#rlalgorithms hasil pencarian

Francisco's focus? Making industrial production processes smarter, faster, & more efficient using advanced #RLalgorithms. He joins our #Optimizationteam to turn cutting-edge AI research into real-world impact. 🏭🤖 #DataScience #Optimization

𝗕𝗲𝘀𝘁 𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀 𝗳𝗼𝗿 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 tinyurl.com/5ajakxt6 #ReinforcementLearning #RLAlgorithms #ScalableRL #RLPractitioners #RLDevelopment #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine

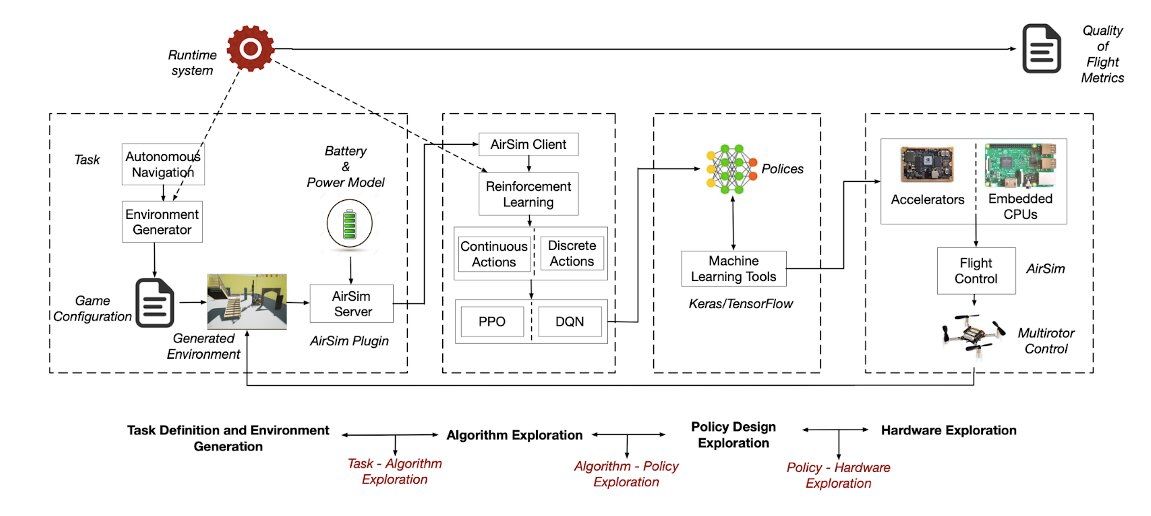
Researchers at @Harvard & the @Google Research team have created #AirLearning, “an open-source simulator & gym environment where researchers can train #RLAlgorithms for #UAVNavigation.” This tech can potentially be used for autonomous vehicles too! buff.ly/3APJ6tQ

𝗕𝗲𝘀𝘁 𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀 𝗳𝗼𝗿 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 tinyurl.com/5ajakxt6 #ReinforcementLearning #RLAlgorithms #ScalableRL #RLPractitioners #RLDevelopment #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine
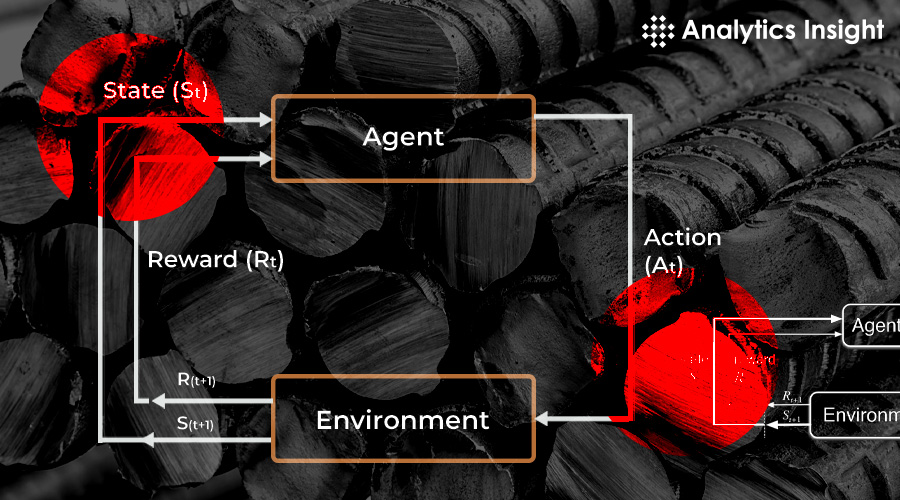

