#byt5 搜尋結果


🔁 RT if you work on low-resource NLP / linguistically rich languages. #SanskritNLP #LLMs #ByT5 #LowResourceNLP #Anvaya

Boosting the performance of text-to-image models with customized text encoders. #TexttoImage #TextEncoder #ByT5


Semoga azab Allah segera ditimpakan kpd aparat2 dzalim... --> AliBaharsyah <-- #byt5
So at @NarrativaAI we have fine-tuned the first #ByT5 model (small) on the @huggingface model hub. The dataset is: tweets hate speech detection and we got an accuracy of: 97.8 %! Try it out: huggingface.co/mrm8488/byt5-s… #NLP #NLP #Text2Text


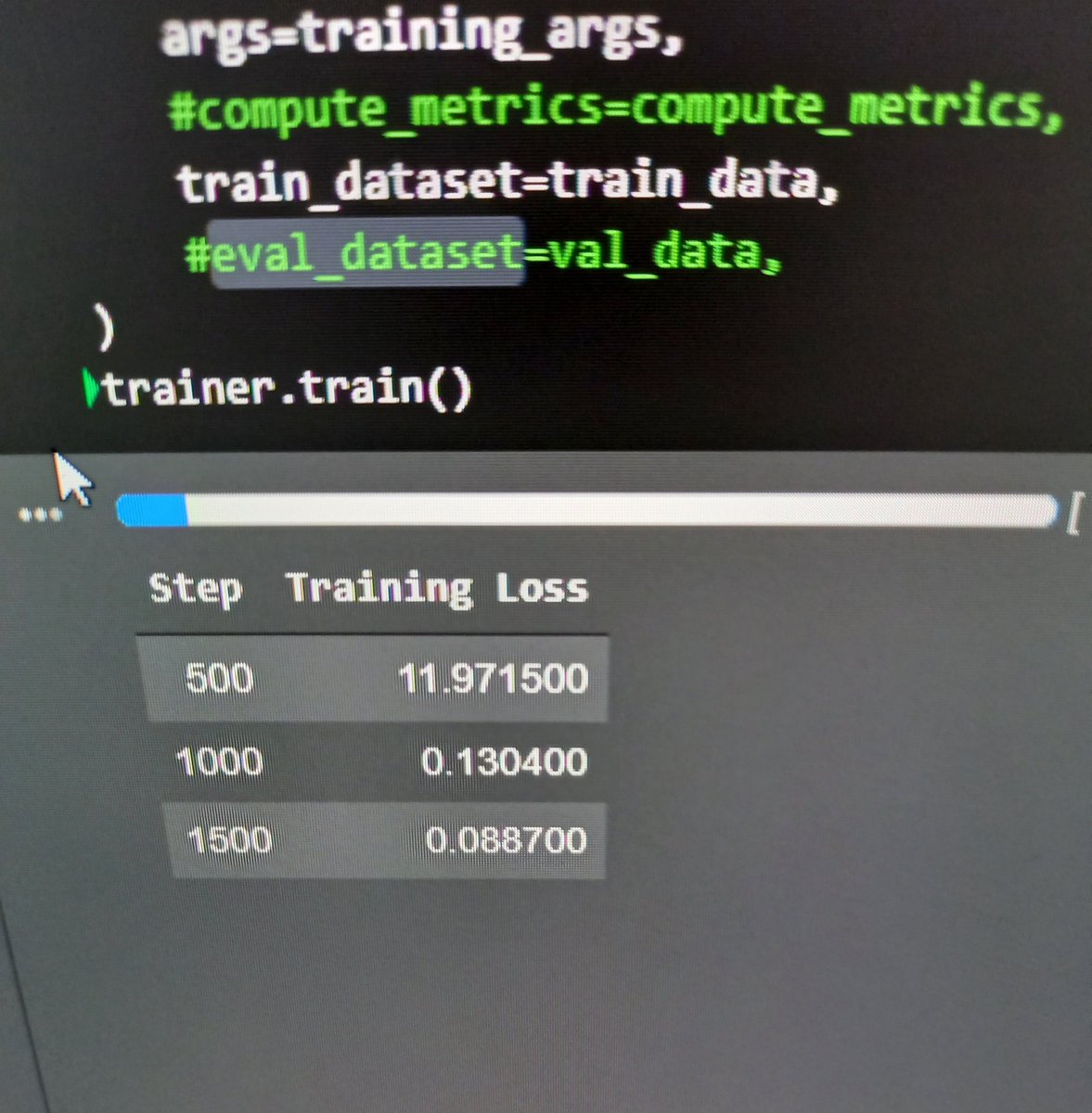
🚀 And merged to Transformers! We are excited to welcome ByT5 as the first tokenizer-free model! 👉All available checkpoints can be accessed on the 🤗hub here: huggingface.co/models?filter=… 👇 Demo (on master):

