#visionlanguage resultados da pesquisa



Back from the break with Phillip Isola @phillip_isola on “On the Perceptual Distance Between Images and Text.” A fascinating and interactive look at how models (and humans!) measure similarity 👏🏻 #HiCV2025 #ICCV2025 #VisionLanguage




Day 168 Meet MiniCPM-V 2.6, the latest and most capable model in the MiniCPM-V series! This powerhouse surpasses GPT-4V in single image, multi-image, and video understanding. #AI #MachineLearning #VisionLanguage #MiniCPMV #TechInnovation #RealTimeVideo #MultimodalLLMs #GPT4V

Encord’s EMM1 tests AI on real-world vision and language tasks. It reveals strengths and gaps in context understanding while pushing models to generalize better. Complexity and resources remain a challenge. #AI #Data #VisionLanguage encord.com/multimodal-dat…
encord.com
E-MM1 Dataset: The World's Largest Multimodal AI Dataset
The E-MM1 dataset is the world's largest multimodal AI dataset, with more than 100 million groups of data in five modalities to foster the development of models that fuse multiple modalities.

In 2023, researchers launched VisIT-Bench, a benchmark with 592 vision-language tasks spanning 70 categories like plot analysis and art knowledge. #AI #VisionLanguage @Stanford


❓Docs read by models—but can they prove it? // RAD² X ensures traceable, agency-first choices in VLM pipelines. glcnd.io/transforming-d… #GLCND #RAD2X #VisionLanguage #ExplainableAI
glcnd.io
Transforming Document Processing: How Vision-Language Models are Changing the Game - GLCND.IO
Vision-language models (VLMs) efficiently process documents, extracting insights from text and visuals, transforming archives into structured data.

🚀 Thrilled to announce our paper "TG-LLaVA: Text Guided LLaVA" accepted by @AAAI! We enhance vision encoders with text guidance, boosting performance without extra data. Huge thanks to the team! #AI #VisionLanguage


🔥 Discover the fascinating world of Multimodal Foundation Models, with the journey "From Specialists to General-Purpose Assistants" 🌐 Dive into the evolution of large models in #ComputerVision & #VisionLanguage! Paper: arxiv.org/abs/2309.10020 Tutorial: vlp-tutorial.github.io/2023/





Multimodal Foundation Models: From Specialists to General-Purpose Assistants paper page: huggingface.co/papers/2309.10… paper presents a comprehensive survey of the taxonomy and evolution of multimodal foundation models that demonstrate vision and vision-language capabilities,…


📢Join us for our #ImageInWords poster presentation on Nov 12th, 11:00-12:30pm at #EMNLP . We'll be diving deep into hyper-detailed image descriptions and the impact on #VisionLanguage models. See you there!👋 #NLProc #ComputerVision @emnlpmeeting @AndreaDBurns @GoogleDeepMind 🧵


When you feel the Holy Spirit trying to drop a vision on you, but you can't connect... go lie down and take a nap. Your mind is in the way. Once your mind shuts down, your spirit and the Holy Spirit will talk and you'll access that vision. #VisionLanguage #PrayingProphet

🚨 New model alert! 🚨 We've added OpenGVLab InternVL3_5-2B! It's a vision-language model. Get it running in LocalAI with: `local-ai run opengvlab_internvl3_5-2b` 😉 #LocalAI #VisionLanguage #NewModel

🔍 Today's top pick from @powerdrill Research Digest: 'Training-Free Unsupervised Prompt for Vision-Language Models'. Check out the link for a summary: app.powerdrill.ai/s/1jB88R #AI #VisionLanguage #Research


With Meta's LLama-3.2-90b Vision Instruct model, you can upload an image and engage in a fascinating conversation about it! 🎨📸 This cutting-edge vision-language model redefines how we interact with images, unlocking new possibilities. #AI #VisionLanguage #Innovation#ALX_AI




MiniGPT-4: Enhancing vision-language understanding using advanced large language models for multi-task learning. #AI #VisionLanguage #LLM #MachineLearning


