#largescalewebscrapingservices search results

The Essential Tools for Effective Web Scraping #webscraping #proxy #api #dataextraction #brightdata plainenglish.io/community/the-…
plainenglish.io
The Essential Tools for Effective Web Scraping
Discover the key to successful web scraping in this guide. Learn advanced techniques and strategies to effectively gather and utilize data from the web, enhancing your data analysis and business...

🚀Launching a full LLM Chat data-scraping suite from Scrapeless — browser source code now on GitHub (ChatGPT, Perplexity, Gemini). Try, fork, and plug it into your projects. ⭐️API version (faster + more stable) coming soon. 👉 github.com/scrapelesshq/L… #LLM #AI #OpenSource…


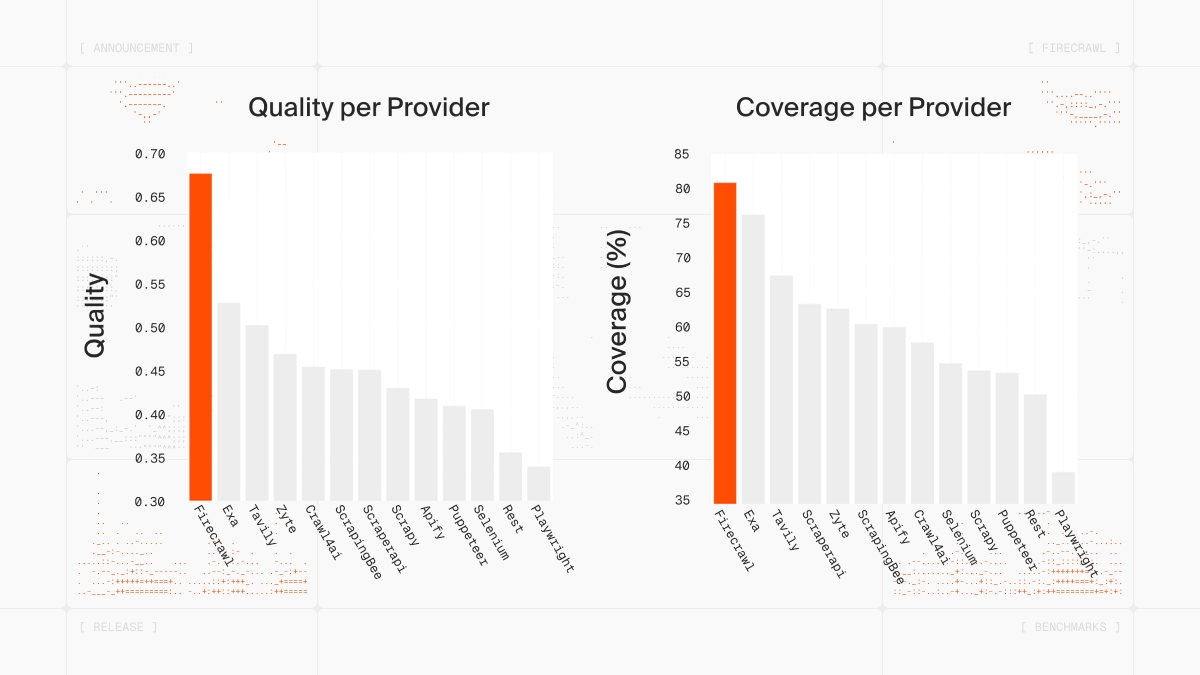
We rebuilt our infra from the ground up to achieve the highest web scraping quality Today we are excited to open source our evaluation framework for coverage and quality 🔥

Introducing scrape-evals - our evaluation framework for web scraping 📊 For v2.5 we rebuilt our entire infrastructure to achieve state-of-the-art data capture across the web, and now Firecrawl has the highest quality and coverage. Today we're open sourcing the evals 🔥

Whether it's done by #AI agents or #searchengines, the #scraping of content presents a very real threat to the #business model of many independent publishers operating on the #WorldWideWeb..

