#convolutional_denoising_autoencoder kết quả tìm kiếm

80% data reduction while keeping 98.2% of the performance is a massive efficiency win. The real unlock here is the "Coupled Optimization" (hence CoIDO). As shown in the diagram, previous methods like TIVE treated importance and diversity as separate, independent phases—often…

A further nuance: DLSS & denoising is generative AI. Animation cleanup, LOD generation, procedural texturing & compression. As long as you: - use your own or open data AND - design from intelligent creative first principles You can't do wrong by anyone, and A"I" can't replace you

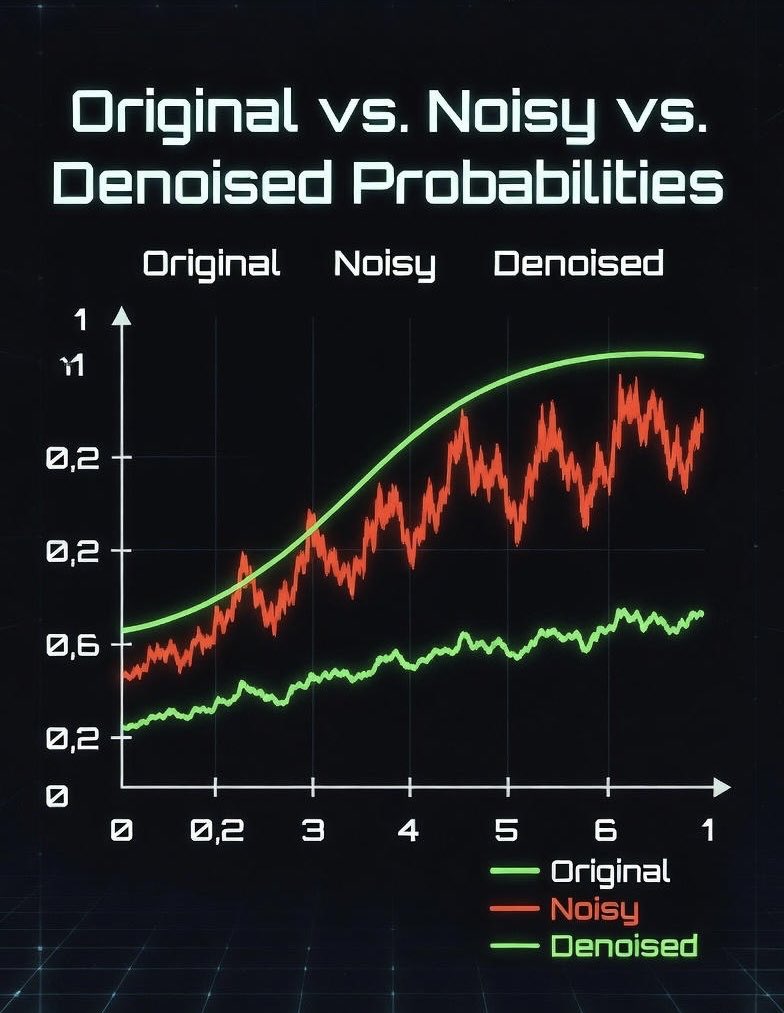
Orina.io just proved: Noise breaks AI → we fix it better than anyone. Original peak 55% → Noisy chaos → Denoised stability. This is what "super denoising + meta-divergence" looks like. Watch the chart. The future is consistent. 🔥 #OrinaIO #SuperDenoising…

Ok that’s fair. Yes. A deterministic denoising algorithm can essentially create any image within the bounds of the noise samples it has. You can add your own training data to fine tuned models and lora.

The basic question, really, is what this means. Like, are you continuously tokenizing text, denoising continuous pre embedding repr? Are you discrete codebook tokenizing and noising/denoising the embeddings for the discrete codes?

