#model_predictive_control resultados da pesquisa

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

🎉 Diffusion-style annealing + sampling-based MPC can surpass RL, and seamlessly adapt to task parameters, all 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴-𝗳𝗿𝗲𝗲! We open sourced DIAL-MPC, the first training-free method for whole-body torque control using full-order dynamics 🧵 lecar-lab.github.io/dial-mpc/

腕立て伏せとバーピーをする、ボストン・ダイナミクスの電動アトラス youtu.be/aQi6QxMKxQM #MPC #Model_Predictive_Control #Electric_Atlas #humanoid #robot #RSS

Most AI models react. @BUZZHPC’s Agentic AI takes action. It plans, remembers, learns, and self-corrects, executing real workflows with autonomy and safety built in. This is the future of intelligent automation 🧵⬇️


Mom, my paper has been cited by @thinkymachines !

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

Time-series forecasting - AI to predict the future While LLMs and Gen AI have received a lot of attention, state-of-the-art (SOTA) time-series forecasting models almost seem magical when they can predict a future value with high accuracy. They are used to predict stock prices,…


"Deep Operator Neural Network Model Predictive Control," by Thomas O. de Jong; Khemraj Shukla; Mircea Lazar Date: 26 Sept 2025 Link: ieeexplore.ieee.org/document/11181… #predictivecontrol #neuralnetworks #constrainedcontrol #vectors #controlsystems #ojcsys


[1/9] While pretraining data might be hitting a wall, novel methods for modeling it are just getting started! We introduce future summary prediction (FSP), where the model predicts future sequence embeddings to reduce teacher forcing & shortcut learning. 📌Predict a learned…

Thinky cooked Beating 18,000 hours of RL with just 1800 hours of on policy distillation and OPEN SOURCE it

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

▶️You can read the full post here: realpars.com/blog/pid-vs-ad… What sets #PID Control apart in automated systems? We compare it with #Fuzzy_Logic and #Model_Predictive_Control Check out the link for a free consultation: realpars.com/for-teams

You have got a point forecasting model, but having point forecasting model is clearly not sufficient. How does one turn point forecasting model into a probabilistic forecasting model? Is it even possible? There are only two choices really: 1) [Intrusive] change loss…
![predict_addict's tweet image. You have got a point forecasting model, but having point forecasting model is clearly not sufficient.
How does one turn point forecasting model into a probabilistic forecasting model? Is it even possible?
There are only two choices really:
1) [Intrusive] change loss…](https://pbs.twimg.com/media/F0i1jvHWIAISAAf.jpg)




We present a new approach to time-series forecasting that uses continued pre-training to teach a model to adapt to in-context examples at inference time, matching the performance of supervised fine-tuning without additional complex training. Learn more at goo.gle/3Vwpp6F

Swing-up of the double inverted pendulum on a cart using a receding horizon-model predictive control. While classical controllers struggle, the efficacy of MPC in such a problem, is insane. Swinging up is inherently complex as the system starts off far from its linear regime.

I’m increasingly convinced that dense supervision or sturdier critics are coming back.
Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

wow, only if there was rl algorithms that had (self) distillation term for reverse kld. that everyone trying to remove tldr: replace pi_ref with pi_teacher you get on policy distillation

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

#MachineLearning #QOC Introducing a data-driven approach to quantum optimal control (QOC) using a neural network surrogate model. Our method effectively captures system dynamics and adapts to varying conditions, enhancing QOC for real-world applications. cpl.iphy.ac.cn/article/doi/10…


distillation is the sincerest form of flattery

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…


On-policy distillation with reverse KL as reward works great—IF you have access to teacher logits. But what if you don't? What if you want to distill from multiple teachers? Our solution: distill teacher guidance into rubrics, then do on-policy RL. Check out our work:…
Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

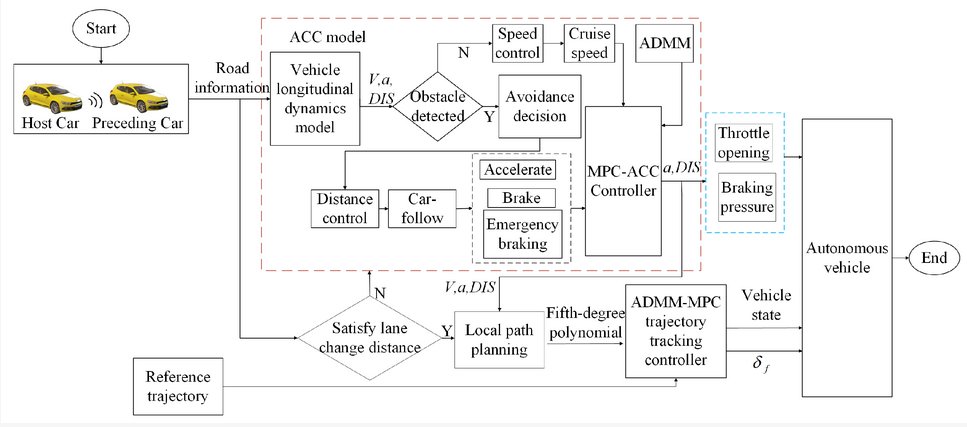
Collision Avoidance Path Planning and Tracking Control for Autonomous Vehicles Based on Model Predictive Control mdpi.com/1424-8220/24/1… #trajectory_tracking #model_predictive_control
腕立て伏せとバーピーをする、ボストン・ダイナミクスの電動アトラス youtu.be/aQi6QxMKxQM #MPC #Model_Predictive_Control #Electric_Atlas #humanoid #robot #RSS

