#sparsetransformers search results

Generative Modeling with Sparse Transformers openai.com/blog/sparse-tr… #GenerativeModeling #SparseTransformers

重みスパース学習でLLMの回路は解釈可能になるのか?(2511.13653)【論文解説シリーズ】Weight-sparse transformers have interpretable circuits. Leo Gao, et al. youtu.be/48BsKIZhh4M?si… via @YouTube

youtube.com
YouTube
重みスパース学習でLLMの回路は解釈可能になるのか?(2511.13653)【論文解説シリーズ】

Weight-sparse transformers have interpretable circuits [Gao+, 2025] Training a Transformer with L0 norm fixed yields disentangled circuits. The role of each weight can be identified and visualized for simple tasks like closing quotation marks, arxiv.org/abs/2511.13653 #NowReading
![shion_honda's tweet image. Weight-sparse transformers have interpretable circuits [Gao+, 2025]
Training a Transformer with L0 norm fixed yields disentangled circuits. The role of each weight can be identified and visualized for simple tasks like closing quotation marks,
arxiv.org/abs/2511.13653
#NowReading](https://pbs.twimg.com/media/G6cIsJBXUAAMu__.png)
Weight-sparse transformers have interpretable circuits [Gao+, 2025] TransformerのL0ノルムを固定しほとんどの重みをゼロにした状態で訓練すると、disentangledな回路が得られる。引用符の開閉のような単純なタスクで各重みの役割を同定・可視化。 arxiv.org/abs/2511.13653 #NowReading
![shion_honda's tweet image. Weight-sparse transformers have interpretable circuits [Gao+, 2025]
TransformerのL0ノルムを固定しほとんどの重みをゼロにした状態で訓練すると、disentangledな回路が得られる。引用符の開閉のような単純なタスクで各重みの役割を同定・可視化。
arxiv.org/abs/2511.13653
#NowReading](https://pbs.twimg.com/media/G6cHCGCWIAAYQKq.png)
![shion_honda's tweet image. Weight-sparse transformers have interpretable circuits [Gao+, 2025]
TransformerのL0ノルムを固定しほとんどの重みをゼロにした状態で訓練すると、disentangledな回路が得られる。引用符の開閉のような単純なタスクで各重みの役割を同定・可視化。
arxiv.org/abs/2511.13653
#NowReading](https://pbs.twimg.com/media/G6cHskxWIAAskOM.png)

A weight-sparse transformer could crack AI's black box-if it tackles hallucinations without sacrificing utility. Deployment will prove it. #Interpretability



📷📷📷New paper! (with @OpenAI) 📷📷📷 We trained weight-sparse models (transformers with almost all of their weights set to zero) on code: we found that their circuits become naturally interpretable! Our models seem to learn extremely simple, disentangled, internal mechanisms!

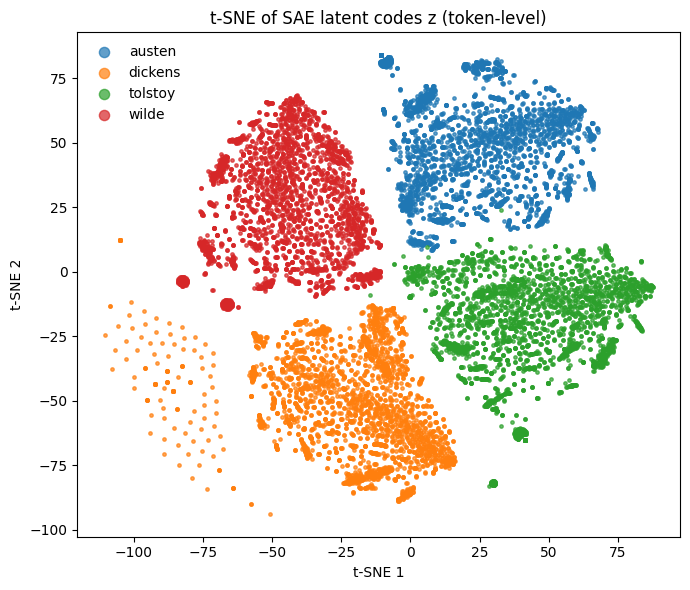
Sparse autoencoder after being fed vectors from the final hidden state of transformers trained on each author with reconstruction + contrastive loss




![chrisoffner3d's tweet image. Leaner Transformers: More Heads, Less Depth
[arxiv:2505.20802]](https://pbs.twimg.com/media/GsWhAtBWsAALACM.png)



drawing a bunch of stickers that'll compress to bits when it's printed d/op shenanigans (づ๑•ᴗ•๑)づ┬─┬ノ( º _ ºノ) #transformersone #megop




