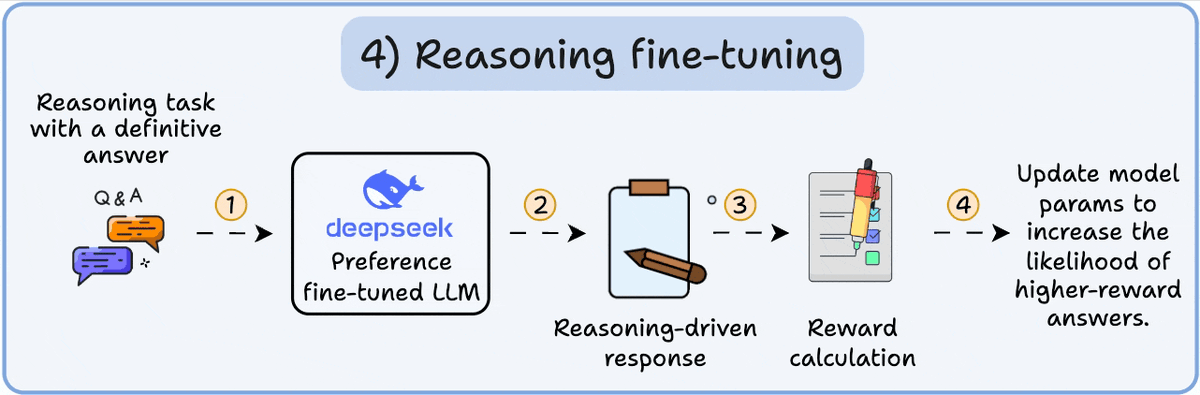
There are primarily 4 stages of building LLMs from scratch: - Pre-training - Instruction fine-tuning - Preference fine-tuning - Reasoning fine-tuning Let's understand each of them! 0️⃣ Randomly initialized LLM At this point, the model knows nothing. You ask it “What is an…

This highlights a core issue: model fine-tuning can prioritize “task completion” over context preservation, making precise edits harder than the raw output suggests.

Pre-trained and fine-tuned, which mean to pre-train a Large Language Model for a general purpose with a large dataset and then fine-tune it for specific aims with a much smaller dataset. #AIFundamentalNotes

⭕️ Check out MultiLLM debate this new paper "Boosting Large Language Models with Mask Fine-Tuning": ⭕️ Moderator Consensus: Main Points and Reasoning Flaws Main Points Identified All participants agree the paper introduces Mask Fine-Tuning (MFT): a post-fine-tuning method that…


3️⃣ Fine-Tuning Starting from a strong foundation model and adjusting several layers with large domain-specific data. Think of it like: An experienced professional taking advanced, industry-specific training to master a niche skill. They already know the fundamentals.

今天尝试了一下 Fine-tuning,用 unsloth 这种库让整个流程异常的简单,基本上就是准备好数据和system prompt,应用一下对话模版,tokenized 一下,然后丢进去训练就行了。最大的问题是 GPU 资源太贵(

LLM Fine-tuning techniques I’d learn if I wanted to customize them: Bookmark this. 1.LoRA 2.QLoRA 3.Prefix Tuning 4.Adapter Tuning 5.BitFit 6.P-Tuning v2 7.Soft Prompts 8.Instruction Tuning 9.RLHF 10.DPO (Direct Preference Optimization) 11.RLAIF (AI Feedback) 12.Multi-Task…

Unsloth has a great guide on fine tuning LLMs. > selecting the right model > preparing your own data > understanding quantisation, lora > training params & hyperparams > evaluation An SLM fine tuned for a specific task often shows better results than using a generic LLM. Fine…

Something went wrong.
Something went wrong.
United States Trends
- 1. Ravens 52.8K posts
- 2. Ravens 52.8K posts
- 3. Ravens 52.8K posts
- 4. Lamar 42.1K posts
- 5. Joe Burrow 17.5K posts
- 6. Zay Flowers 3,821 posts
- 7. #WhoDey 3,240 posts
- 8. Cowboys 88.5K posts
- 9. Derrick Henry 4,278 posts
- 10. Zac Taylor 2,520 posts
- 11. Perine 1,486 posts
- 12. Harbaugh 2,766 posts
- 13. #CINvsBAL 2,526 posts
- 14. AFC North 2,084 posts
- 15. Mahomes 32.7K posts
- 16. Cam Boozer 2,010 posts
- 17. #heatedrivalry 5,648 posts
- 18. Sarah Beckstrom 192K posts
- 19. Tanner Hudson 1,229 posts
- 20. Chase Brown 2,641 posts