By the way, one intuition I like about descent on the spectral norm is the update is *invariant to the input distribution* for certain loss landscapes (specifically, gradients that are orthogonal transformations of the input vector) From our recent blog: kvfrans.com/matrix-whiteni…

🔬 Excited to share the publication "Applying Self-Supervised Learning to Image Quality Assessment in Chest CT Imaging" 👉 mdpi.com/2306-5354/11/4… #self_supervised_learning #feature_representation_learning #convolutional_denoising_autoencoder #task_based_approach #chest #CT


A good denoiser learns the geometry of the image manifold. Thus it makes perfect sense to use denoisers to regularize ill-posed problems. This was a key reason we proposed Regularization by Denoising (RED) in 2016. A modest landmark in citations, but big impact in practice 1/4


A short extension post: While Tweedie is known to many, its extensions aren’t. What is less known is that we can not only get denoiser mean, but also its covariance, which is related to curvature of the log-density.

Tweedie's formula is super important in diffusion models & is also one of the cornerstones of empirical Bayes methods. Given how easy it is to derive, it's surprising how recently it was discovered ('50s). It was published a while later when Tweedie wrote Stein about it 1/n


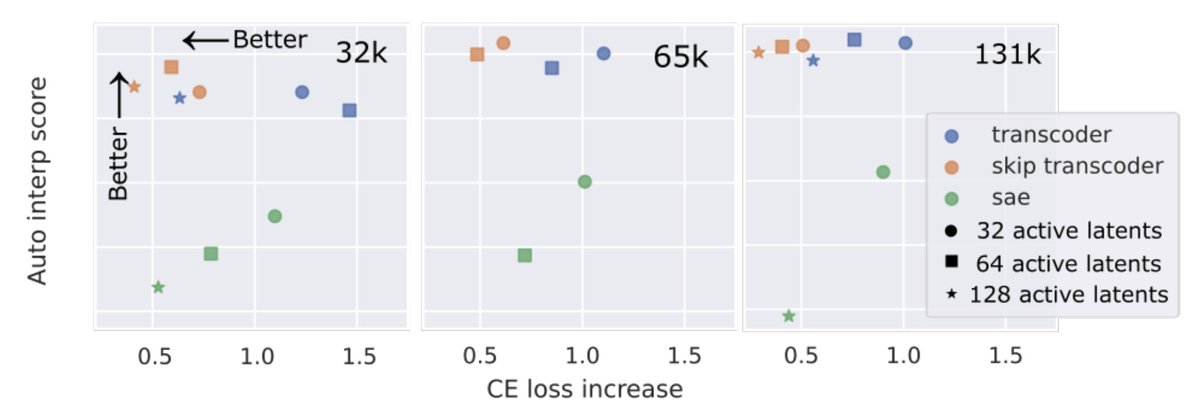
Yeah, we think sparse autoencoders (SAEs) aren’t that hard to beat at all…. github.com/stanfordnlp/ax…


Sparse autoencoders (SAEs) have taken the interpretability world by storm over the past year or so. But can they be beaten? Yes! We introduce skip transcoders, and find they are a Pareto improvement over SAEs: better interpretability, and better fidelity to the model 🧵

Decided to start a new blog series about model architectures in the era of LLMs. 😀 Here's part 1 on broader architectures like Transformer Encoders/Encoder-Decoders, PrefixLM and denoising objectives. 😄 A frequently asked question: "The people who worked on language and NLP…


🥳 I just open-sourced the web port of Open Image Denoise: github.com/pissang/oidn-w… It has been integrated into Vector to 3D for weeks. It significantly reduces users' render time and usually produces very clean results. Huge thanks to the hard work of the OIDN team for creating…


But now, that hard scientific problem has effectively been solved. We can "decompose" each neuron that does multiple things into sub-units, that reliably do a single thing. (using something called "sparse autoencoders")