RT ByT5: Towards a token-free future with pre-trained byte-to-byte models dlvr.it/S1FDFh #byt5 #artificialintelligence #machinelearning #nlp #research


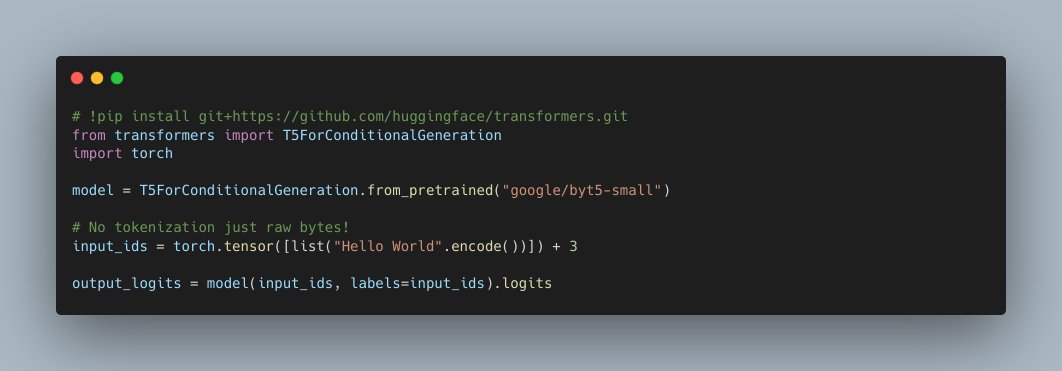
#ByT5 is a byte-level Transformer model, which means that it operates directly on raw text (bytes or characters) instead of tokens. This can be beneficial as it can process text in any language out of the box.


🎙️ In my latest podcast, get familiar with the nitty-gritty of ByT5. Discover how this token-free model is language-agnostic, more robust, and simplifies preprocessing. Tune in now: shorturl.at/hcFwo #Podcast #AI #ByT5
Curious about the next big thing in NLP? Introducing ByT5: a revolutionary model that processes text as bytes, bypassing tokenization. Want to dive deep into how this works and its advantages? Listen to my latest podcast for an in-depth exploration! #NLP #AI #ByT5 #TechInnovation

My latest piece on ByT5, the token-free model introduced by Google. What it is, and what it might mean for SEO. ➡️ ByT5: What It Might Mean For SEO ➡️ beanstalkim.com/learn/seo/byt5… #MachineLearning #SEO #ByT5 #Google

My new work on sexism detection using ByT5 and TabNet is finally out ceur-ws.org/Vol-3202/exist… Despite results not being super some important lessons were learned; a 🧵 #multilingualtextclassification #byt5 #tokenfreemodels
Hivemind and specially those who may have used ByT5 for multilingualistic text data is it worth it to try to train separate models for separate languages (the text here is tweets)? #byt5 #languagemodels #NLProc

