#supervisedalgorithms search results

Thinking of applying self-supervised learning (SSL) on your uncurated, imbalanced datasets? Good news: we found SSL is more robust to long tails than supervised representations. We also present theoretical and empirical analyses and an improved algorithm. arxiv.org/abs/2110.05025


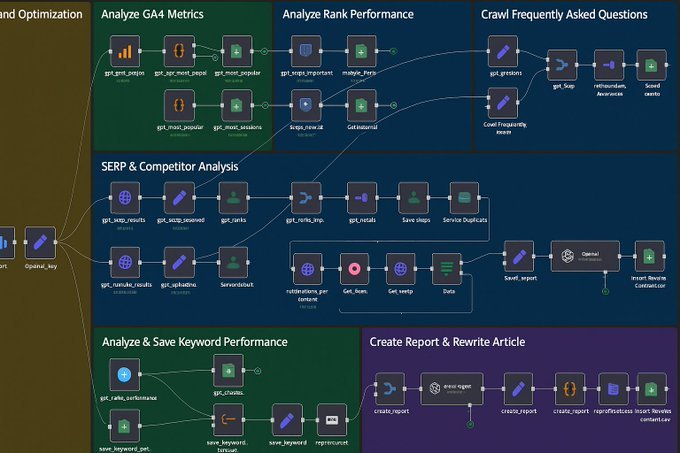
This AI Agent does full-stack SEO 🤯 Built in n8n: 📊 Analyzes GA4 + Rank + SERP 🧠 Crawls + Cleans FAQ 🔍 Tracks Competitor Keywords ✍️ Auto-rewrites articles 📈 Saves reports & performance 🔁 Like + RT ✅ Reply “AI” 🤝 Follow me & I’ll DM you the full workflow FREE

Awesome Self-Supervised Learning Self-supervision is the tech behind most large-scale AI systems across different modalities(vision, language, robotics, speech,...). Here is a great curated list of self-supervised learning resources: CV, NLP, ASR, etc... github.com/jason718/aweso…


Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

Every breakthrough starts with the people behind it. The @SentientAGI Researcher Spotlight series highlights the incredible minds shaping the future of multi-agent systems, cryptoeconomic security, and open AI coordination. ➥ Salah Alzu’bi ( @sala88232 ) – driving multi-agent…





To predict and prevent equipment failures, integrating IoT sensors, analyzing real-time data, and implementing predictive maintenance strategies are essential. Here’s how to effectively use IoT for predictive maintenance. #IoT #PredictiveMaintenance #BigData