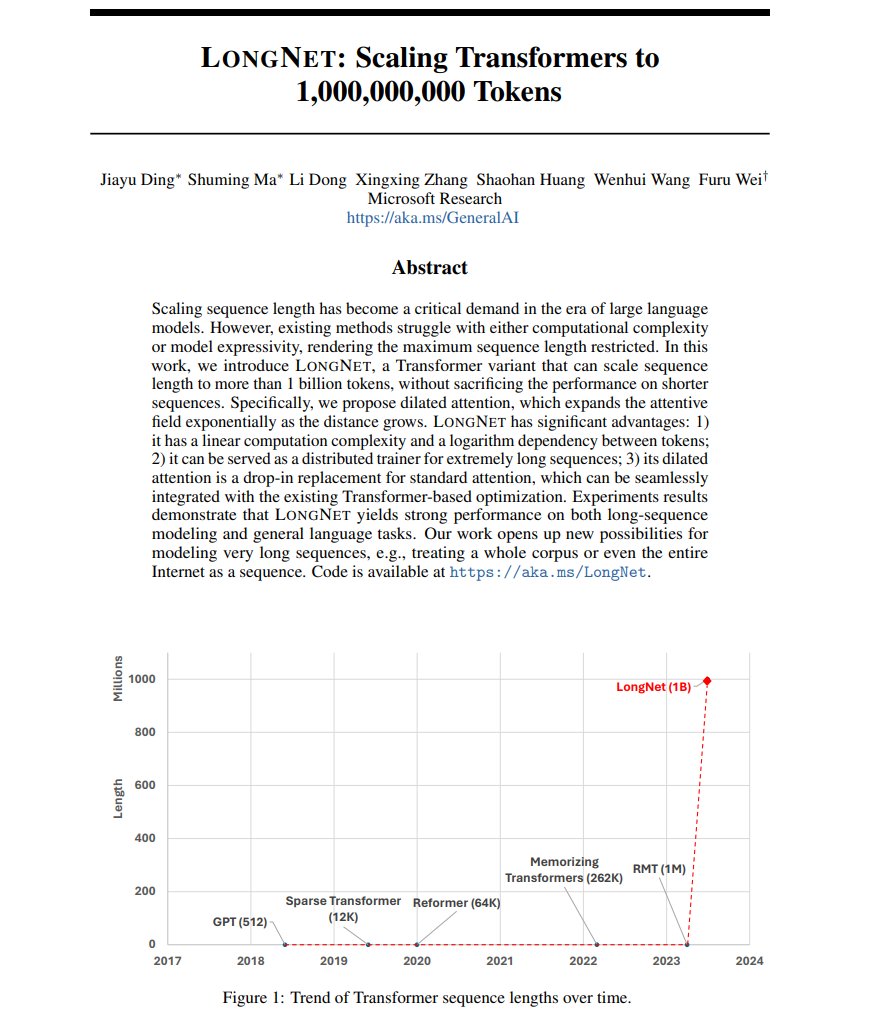
One. Billion. Tokens. Context Window. 🤯 I didn't want to get sucked into twitter but I couldn't help it. Here is how they do it: Dilated Attention They use an approach similar to dilated convolutions: "convolutions with holes" that are expanding as the depth of the network…


LongNet: Scaling Transformers to 1,000,000,000 Tokens Presents LONGNET, a Transformer variant that can scale sequence length to more than 1 billion tokens, without sacrificing the performance on shorter sequences abs: arxiv.org/abs/2307.02486 repo: github.com/microsoft/torc…

I tried spherical harmonics for diffuse part of denoiser to preserve as much details as possible, especially in movement (also it allows to use more aggressive denoise). I use YCoCg and only Y in SH just like in developer.download.nvidia.com/video/gputechc…