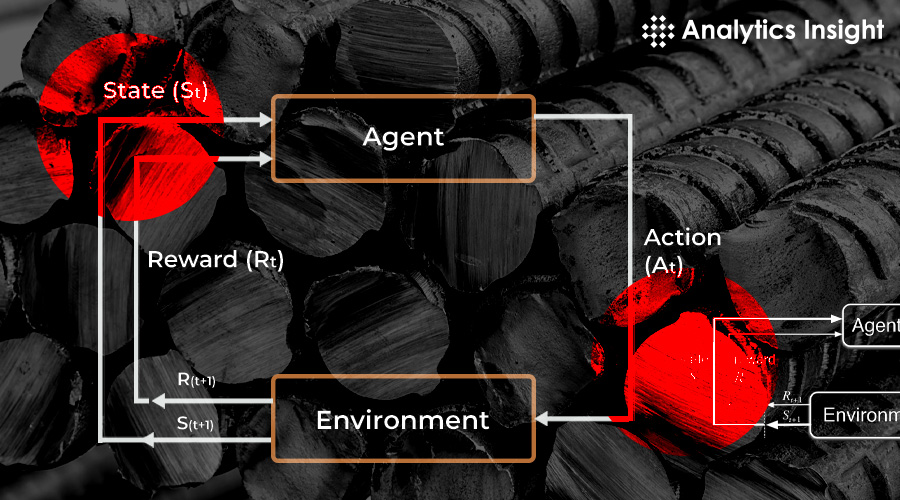
It iteratively updates its Q-value estimates using the Bellman equation, effectively "bootstrapping" its learning from future estimated rewards. This allows the agent to discover the best actions to take in any given state. #QLearning #RLAlgorithms #MachineLearning

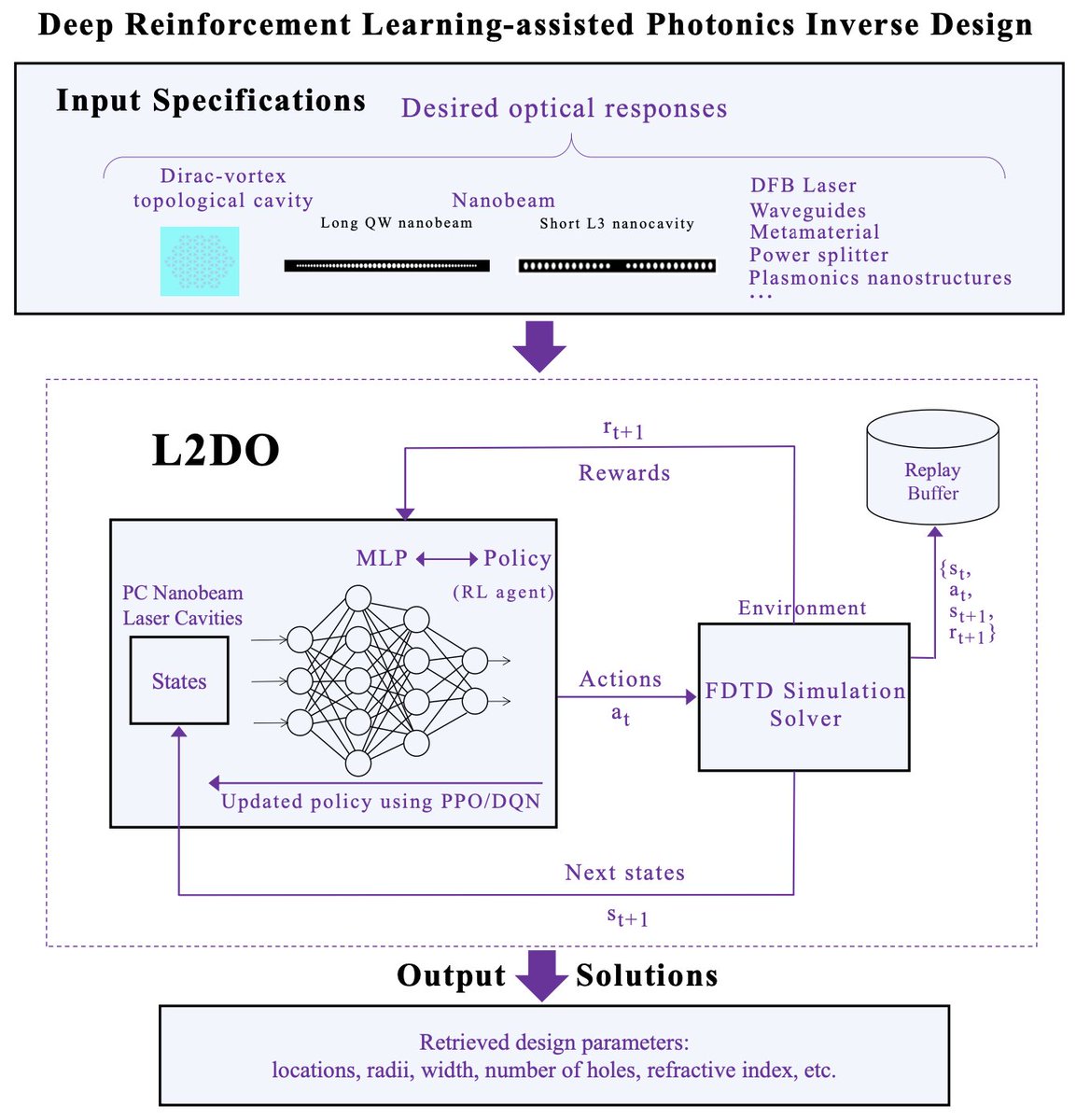
This work confirms the potential of deep #RLalgorithms to surpass and supersede human-based designs and marks a solid step towards a fully automated #AI framework for #photonics inverse design: degruyter.com/document/doi/1… Code and dataset available at: github.com/Arcadianlee/Ph…