#OCR errors are a common side-effect when processing scanned documents 🔍🖨️. In our latest #NLProc blogpost, @simon_de_gheselle investigates the use of @GoogleAI’s #ByT5 to correct these errors 💡👆! Full blogpost: hubs.la/Q010QBj60 #ml6 #transformers #huggingface
🔁 RT if you work on low-resource NLP / linguistically rich languages. #SanskritNLP #LLMs #ByT5 #LowResourceNLP #Anvaya
🎙️ In my latest podcast, get familiar with the nitty-gritty of ByT5. Discover how this token-free model is language-agnostic, more robust, and simplifies preprocessing. Tune in now: shorturl.at/hcFwo #Podcast #AI #ByT5
Curious about the next big thing in NLP? Introducing ByT5: a revolutionary model that processes text as bytes, bypassing tokenization. Want to dive deep into how this works and its advantages? Listen to my latest podcast for an in-depth exploration! #NLP #AI #ByT5 #TechInnovation
Boosting the performance of text-to-image models with customized text encoders. #TexttoImage #TextEncoder #ByT5
#ByT5 is a byte-level Transformer model, which means that it operates directly on raw text (bytes or characters) instead of tokens. This can be beneficial as it can process text in any language out of the box.
My new work on sexism detection using ByT5 and TabNet is finally out ceur-ws.org/Vol-3202/exist… Despite results not being super some important lessons were learned; a 🧵 #multilingualtextclassification #byt5 #tokenfreemodels
Hivemind and specially those who may have used ByT5 for multilingualistic text data is it worth it to try to train separate models for separate languages (the text here is tweets)? #byt5 #languagemodels #NLProc
#OCR errors are a common side-effect when processing scanned documents 🔍🖨️. In our latest #NLProc blogpost, @simon_de_gheselle investigates the use of @GoogleAI’s #ByT5 to correct these errors 💡👆! Full blogpost: hubs.la/Q010QBj60 #ml6 #transformers #huggingface
My latest piece on ByT5, the token-free model introduced by Google. What it is, and what it might mean for SEO. ➡️ ByT5: What It Might Mean For SEO ➡️ beanstalkim.com/learn/seo/byt5… #MachineLearning #SEO #ByT5 #Google
RT ByT5: Towards a token-free future with pre-trained byte-to-byte models dlvr.it/S1FDFh #byt5 #artificialintelligence #machinelearning #nlp #research
So at @NarrativaAI we have fine-tuned the first #ByT5 model (small) on the @huggingface model hub. The dataset is: tweets hate speech detection and we got an accuracy of: 97.8 %! Try it out: huggingface.co/mrm8488/byt5-s… #NLP #NLP #Text2Text
🚀 And merged to Transformers! We are excited to welcome ByT5 as the first tokenizer-free model! 👉All available checkpoints can be accessed on the 🤗hub here: huggingface.co/models?filter=… 👇 Demo (on master):
Semoga azab Allah segera ditimpakan kpd aparat2 dzalim... --> AliBaharsyah <-- #byt5

Boosting the performance of text-to-image models with customized text encoders. #TexttoImage #TextEncoder #ByT5
Semoga azab Allah segera ditimpakan kpd aparat2 dzalim... --> AliBaharsyah <-- #byt5
RT ByT5: Towards a token-free future with pre-trained byte-to-byte models dlvr.it/S1FDFh #byt5 #artificialintelligence #machinelearning #nlp #research
Something went wrong.
Something went wrong.
United States Trends
- 1. #SpotifyWrapped 172K posts
- 2. Chris Paul 23.6K posts
- 3. Clippers 34.8K posts
- 4. #HappyBirthdayJin 74.9K posts
- 5. Hartline 6,136 posts
- 6. GreetEat Corp N/A
- 7. South Florida 5,029 posts
- 8. $MSFT 13.8K posts
- 9. #NSD26 19.9K posts
- 10. David Corenswet 2,134 posts
- 11. #OurSuperMoonJin 62.3K posts
- 12. #WorldwideHandsomeJin 61.3K posts
- 13. Jonathan Bailey 3,487 posts
- 14. ethan hawke 2,364 posts
- 15. Collin Klein 1,303 posts
- 16. Henry Cuellar N/A
- 17. Good Wednesday 36.9K posts
- 18. Chris Klieman 1,311 posts
- 19. Chris Henry N/A
- 20. Apple Music 275K posts