distillation is the sincerest form of flattery

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

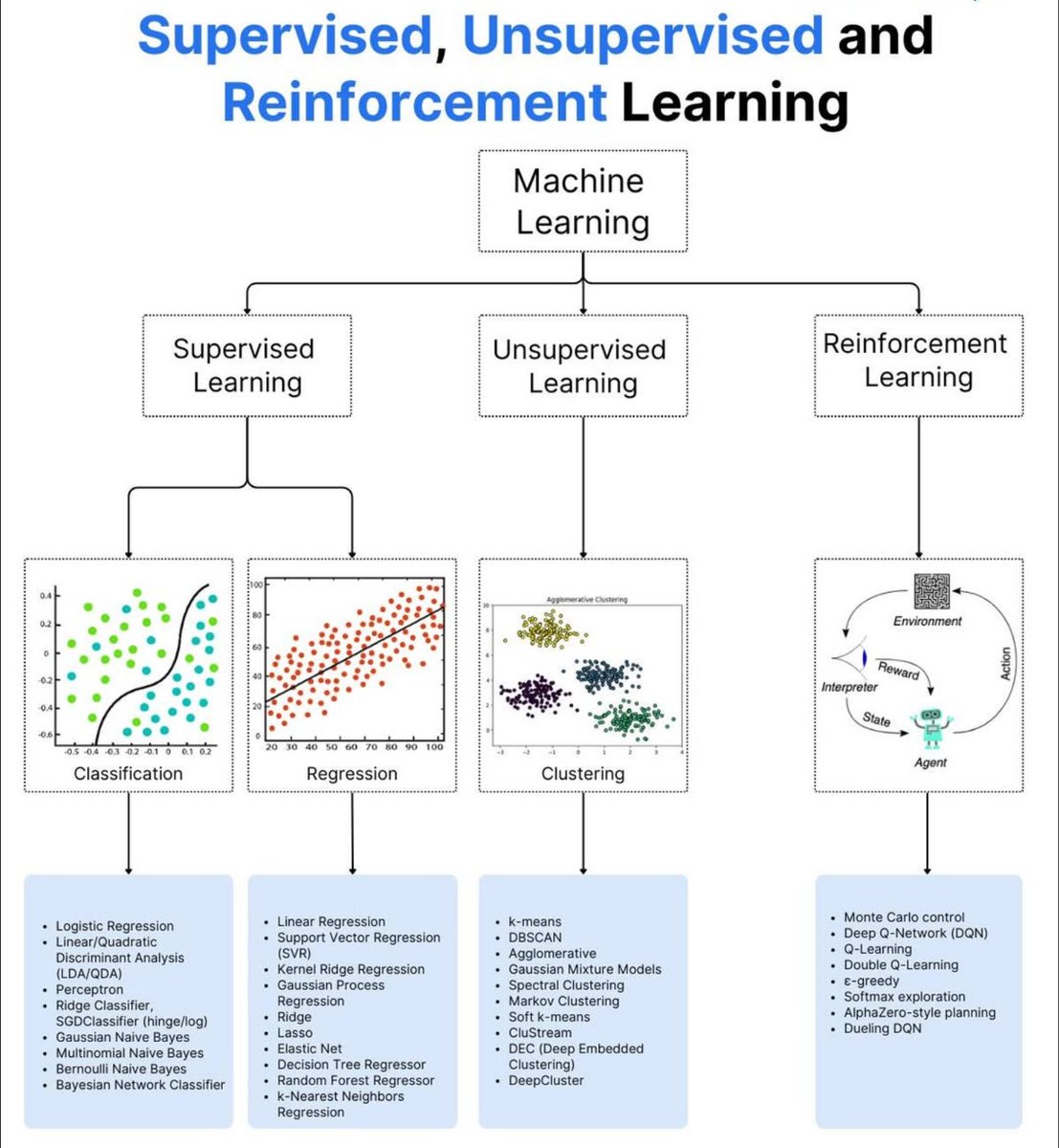
Supervised. Unsupervised. Reinforcement. Three ways machines learn. One way you level up.

Your AI model passed all the tests. Got great metrics. Everyone's excited. Then it hits production and starts drifting. Or hallucinating. What worked yesterday might be quietly breaking today. Explore the platform → hubs.li/Q03QDMfz0


✨ Anecdote from my autonomous multi-agent system project (powered by GPT-5 Codex)! In this setup, I’ve built a system where a 𝐒𝐮𝐩𝐞𝐫𝐯𝐢𝐬𝐨𝐫 𝐎𝐫𝐜𝐡𝐞𝐬𝐭𝐫𝐚𝐭𝐨𝐫 receives a high-level user request — for example, "𝘪𝘮𝘱𝘭𝘦𝘮𝘦𝘯𝘵 𝘢 𝘯𝘦𝘸 𝘧𝘦𝘢𝘵𝘶𝘳𝘦" — and…

AI needs oversight, but constant human checks aren’t the answer. 👩💻 We need smarter ways for people and AI to work together—keeping systems safe, effective, and easy for humans to guide when it really counts. 💡 #SASAnalyticsExplorers#SASAdvocacyProgr infl.tv/pyaN


SAPO from @gensynai . Collective training of language models through reinforcement learning 𝟏/𝟐 .Gensyn is surprising. Previously, we discussed distributed learning, but now we are discussing collective thinking models. 𝗦𝗔𝗣𝗢 ( 𝗦𝘄𝗮𝗿𝗺 𝗦𝗮𝗺𝗽𝗹𝗶𝗻𝗴 𝗣𝗼𝗹𝗶𝗰𝘆…


Say hello to DINOv3 🦖🦖🦖 A major release that raises the bar of self-supervised vision foundation models. With stunning high-resolution dense features, it’s a game-changer for vision tasks! We scaled model size and training data, but here's what makes it special 👇




Most companies say they have AI governance. Few can explain how their systems make choices or when those choices start to change. Observability turns “we think it’s working” into “we know it is.” 🔗 hubs.li/Q03Qt4tk0 #AIGovernance #Observability


HUGE AI breakthrough from META. This can change everything (in AI industry) 30x Faster LLMs, 16x Bigger Contexts, Zero Accuracy Loss 👀 Meta Superintelligence Labs is clearly already cooking. "The core problem with long context is simple: making a document 2x longer can make…


Meta Superintelligence Labs just made LLMs handle 16x more context and unlocked up to a 31x speedup. 🤯 Their new REFRAG framework rethinks RAG from the ground up to achieve this, all with zero drop in accuracy. Here's how it works: The core problem with long context is…