Controller Design for Air Conditioner of a #Vehicle with Three Control Inputs Using #Model_Predictive_Control by Trevor Parent, Jeffrey J. Defoe and Afshin Rahimi 👉mdpi.com/2673-3951/5/1/8 #simulation

▶️You can read the full post here: realpars.com/blog/pid-vs-ad… What sets #PID Control apart in automated systems? We compare it with #Fuzzy_Logic and #Model_Predictive_Control Check out the link for a free consultation: realpars.com/for-teams

🔓Free Article: A novel multi-objective tuning strategy for model predictive control in trajectory tracking 📆Free access until 17 February 2024 #Autonomous_vehicle #Model_predictive_control #Tuning_parameters #Trajectory_tracking #SpringerLink: link.springer.com/article/10.100…

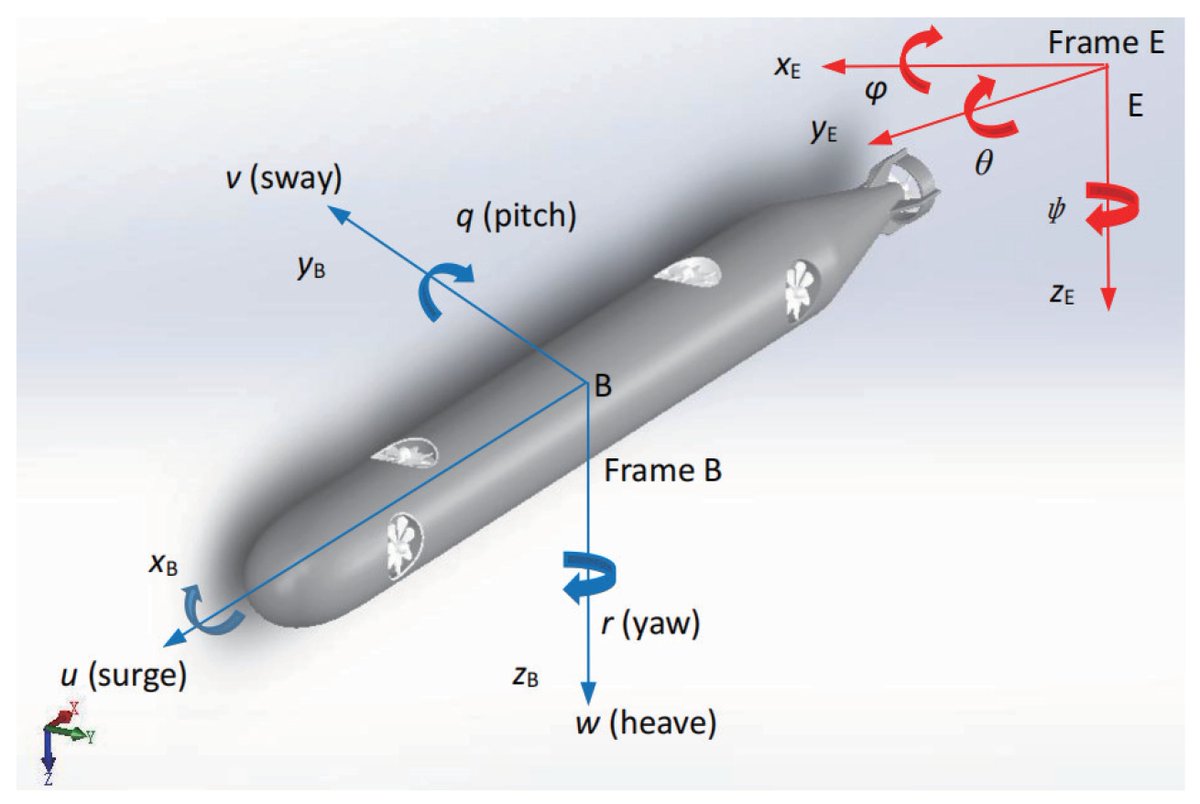
#highlycitedpaper Modeling and Trajectory Tracking Model Predictive Control Novel Method of AUV Based on CFD Data mdpi.com/1424-8220/22/1… @xyl85615557 #autonomous_underwater_vehicle #model_predictive_control #trajectory_tracking #normal_probability_division #GA_ACO_algorithm
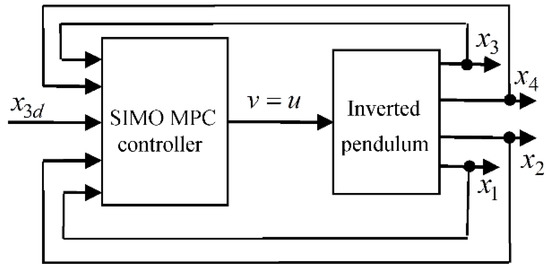
Stabilization of the Cart–Inverted-Pendulum System Using State-Feedback Pole-Independent MPC Controllers mdpi.com/1424-8220/22/1… @Univ_20Aout1955 #cart_inverted_pendulum #system #model_predictive_control