Power up sustainably with #MiniGPT4. The smarter, smaller sibling of #GPT4 with better #visionlanguage understanding, it is perfect for image captioning and visual question-answering tasks. Discover the benefits at bit.ly/3WXNVxq #USAII #AI #SoftwareDeveloper #gpt4

1/5 🌐"On the Test-Time Zero-Shot Generalization of Vision-Language Models: Do We Really Need Prompt Learning?" This paper explores the necessity of prompt learning for VLMs. #AI #MachineLearning #VisionLanguage


🚀CFP: Vision-and-Language Intelligence Explore the frontier of multimodal AI — from image captioning & VQA to foundation models & real-world applications. 🗣 Submit your work soon! 🔗oaepublish.com/specials/ir.10… #VisionLanguage #MultimodalAI #AI #CFP #DeepLearning

1/5 🖼️📚Introducing a new approach for vision-language pre-training: "Efficient Vision-Language Pre-training by Cluster Masking." This method enhances visual-language contrastive learning with a novel masking technique. #AI #MachineLearning #VisionLanguage


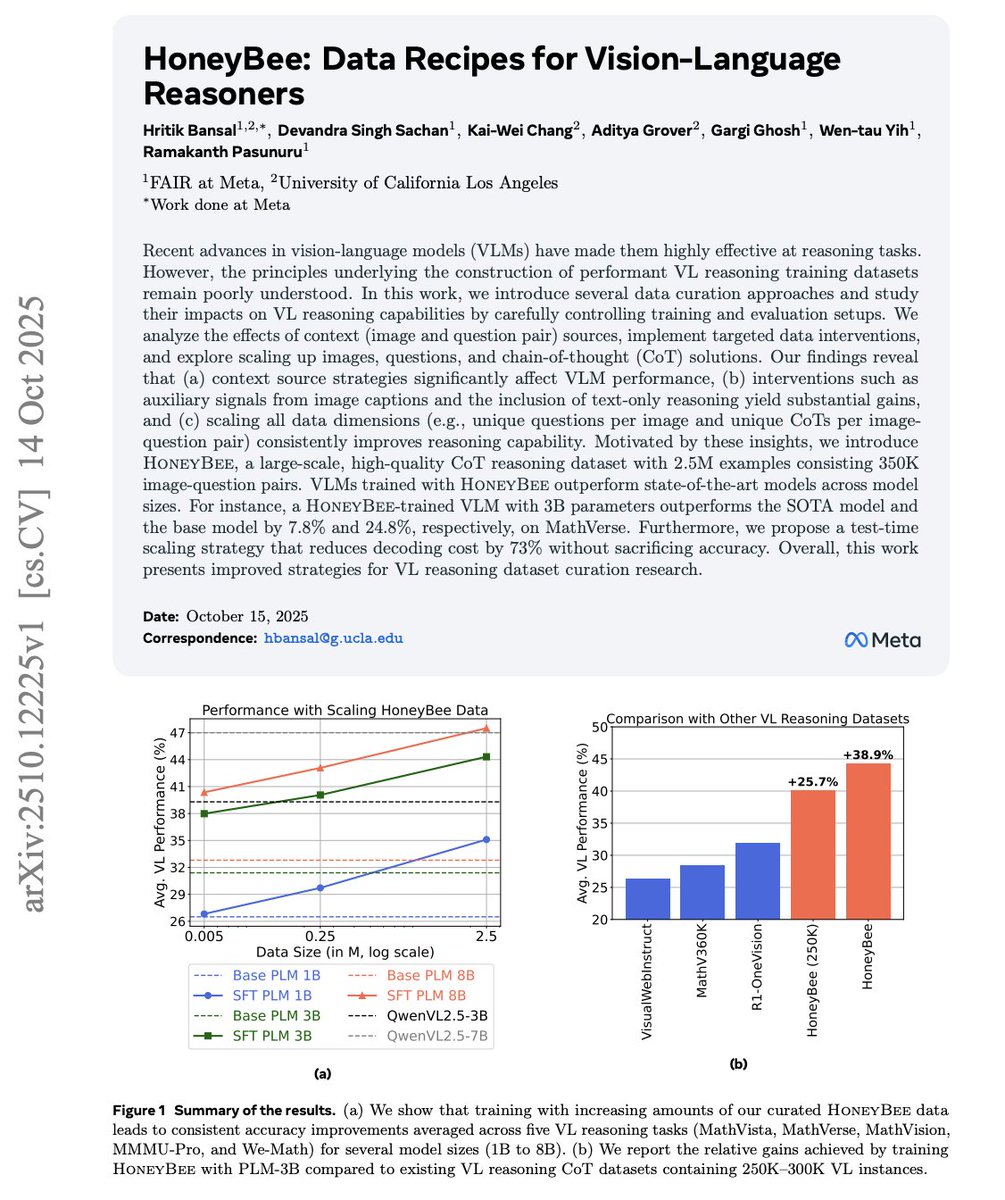
HoneyBee: A 2.5M-sample vision-language reasoning dataset boosts VL model accuracy up to +38.9%, with smarter data curation (context, CoT, scaling) and 73% lower decoding cost. #AI #VisionLanguage