@araffin2 et al. propose Stable-Baselines3, an open-source framework implementing 7 commonly used model-free deep #RLalgorithms. They take great care to adhere to software engineering best practices to achieve high-quality implementations that match prior results. #DeepLearning

Stable-Baselines3 (SB3) paper, accepted by the Journal of Machine Learning Research (JMLR), is now available online =D! Paper: jmlr.org/papers/volume2… SB3: github.com/DLR-RM/stable-… SB3-Contrib: github.com/Stable-Baselin…

In this paper, Nicklas Hansen et. al investigate the causes of instability when using data augmentation in common off-policy #RLalgorithms. They identify 2 problems, both rooted in high-variance Q-targets, and propose a technique for stabilizing these algorithms. #MachineLearning

Stabilizing Deep Q-Learning with ConvNets and Vision Transformers under Data Augmentation pdf: arxiv.org/pdf/2107.00644… abs: arxiv.org/abs/2107.00644 project page: nicklashansen.github.io/SVEA/
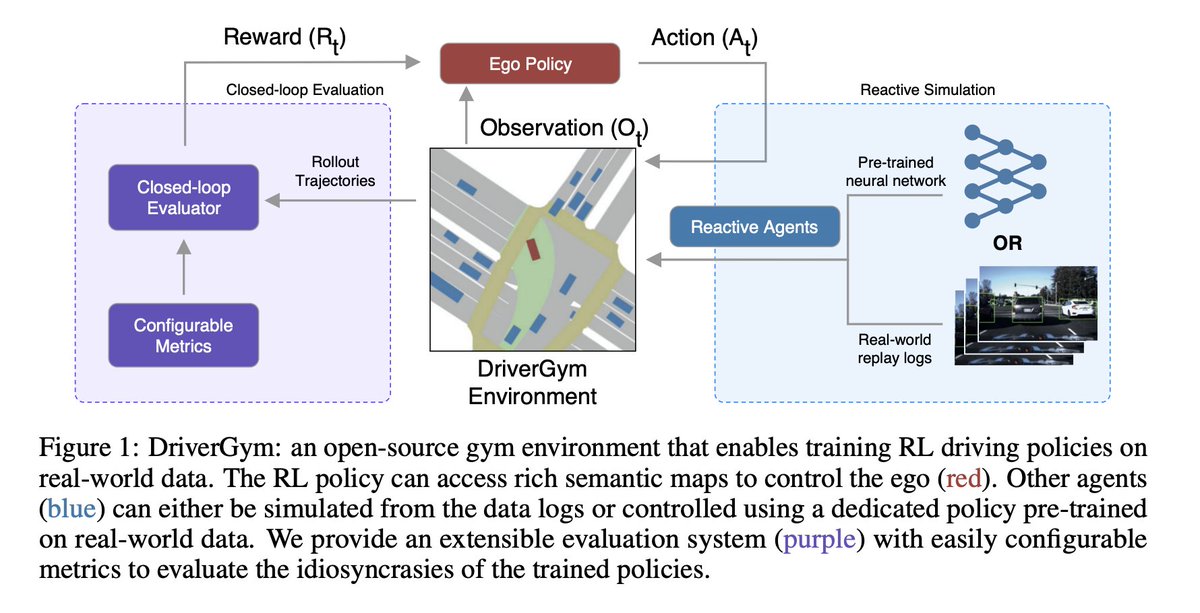
Parth Kothari et al. propose #DriverGym, an open-source #OpenAI Gym-compatible environment specifically tailored for developing #RLalgorithms for autonomous driving. DriverGym provides access to more than 1000 hours of expert logged data and also supports reactive agent behavior.
DriverGym: Democratising Reinforcement Learning for Autonomous Driving abs: arxiv.org/abs/2111.06889 provides access to more than 1000 hours of expert logged data and also supports reactive and data-driven agent behavior
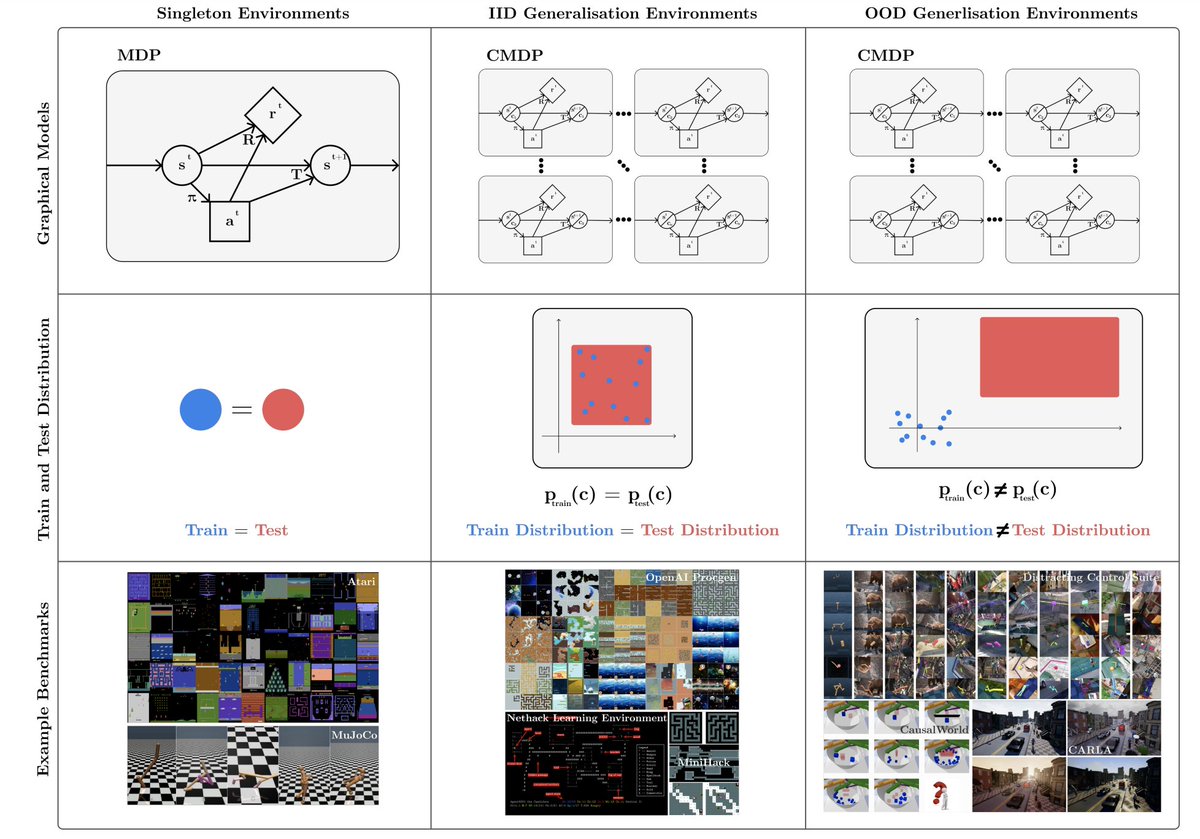
The study of generalization in deep #ReinforcementLearning by @_robertkirk @yayitsamyzhang @egrefen @_rockt aims to produce #RLalgorithms whose policies generalize well to novel unseen situations at deployment time, avoiding overfitting to their training environments. #NLP #AI