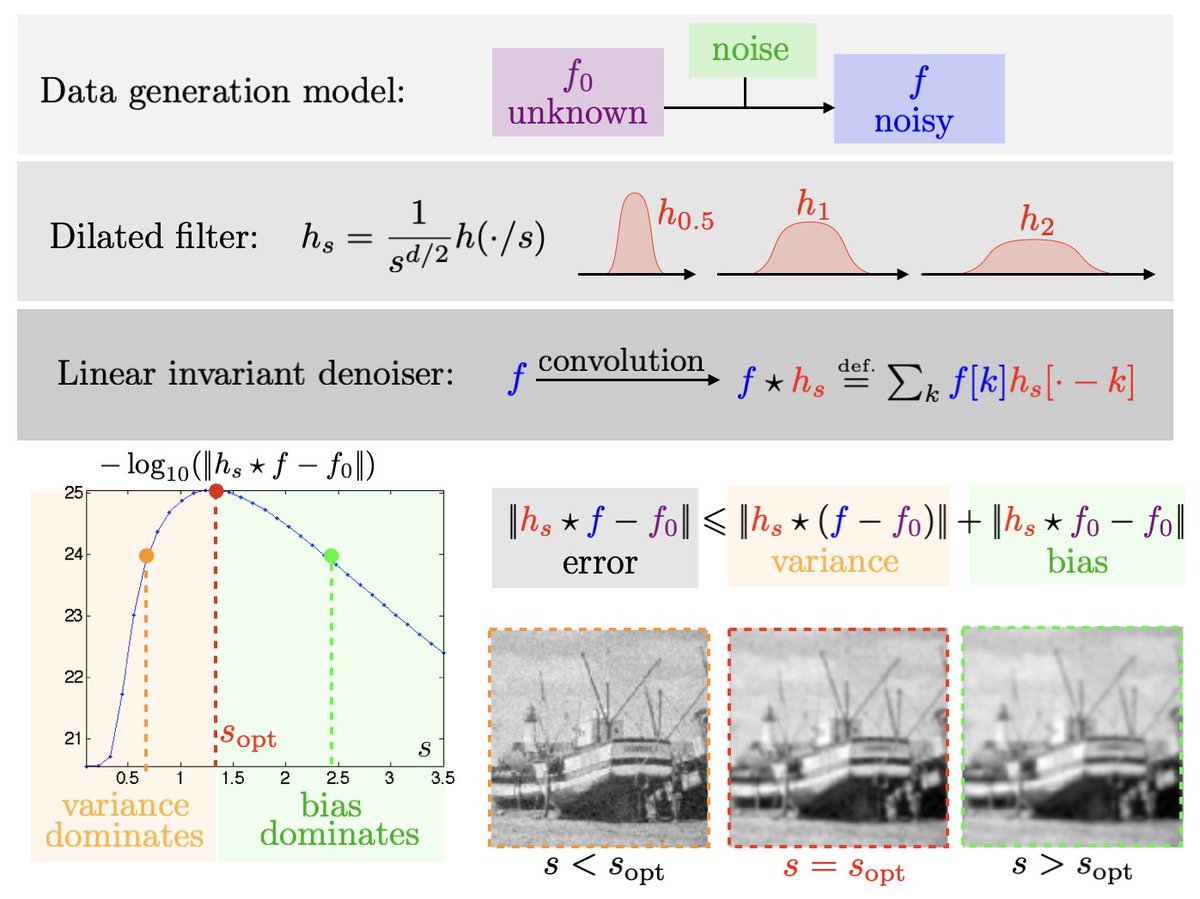
Finding the optimal denoising parameter is a bias-variance tradeoff. en.wikipedia.org/wiki/Bias%E2%8… en.wikipedia.org/wiki/Noise_red… nbviewer.jupyter.org/github/gpeyre/…