New paper 📢 Most powerful vision-language (VL) reasoning datasets remain proprietary 🔒, hindering efforts to study their principles and develop similarly effective datasets in the open 🔓. Thus, we introduce HoneyBee, a 2.5M-example dataset created through careful data…
Encord’s EMM1 tests AI on real-world vision and language tasks. It reveals strengths and gaps in context understanding while pushing models to generalize better. Complexity and resources remain a challenge. #AI #Data #VisionLanguage encord.com/multimodal-dat…
encord.com
E-MM1 Dataset: The World's Largest Multimodal AI Dataset
The E-MM1 dataset is the world's largest multimodal AI dataset, with more than 100 million groups of data in five modalities to foster the development of models that fuse multiple modalities.
Back from the break with Phillip Isola @phillip_isola on “On the Perceptual Distance Between Images and Text.” A fascinating and interactive look at how models (and humans!) measure similarity 👏🏻 #HiCV2025 #ICCV2025 #VisionLanguage

Join us as we explore how to build trustworthy, robust, and safe vision-language generative models (e.g., Text-to-Image & Image-to-Text models). #ICCV2025 #GenerativeAI #VisionLanguage #AITrustworthiness #ResponsibleAI

🚀 Temporal Understanding has been a missing piece of puzzle for multimodal large language models. 🧵 0/n Proud to announce our work, TimeWarp, a novel synthetic temporal preference data generation pipeline. #VideoLLMs #VisionLanguage #Genai #LLMs #TemporalUnderstanding

The special contribution? Our dataset goes beyond perception: we curated cultural reasoning questions that require knowledge to answer, not just visual cues. Check it out here 👉 seeingculture-benchmark.github.io #EMNLP #visionlanguage #vlm #benchmark #computervision

[1/4] We tested InternVL3.5-aligned GPT-OSS on MMMU and found visual alignment gaps: misreads, shallow grounding, and repetition. It’s an early step, not the solution—good scaffolding, weak seeing. #Multimodal #VisionLanguage
![johnson111788's tweet image. [1/4] We tested InternVL3.5-aligned GPT-OSS on MMMU and found visual alignment gaps: misreads, shallow grounding, and repetition. It’s an early step, not the solution—good scaffolding, weak seeing. #Multimodal #VisionLanguage](https://pbs.twimg.com/media/G2Bsfg3W4AAzEBE.jpg)
❓Docs read by models—but can they prove it? // RAD² X ensures traceable, agency-first choices in VLM pipelines. glcnd.io/transforming-d… #GLCND #RAD2X #VisionLanguage #ExplainableAI
glcnd.io
Transforming Document Processing: How Vision-Language Models are Changing the Game - GLCND.IO
Vision-language models (VLMs) efficiently process documents, extracting insights from text and visuals, transforming archives into structured data.