Combining the benefits of RL and SFT with on-policy distillation, a promising approach for training small models for domain performance and continual learning.
Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

Content creators, meet your new growth engine. No more guessing what works. No more chasing algorithms. This AI Curator researches trends, writes optimized posts, and even predicts performance before you hit publish. 👇
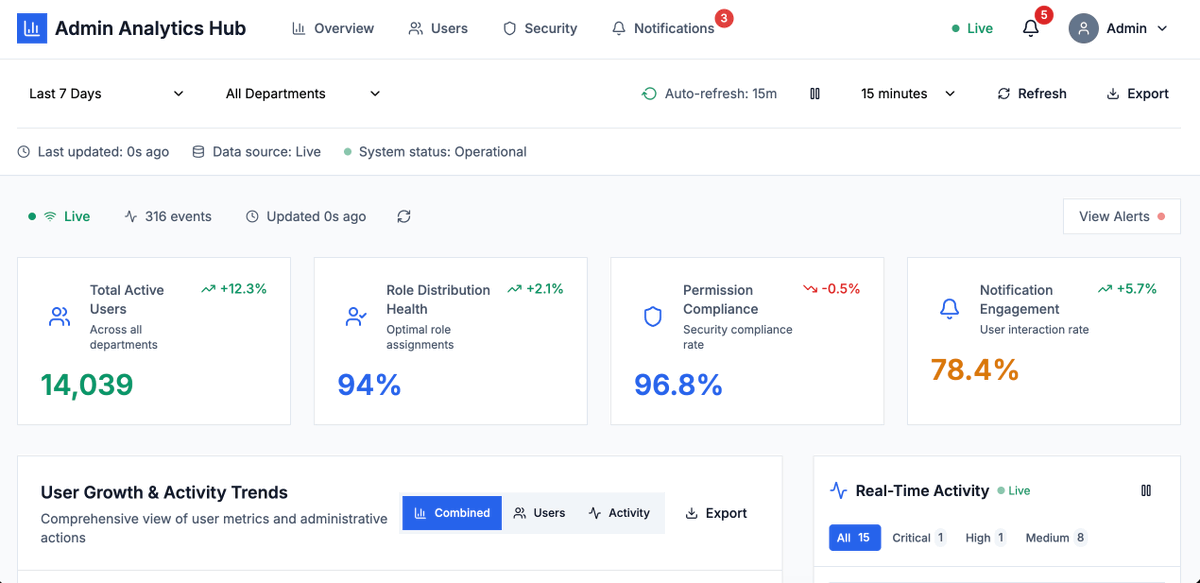

There are many helpful AI tools out there these days - and as a dev, you'll want to learn how to use them. In this article, @sprucekhalifa shares how he uses these tools effectively & responsibly in his own projects. He discusses pair programming with the AI, reviewing and…


What is a Support Vector Machine? A support vector machine (SVM) is a supervised machine learning algorithm that finds the hyperplane that best separates data points of one class from those of another class


Label noise is a frequent problem when training supervised algorithms. Learn how to reduce label noise using LASSO The Traitors (LTT). hubs.ly/H0r1_Qc0 #DataScience #SupervisedAlgorithms #ML #Tutorial

#Machinelearning algorithms are often categorized as being supervised or unsupervized. #Supervisedalgorithms can apply what has been learned in the past to new data. #Unsupervisedalgorithms can draw inferences from datasets. More on the @infoq ML page bit.ly/2A4fjSw

#Machinelearning algorithms are often categorized as being supervised or unsupervized. #Supervisedalgorithms can apply what has been learned in the past to new data. #Unsupervisedalgorithms can draw inferences from datasets. More on the @infoq ML page bit.ly/2A4fjSw
Something went wrong.
Something went wrong.
United States Trends
- 1. Don Lemon 5,253 posts
- 2. SNAP 1.05M posts
- 3. Jamaica 283K posts
- 4. #LumioseOOTD N/A
- 5. $NVDA 88.8K posts
- 6. Luke Kwon N/A
- 7. Riley Gaines 110K posts
- 8. Nelson 31.8K posts
- 9. New World 95.7K posts
- 10. Alcaraz 8,624 posts
- 11. #MarcelReed N/A
- 12. Outbreak 4,552 posts
- 13. Fuentes 85.7K posts
- 14. Wikipedia 131K posts
- 15. Norrie 4,855 posts
- 16. Tucker 106K posts
- 17. Megyn Kelly 5,072 posts
- 18. FOMC 19K posts
- 19. #NationalFirstRespondersDay 1,675 posts
- 20. Western Union 7,102 posts