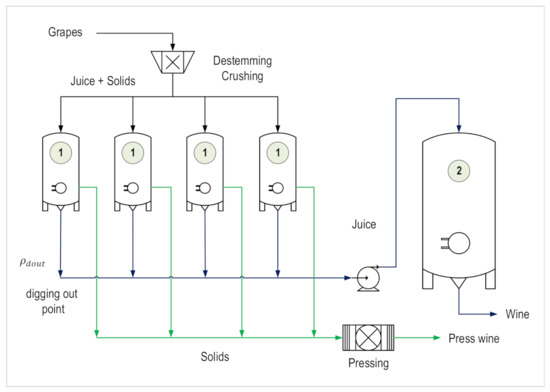
Optimal Control Applied to Oenological Management of Red Wine Fermentative Macerations website: mdpi.com/2311-5637/7/2/… #model_predictive_control; #wine_fermentation;
#processesmdpi Special Issue Interested in the #model_predictive_control? The Special Issue "Model Learning Predictive Control for #Industrial_Processes" mdpi.com/journal/proces… edited by Dr. Leyla Ozkan and Dr. Alejandro Marquez Ruiz is waiting for your contributions!

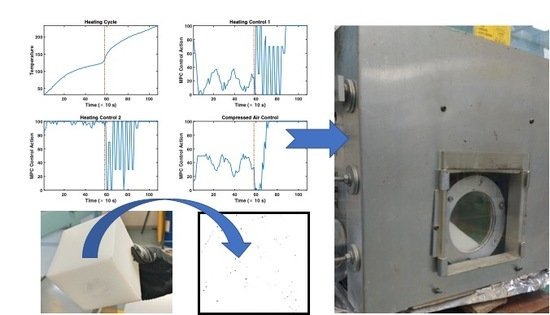
The tenth paper of the special issue is published online: Handling Constraints and Raw Material Variability in Rotomolding through Data-Driven #Model_Predictive_Control". mdpi.com/2227-9717/7/9/…. 👏👏👏
Optimal Control Applied to Oenological Management of Red Wine Fermentative Macerations website: mdpi.com/2311-5637/7/2/… #model_predictive_control; #wine_fermentation;
#processesmdpi Special Issue Interested in the #model_predictive_control? The Special Issue "Model Learning Predictive Control for #Industrial_Processes" mdpi.com/journal/proces… edited by Dr. Leyla Ozkan and Dr. Alejandro Marquez Ruiz is waiting for your contributions!
Collision Avoidance Path Planning and Tracking Control for Autonomous Vehicles Based on Model Predictive Control mdpi.com/1424-8220/24/1… #trajectory_tracking #model_predictive_control
#highlycitedpaper Modeling and Trajectory Tracking Model Predictive Control Novel Method of AUV Based on CFD Data mdpi.com/1424-8220/22/1… @xyl85615557 #autonomous_underwater_vehicle #model_predictive_control #trajectory_tracking #normal_probability_division #GA_ACO_algorithm
Stabilization of the Cart–Inverted-Pendulum System Using State-Feedback Pole-Independent MPC Controllers mdpi.com/1424-8220/22/1… @Univ_20Aout1955 #cart_inverted_pendulum #system #model_predictive_control
The tenth paper of the special issue is published online: Handling Constraints and Raw Material Variability in Rotomolding through Data-Driven #Model_Predictive_Control". mdpi.com/2227-9717/7/9/…. 👏👏👏
Controller Design for Air Conditioner of a #Vehicle with Three Control Inputs Using #Model_Predictive_Control by Trevor Parent, Jeffrey J. Defoe and Afshin Rahimi 👉mdpi.com/2673-3951/5/1/8 #simulation
Something went wrong.
Something went wrong.
United States Trends
- 1. Cowboys 68.4K posts
- 2. Nick Smith 13.3K posts
- 3. Cardinals 30.5K posts
- 4. Kawhi 4,210 posts
- 5. #WWERaw 61K posts
- 6. #LakeShow 3,426 posts
- 7. Jerry 45.5K posts
- 8. Kyler 8,352 posts
- 9. Blazers 7,793 posts
- 10. Logan Paul 10K posts
- 11. No Luka 3,521 posts
- 12. Jonathan Bailey 20.2K posts
- 13. Jacoby Brissett 5,533 posts
- 14. Pickens 6,670 posts
- 15. Cuomo 173K posts
- 16. Valka 4,707 posts
- 17. Koa Peat 6,244 posts
- 18. Javonte 4,325 posts
- 19. AJ Dybantsa 1,718 posts
- 20. Bronny 15.1K posts