Thrilled to see ERNIE 4.5 VL earn a top spot on the latest SuperCLUE-VLM benchmark. Time to build something new with vision!👀 #AI #Multimodal #VisionLanguage #LLM #Benchmark #ERNIE


Discover FastVLM, a breakthrough in Vision Language Models that boosts image resolution and speeds up processing, making text-rich image understanding more efficient! 🚀📸 #AI #VisionLanguage #TechInnovation rpst.cc/oMa5DZ

🚨 New model alert! 🚨 We've added OpenGVLab InternVL3_5-2B! It's a vision-language model. Get it running in LocalAI with: `local-ai run opengvlab_internvl3_5-2b` 😉 #LocalAI #VisionLanguage #NewModel

🎙️ AI Frontiers: Vision-Language Integration Breakthroughs (Aug 17, 2025) #AIFrontiers #VisionLanguage #MultimodalAI Watch full episode: youtube.com/watch?v=i08Hly…

youtube.com
YouTube
AI Frontiers: Vision-Language Integration Breakthroughs (Aug 17, 2025)

Explore now → github.com/rednote-hilab/… #OCR #VisionLanguage #AI #opensource #MachineLearning


Great to see NVIDIA releasing a huge vision-language dataset with 3M samples! Open datasets like this will help accelerate research in OCR, VQA and captioning tasks. Excited to see what developers build with it. #AI #VisionLanguage

We just released 3 million samples of high quality vision language model training dataset for use cases such as: 📄 optical character recognition (OCR) 📊 visual question answering (VQA) 📝 captioning 🤗 Learn more: nvda.ws/4oyfevu 📥 Download: nvda.ws/4fz2gtB
MiniGPT-4: Enhancing vision-language understanding using advanced large language models for multi-task learning. #AI #VisionLanguage #LLM #MachineLearning

💡 Dynamic Token Compression in DeepSeek-VL: ✂️ 40% fewer tokens for high-res images 📊 +3.1% accuracy on TextVQA Code: github.com/deepseek-ai/vl… #VisionLanguage @PublicAI_ @PublicAIData @DataBabies333

🚨 @ICCVConference 2025🚨 Happy to share that our paper: Visual Modality Prompt for Adapting Vision-Language Object Detectors was accepted at #ICCV2025 📄 Paper : arxiv.org/abs/2412.00622 💻 Code: github.com/heitorrapela/M… #ComputerVision #VisionLanguage #ObjectDetection #VLMs





MY FIRST STEP IS TO PLANT MY SEEDS WHEREVER I CAN PLANT THEM #ViSiONLANGUAGE LIVING 4EVA IS DA GOAL #2000NOW


Discover FastVLM, a breakthrough in Vision Language Models that boosts image resolution and speeds up processing, making text-rich image understanding more efficient! 🚀📸 #AI #VisionLanguage #TechInnovation rpst.cc/oMa5DZ
📢Join us for our #ImageInWords poster presentation on Nov 12th, 11:00-12:30pm at #EMNLP . We'll be diving deep into hyper-detailed image descriptions and the impact on #VisionLanguage models. See you there!👋 #NLProc #ComputerVision @emnlpmeeting @AndreaDBurns @GoogleDeepMind 🧵
Back from the break with Phillip Isola @phillip_isola on “On the Perceptual Distance Between Images and Text.” A fascinating and interactive look at how models (and humans!) measure similarity 👏🏻 #HiCV2025 #ICCV2025 #VisionLanguage
HELLO WORLD........ #4500FILMS & #ViSiONLANGUAGE #MUUG #MagicalUnionUnderGOD @nuthouseradio L.A.G. COMING SOON!!!!