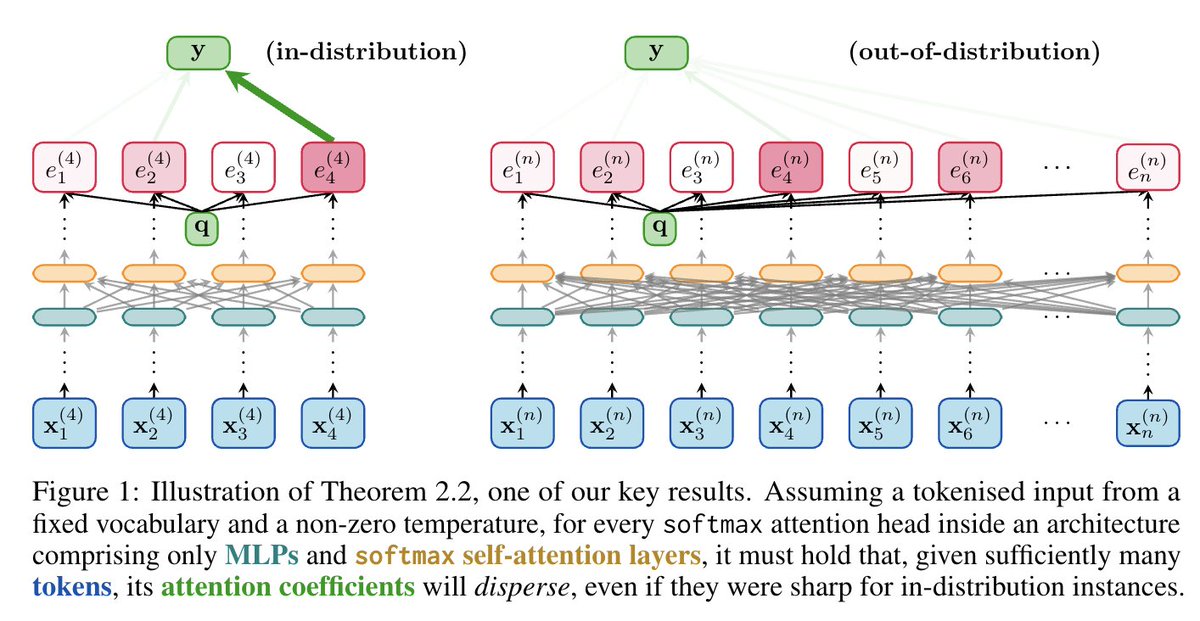
"Energy continuously flows from being concentrated, to becoming dispersed, spread out, wasted and useless." ⚡➡️🌬️ Sharing our work on the inability of softmax in Transformers to _robustly_ learn sharp functions out-of-distribution. Together w/ @cperivol_ @fedzbar & Razvan!


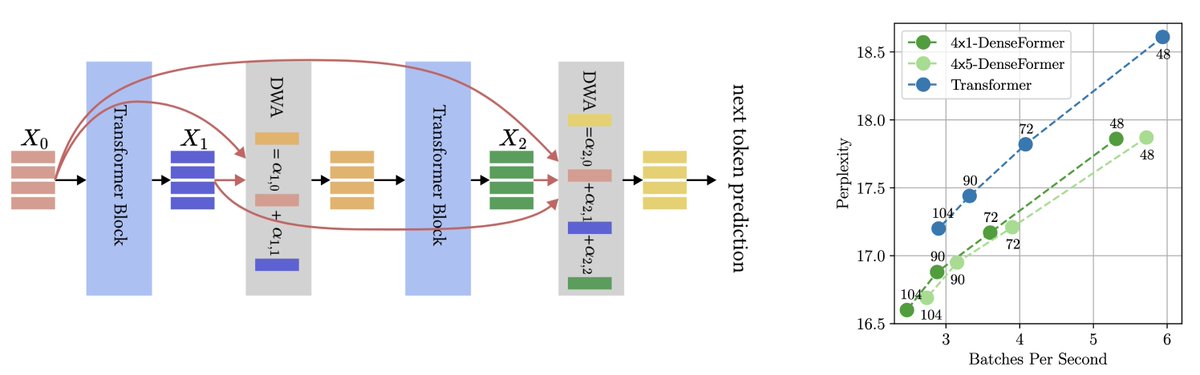
A tweak in the architecture of #Transformers can significantly boost accuracy! With direct access to all previous blocks’ outputs, a 48-block #DenseFormer outperforms a 72-block Transformer, with faster inference! A work with @akmohtashami_a,@francoisfleuret, Martin Jaggi. 1/🧵

Our new Sparse Universal Transformer is both parameter-efficient and computation-efficient compared to the Transformer, and it's better at compositional generalization! paper: arxiv.org/abs/2310.07096


From Sparse to Soft Mixtures of Experts Proposes Soft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining the benefits of MoEs. arxiv.org/abs/2308.00951


Reading the sparse transformer arxiv.org/abs/1904.10509… Great paper- seems like it doesn’t get as much attention as it should. The common refrain is “No one’s has figured out how to scale attention sub-quadratically” but the sparse transformer’s right here


Takara releases the 'Smallest Transforming Transformers' line, consisting of downsized G1 toys. (2003)





Transformers are huge. They are not efficient in deployment. But no worries. You can sparsify them with a few lines of code using SparseML: github.com/neuralmagic/sp… Result? More compression and better inference performance at the same accuracy. P.S. Same goes for CV models!


New pencil delivered last night! #transformersreanimated The point of developing combiners is not their size or strength, it is more about their incredible speed and flexibility, in TFRA universe, a middle size combiner like Menasor can move as swift as a single Stunticon.

Generative Modeling with Sparse Transformers openai.com/blog/sparse-tr… #GenerativeModeling #SparseTransformers
Something went wrong.
Something went wrong.
United States Trends
- 1. #GMMTV2026 155K posts
- 2. Moe Odum N/A
- 3. #WWERaw 75.2K posts
- 4. Brock 40.5K posts
- 5. Panthers 37.6K posts
- 6. Bryce 21.1K posts
- 7. Finch 14.1K posts
- 8. Keegan Murray 1,485 posts
- 9. Timberwolves 3,834 posts
- 10. Gonzaga 4,052 posts
- 11. 49ers 41.9K posts
- 12. Canales 13.3K posts
- 13. TOP CALL 9,038 posts
- 14. AI Alert 7,716 posts
- 15. Alan Dershowitz 2,542 posts
- 16. #FTTB 5,905 posts
- 17. Penta 10.6K posts
- 18. Market Focus 4,635 posts
- 19. Check Analyze 2,335 posts
- 20. Niners 5,883 posts