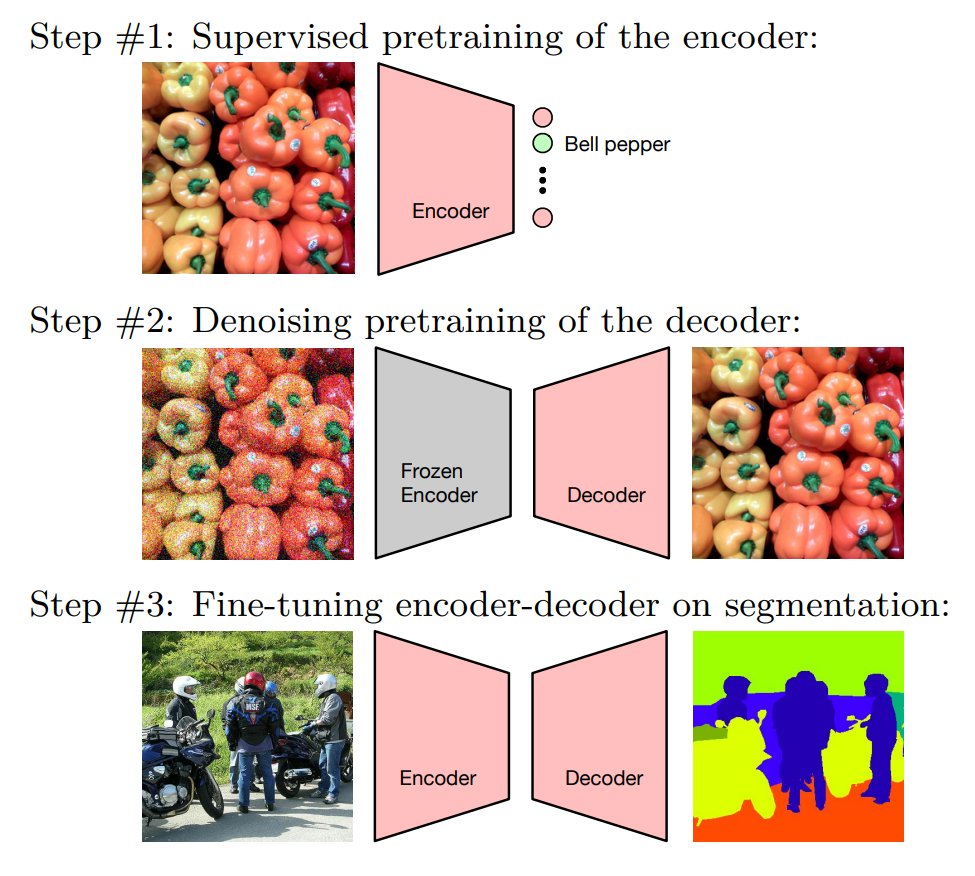
Decoder Denoising Pretraining for Semantic Segmentation: A fun and simple idea for pre-training the decoder for semantic segmentation arxiv.org/abs/2205.11423 1/

Been looking to learn about self-supervised learning--denoising AE, context encoders*, rotation prediction*, jigsaw, CPC, MoCo, SimCLR*? Colab with tutorial-demos* now released: github.com/rll/deepul/blo… (by @WilsonYan8) Full lecture: youtu.be/dMUes74-nYY (by @Aravind7694)

youtube.com
YouTube
Lecture 7 Self-Supervised Learning -- UC Berkeley Spring 2020 -...
Something went wrong.
Something went wrong.
United States Trends
- 1. The AsterDEX 44.6K posts
- 2. Pro Bowl 17.2K posts
- 3. Happy Festivus 2,886 posts
- 4. Christmas Eve Eve 59.6K posts
- 5. The AAVE 199K posts
- 6. FINALLY DID IT 565K posts
- 7. Cam Jurgens N/A
- 8. #AvengersDoomsday 117K posts
- 9. The PENGU 219K posts
- 10. Jordan Davis N/A
- 11. #NXXTHelpsSF N/A
- 12. Ben Sasse N/A
- 13. Derrick Brown N/A
- 14. Larry Nassar 15.6K posts
- 15. Joe Alt N/A
- 16. The WET 22.6K posts
- 17. Happy Holidays 105K posts
- 18. NextNRG Inc N/A
- 19. Nashon Wright N/A
- 20. Jalen Carter N/A