#regression_analysis_in_machine_learning 搜尋結果

Wish to build scaling laws for RL but not sure how to scale? Or what scales? Or would RL even scale predictably? We introduce: The Art of Scaling Reinforcement Learning Compute for LLMs


Important Statistical Techniques. @abacusai #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #CloudComputing #Serverless #Linux #Statistics #Programming #Coding #100DaysofCode…


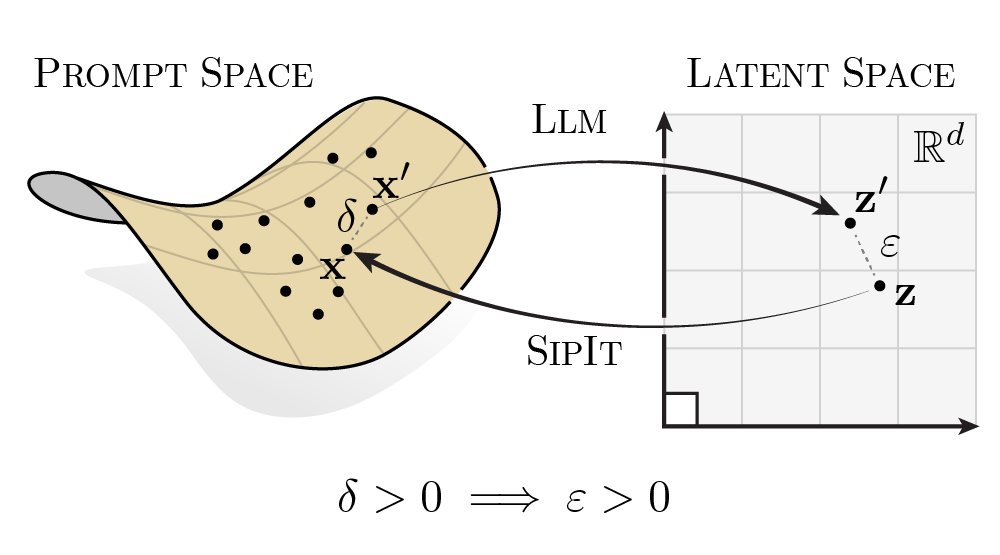
LLMs are injective and invertible. In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space. (1/6)

90% of ML portfolios look identical. If yours only has Titanic survival predictions, you’re invisible. These 5 projects? They’ll make hiring managers stop scrolling and start DM’ing you Most job seekers showcase the same old projects: Titanic survival, MNIST digit recognition,…




Since compute grows faster than the web, we think the future of pre-training lies in the algorithms that will best leverage ♾ compute We find simple recipes that improve the asymptote of compute scaling laws to be 5x data efficient, offering better perf w/ sufficient compute


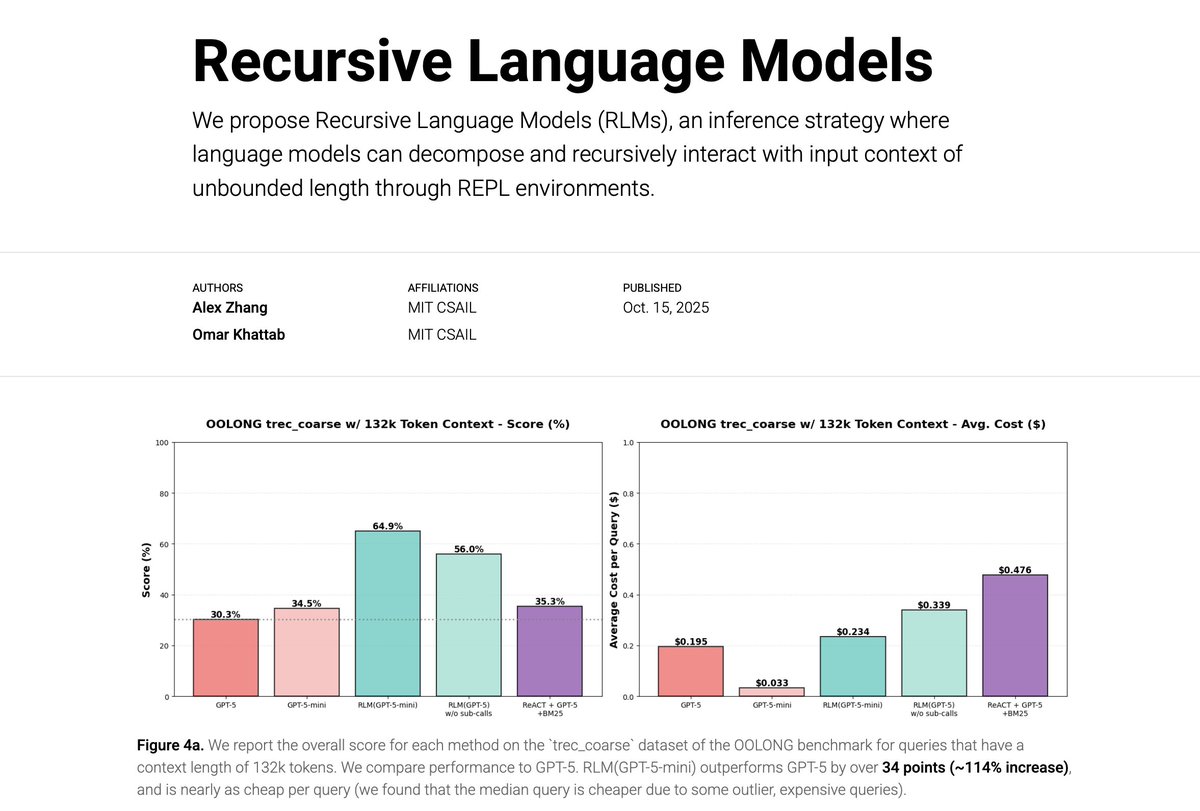
What if scaling the context windows of frontier LLMs is much easier than it sounds? We’re excited to share our work on Recursive Language Models (RLMs). A new inference strategy where LLMs can decompose and recursively interact with input prompts of seemingly unbounded length,…