With basic web knowledge, guidance, and examples, even non-coding journalists can build a scraper with large language models. Originally published by the @pulitzercenter. twp.ai/4isz79


Web scraping isn’t hard when we’re by your side. Just one API call turns any URL into clean, structured data. No more patching proxies. No more battling bots. Unlock effortless scraping, get started today 💡eu1.hubs.ly/H0pP6dV0


Check out my Gig on Fiverr: do web scraping, google map scraping, website scraping and data scraping fiverr.com/s/38jKpPm

@juliadruck inspired me with here n8n workflow check it here content.createwith.com/posts/web-scra…


5. Bulk Scraping Paste up to 2,000 URLs and let Thunderbit extract data from all of them in one go — fast, accurate, and fully automated.

Excellent article on running YaCy #DecentralizedSearch #WebScraping in a professional, secure, and scalable way for web scraping and data extraction: scrapingant.com/blog/decentral… It covers everything needed for serious deployments.


For 1 flat monthly fee you can scrape millions of records and find out: - What tools a website is built with - All eCom sites by product category - All websites by keyword - Much more


Introducing TagX’s Web Scraper — one platform to scrape it all. Collect data from: 📄 Web pages 📑 PDFs 🖼️ Images 🔗 Linked subpages Explore how TagX can power your data needs #TagX #WebScraping #DataExtraction #AI #DataAutomation #DataTools

👋 Building ultimatewebscraper.com It’s a chrome extension that allows you to easily scrape from inside your browser. Cloud version is being built at the moment 🛠️

n8n Web Scraping || Part 2: Pagination, Infinite Scroll, Network Capture & More cstu.io/68239e


🚨 BREAKING: Web scraping just got 10x faster (and actually works now) - NO browser headaches - NO CAPTCHA nightmares - NO weekly maintenance hell Here's how smart developers are extracting millions of data points while you're still debugging Selenium:

Discover the 12 best web scraping APIs of 2025, comparing performance, pricing, features, & success rates to help teams scale reliable data extraction. Read @Oxylabs_io's deep dive: hackernoon.com/12-best-web-sc…


For 1 flat monthly fee you can scrape millions of records and find out: - What tools a website is built with - All eCom sites by product category - All websites by keyword - Much more Yes, you'll get contact info. Scrape as much as you can for 1 month and then cancel.…


🤯 Think you can't extract data from *any* website without coding? Think again! Automate web scraping with zero code and unlock insights instantly. Check out the thread 👇 #AItools #productivity #datascience

✓ See requests, success, & credits per domain. ✓ Drill-down into latency & concurrency data. ✓ Success & failure charts for each target site or domain. ✓ Powerful filters via location, product type (API, Async), params, etc.

📌 Want the exact process we used to scrape 650K e-commerce stores and generate $10M in pipeline? Full breakdown (with tools, tactics, and data enrichment strategies): newsletters.leadlypro.io/scraping-ecom-…
Something went wrong.
Something went wrong.
United States Trends
- 1. #SmackDown 40.1K posts
- 2. Mamdani 403K posts
- 3. Reed Sheppard 2,535 posts
- 4. Norvell 2,529 posts
- 5. Florida State 10.2K posts
- 6. Marjorie Taylor Greene 52.2K posts
- 7. NC State 4,987 posts
- 8. #BostonBlue 3,710 posts
- 9. #OPLive 2,165 posts
- 10. Syla Swords 2,806 posts
- 11. Azzi 15.2K posts
- 12. Derik Queen 4,395 posts
- 13. Aiyuk 5,846 posts
- 14. The View 97.1K posts
- 15. Sengun 6,050 posts
- 16. #LasVegasGP 49.2K posts
- 17. Devin Booker 1,154 posts
- 18. Dillon Brooks 1,693 posts
- 19. UConn 6,925 posts
- 20. Purdue 5,068 posts