This looks like a great survey on a great topic! (going to my "to read" stack : )). Clearly lots of work and ❤️ went into it. TRAIN=TEST 😆 Congrats to all the coauthors! @_robertkirk @yayitsamyzhang @egrefen @_rockt arxiv.org/abs/2111.09794
Francisco's focus? Making industrial production processes smarter, faster, & more efficient using advanced #RLalgorithms. He joins our #Optimizationteam to turn cutting-edge AI research into real-world impact. 🏭🤖 #DataScience #Optimization
𝗕𝗲𝘀𝘁 𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀 𝗳𝗼𝗿 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 tinyurl.com/5ajakxt6 #ReinforcementLearning #RLAlgorithms #ScalableRL #RLPractitioners #RLDevelopment #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine
𝗕𝗲𝘀𝘁 𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀 𝗳𝗼𝗿 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 tinyurl.com/5ajakxt6 #ReinforcementLearning #RLAlgorithms #ScalableRL #RLPractitioners #RLDevelopment #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine
This work confirms the potential of deep #RLalgorithms to surpass and supersede human-based designs and marks a solid step towards a fully automated #AI framework for #photonics inverse design: degruyter.com/document/doi/1… Code and dataset available at: github.com/Arcadianlee/Ph…
@araffin2 et al. propose Stable-Baselines3, an open-source framework implementing 7 commonly used model-free deep #RLalgorithms. They take great care to adhere to software engineering best practices to achieve high-quality implementations that match prior results. #DeepLearning
Stable-Baselines3 (SB3) paper, accepted by the Journal of Machine Learning Research (JMLR), is now available online =D! Paper: jmlr.org/papers/volume2… SB3: github.com/DLR-RM/stable-… SB3-Contrib: github.com/Stable-Baselin…
The study of generalization in deep #ReinforcementLearning by @_robertkirk @yayitsamyzhang @egrefen @_rockt aims to produce #RLalgorithms whose policies generalize well to novel unseen situations at deployment time, avoiding overfitting to their training environments. #NLP #AI
This looks like a great survey on a great topic! (going to my "to read" stack : )). Clearly lots of work and ❤️ went into it. TRAIN=TEST 😆 Congrats to all the coauthors! @_robertkirk @yayitsamyzhang @egrefen @_rockt arxiv.org/abs/2111.09794
Parth Kothari et al. propose #DriverGym, an open-source #OpenAI Gym-compatible environment specifically tailored for developing #RLalgorithms for autonomous driving. DriverGym provides access to more than 1000 hours of expert logged data and also supports reactive agent behavior.
DriverGym: Democratising Reinforcement Learning for Autonomous Driving abs: arxiv.org/abs/2111.06889 provides access to more than 1000 hours of expert logged data and also supports reactive and data-driven agent behavior
In this paper, Nicklas Hansen et. al investigate the causes of instability when using data augmentation in common off-policy #RLalgorithms. They identify 2 problems, both rooted in high-variance Q-targets, and propose a technique for stabilizing these algorithms. #MachineLearning
Stabilizing Deep Q-Learning with ConvNets and Vision Transformers under Data Augmentation pdf: arxiv.org/pdf/2107.00644… abs: arxiv.org/abs/2107.00644 project page: nicklashansen.github.io/SVEA/
𝗕𝗲𝘀𝘁 𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀 𝗳𝗼𝗿 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 tinyurl.com/5ajakxt6 #ReinforcementLearning #RLAlgorithms #ScalableRL #RLPractitioners #RLDevelopment #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine
Researchers at @Harvard & the @Google Research team have created #AirLearning, “an open-source simulator & gym environment where researchers can train #RLAlgorithms for #UAVNavigation.” This tech can potentially be used for autonomous vehicles too! buff.ly/3APJ6tQ
This work confirms the potential of deep #RLalgorithms to surpass and supersede human-based designs and marks a solid step towards a fully automated #AI framework for #photonics inverse design: degruyter.com/document/doi/1… Code and dataset available at: github.com/Arcadianlee/Ph…
𝗕𝗲𝘀𝘁 𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀 𝗳𝗼𝗿 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 tinyurl.com/5ajakxt6 #ReinforcementLearning #RLAlgorithms #ScalableRL #RLPractitioners #RLDevelopment #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine
Something went wrong.
Something went wrong.
United States Trends
- 1. Good Saturday 23.2K posts
- 2. Gittens 3,733 posts
- 3. Delap 7,006 posts
- 4. Burnley 28.1K posts
- 5. #askdave N/A
- 6. #SaturdayVibes 3,414 posts
- 7. Tosin 7,394 posts
- 8. Neto 14.1K posts
- 9. #BURCHE 10.5K posts
- 10. Chalobah 3,503 posts
- 11. #saturdaymorning 1,577 posts
- 12. #LingOrm3rdMeetMacauD1 544K posts
- 13. caturday 4,123 posts
- 14. LINGORM MACAU MEET D1 538K posts
- 15. Maresca 16.1K posts
- 16. The View 97.5K posts
- 17. Somali 81.4K posts
- 18. John F. Kennedy 2,463 posts
- 19. Travis Head 28K posts
- 20. Marjorie Taylor Greene 85.6K posts