New blog post! This one is a purely theoretical one attempting identifying the central reason why LLMs suffer from mode collapse in RL and fail to generate novel or truly diverse outputs. It's actually a way more complicated problem than you think! Naively encouraging…

Network regression analyzes relationships in networked data, like social media connections or biological pathways. It goes beyond traditional models by accounting for interdependencies between nodes. In statistics and ML, it’s used for tasks like link prediction and community…
Statistics by simulation, or Monte Carlo methods, uses computational power to solve problems that are too hard for traditional math. Instead of solving complex equations, we program a computer to mimic a random process (like rolling dice or modeling stock prices) millions of…


159 page PDF download. The best examples of how machine learning is used in finance and algorithmic trading. Grab the paper here:

Analysis of Variance (ANOVA) is a statistical method used to test differences between two or more means. It helps determine if the means of different groups are significantly different from each other. ANOVA is particularly useful when comparing three or more groups, as it avoids…


Everyone says “LLMs are black boxes.” This paper "How Do LLMs Use Their Depth?” just opened one and showed how intelligence forms layer by layer. They follow a “Guess → Refine” strategy: • Early layers make statistical guesses using frequent tokens (“the”, “of”, “and”) •…

PCA (Principal Component Analysis) is a powerful machine learning method for dimensionality reduction. It finds the most important patterns (principal components) in high-dimensional data, allowing it to be compressed with minimal information loss. In ML, this speeds up model…


The first fantastic paper on scaling RL with LLMs just dropped. I strongly recommend taking a look and will be sharing more thoughts on the blog soon. The Art of Scaling Reinforcement Learning Compute for LLMs Khatri & Madaan et al.


this paper costed 4.2 mil USD to write holy... most labs haven't reached the point of releasing models that costed that much let alone a paper that covers all the details


Key Takeaways from “Regression Modeling Strategies” by Frank Harrell (@f2harrell) A must-read for anyone working with predictive modeling. Here’s what you need to know: Plan your model with clear goals—whether prediction, effect estimation, or hypothesis testing. Avoid…


***Ordinary Regression versus Logistic Regression *** Mathematical Foundation • Ordinary Regression uses the least squares method to minimize the sum of squared errors between predicted and actual values. • Logistic Regression uses maximum likelihood estimation (MLE) to find…




Supervised vs Unsupervised Learning bit.ly/2nlPokL_differ… Supervised and Unsupervised learning are the two techniques of machine learning. #Supervised_Learning #Unsupervised_Learning #Regression_Analysis_in_Machine_learning

Supervised vs Unsupervised Learning bit.ly/2nlPokL_differ… Supervised and Unsupervised learning are the two techniques of machine learning. #Supervised_Learning #Unsupervised_Learning #Regression_Analysis_in_Machine_learning
Something went wrong.
Something went wrong.
United States Trends
- 1. Ohtani 64K posts
- 2. #WorldSeries 67.7K posts
- 3. Chiefs 76.1K posts
- 4. #WWERaw 42.8K posts
- 5. Mahomes 23.6K posts
- 6. Mariota 7,533 posts
- 7. #Dodgers 12.2K posts
- 8. Treinen 2,830 posts
- 9. Terry 23.5K posts
- 10. Kelce 15.6K posts
- 11. Rashee Rice 3,723 posts
- 12. #RaiseHail 7,093 posts
- 13. Maxey 9,145 posts
- 14. Roki 5,312 posts
- 15. Mookie 7,903 posts
- 16. Glasnow 5,389 posts
- 17. Vladdy 5,103 posts
- 18. Deebo 5,573 posts
- 19. Dave Roberts 3,090 posts
- 20. Commanders 33.8K posts