[1/4] We tested InternVL3.5-aligned GPT-OSS on MMMU and found visual alignment gaps: misreads, shallow grounding, and repetition. It’s an early step, not the solution—good scaffolding, weak seeing. #Multimodal #VisionLanguage
In 2023, researchers launched VisIT-Bench, a benchmark with 592 vision-language tasks spanning 70 categories like plot analysis and art knowledge. #AI #VisionLanguage @Stanford
🚀 Thrilled to announce our paper "TG-LLaVA: Text Guided LLaVA" accepted by @AAAI! We enhance vision encoders with text guidance, boosting performance without extra data. Huge thanks to the team! #AI #VisionLanguage
Thrilled to see ERNIE 4.5 VL earn a top spot on the latest SuperCLUE-VLM benchmark. Time to build something new with vision!👀 #AI #Multimodal #VisionLanguage #LLM #Benchmark #ERNIE
1/5 🖼️📚Introducing a new approach for vision-language pre-training: "Efficient Vision-Language Pre-training by Cluster Masking." This method enhances visual-language contrastive learning with a novel masking technique. #AI #MachineLearning #VisionLanguage
1/5 🌐"On the Test-Time Zero-Shot Generalization of Vision-Language Models: Do We Really Need Prompt Learning?" This paper explores the necessity of prompt learning for VLMs. #AI #MachineLearning #VisionLanguage
1/5 🗣️"MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs." This benchmark evaluates LVLMs in complex dialog scenarios involving multiple images. #AI #MachineLearning #VisionLanguage


🔍 𝗪𝗵𝗮𝘁’𝘀 𝗻𝗲𝘄? We propose a new approach to fine-tuning large Vision-Language Models (VLMs) on resource-constrained clients in Federated Learning—essential for healthcare, where privacy matters most. #FederatedLearning #VisionLanguage #FoundationModels

🚨 @ICCVConference 2025🚨 Happy to share that our paper: Visual Modality Prompt for Adapting Vision-Language Object Detectors was accepted at #ICCV2025 📄 Paper : arxiv.org/abs/2412.00622 💻 Code: github.com/heitorrapela/M… #ComputerVision #VisionLanguage #ObjectDetection #VLMs
🔍 Today's top pick from @powerdrill Research Digest: 'Training-Free Unsupervised Prompt for Vision-Language Models'. Check out the link for a summary: app.powerdrill.ai/s/1jB88R #AI #VisionLanguage #Research

AI Model Unlocks a New Level of Image-Text Understanding 🔍📷✨ azoai.com/news/20241103/… #AI #MachineLearning #VisionLanguage #ImageText #ProLIP #ZeroShot #UncertaintyModeling #Innovation #DeepLearning #FutureTech @NAVER_AI_Lab

🔥 Discover the fascinating world of Multimodal Foundation Models, with the journey "From Specialists to General-Purpose Assistants" 🌐 Dive into the evolution of large models in #ComputerVision & #VisionLanguage! Paper: arxiv.org/abs/2309.10020 Tutorial: vlp-tutorial.github.io/2023/
Multimodal Foundation Models: From Specialists to General-Purpose Assistants paper page: huggingface.co/papers/2309.10… paper presents a comprehensive survey of the taxonomy and evolution of multimodal foundation models that demonstrate vision and vision-language capabilities,…
Something went wrong.
Something went wrong.
United States Trends
- 1. #DWTS 2,691 posts
- 2. Louisville 81.4K posts
- 3. Virginia 243K posts
- 4. Abigail Spanberger 25.1K posts
- 5. Jets 134K posts
- 6. MD-11 17.9K posts
- 7. Flav N/A
- 8. Jay Jones 28.7K posts
- 9. Honolulu 8,312 posts
- 10. #OlandriaxGlamourWOTY 2,498 posts
- 11. UPS Flight 2976 15.6K posts
- 12. Jared 27.4K posts
- 13. #AreYouSure2 48.6K posts
- 14. Miyares 15.3K posts
- 15. Azzi 7,361 posts
- 16. Colts 65.2K posts
- 17. #いい推しの日 820K posts
- 18. Fletcher Loyer N/A
- 19. #ShootingStar N/A
- 20. Carrie Ann N/A