#distributedprocessingn 搜索结果

Distributed training on M4 Mac Mini cluster We implemented @GoogleDeepMind DiLoCo on Apple Silicon to train large models with 100-1000x less bandwidth compared to DDP baseline. AI is entering a new era where a distributed network of consumer devices can train large models.

We've reached a major milestone in fully decentralized training: for the first time, we've demonstrated that a large language model can be split and trained across consumer devices connected over the internet - with no loss in speed or performance.


Continuous diffusion had a good run—now it’s time for Discrete diffusion! Introducing Anchored Posterior Sampling (APS) APS outperforms discrete and continuous baselines in terms of performance & scaling on inverse problems, stylization, and text-guided editing.

Requests in. Results out. Rewards distributed. Each inference = an on-chain proof + a GPU payout in $DIS.


Multi-Agent Systems & Swarm Intelligence DDS (Data Distribution Service) enables multiple robots to communicate and coordinate using a mesh network topology. Each agent shares its state with others to achieve complex group behaviors that no single robot could accomplish alone.…

Answer: yes. It’s called the shared computer. techround.co.uk/artificial-int…


The growth of AI depends on distributed power. Millions of personal devices are starting to act like miniature data centers. Every connected GPU moves us closer to a networked intelligence that belongs to everyone. You ready for this?

Introducing Paris - world's first decentralized trained open-weight diffusion model. We named it Paris after the city that has always been a refuge for those creating without permission. Paris is open for research and commercial use.

We just put out a key step for making distributed training work at larger and larger models: Scaling Laws for DiLoCo TL;DR: We can do LLM training across datacenters in a way that scales incredibly well to larger and larger models!


Introducing Parallax, the first fully distributed inference and serving engine for large language models. Try it now: chat.gradient.network 🧵

Scalability! But at what cost? This paper is an absolute classic because it explores the underappreciated tradeoffs of distributing systems. It asks about the COST of distributed systems--the Configuration that Outscales a Single Thread. The question is, how many cores does a…


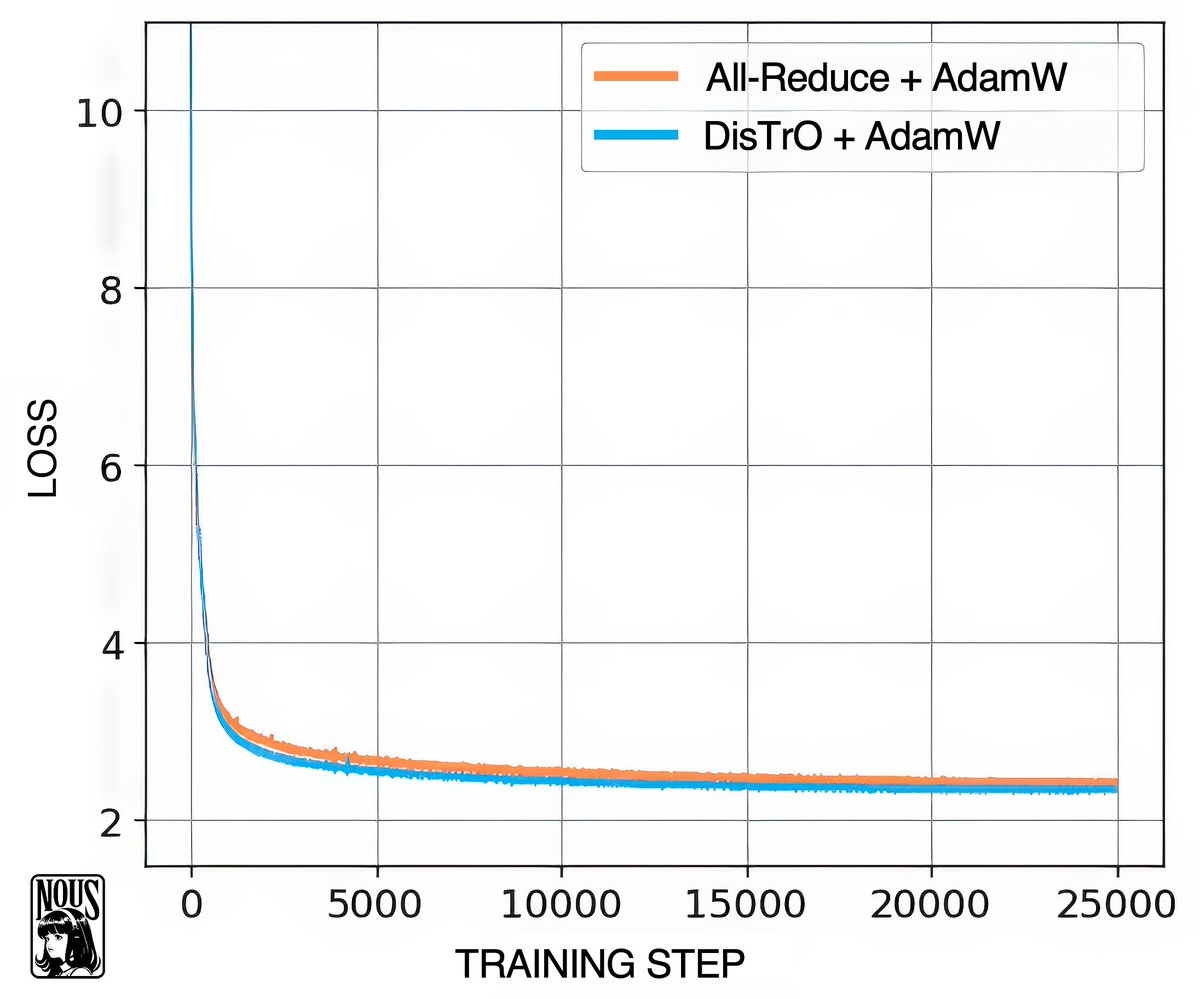
What if you could use all the computing power in the world to train a shared, open source AI model? Preliminary report: github.com/NousResearch/D… Nous Research is proud to release a preliminary report on DisTrO (Distributed Training Over-the-Internet) a family of…

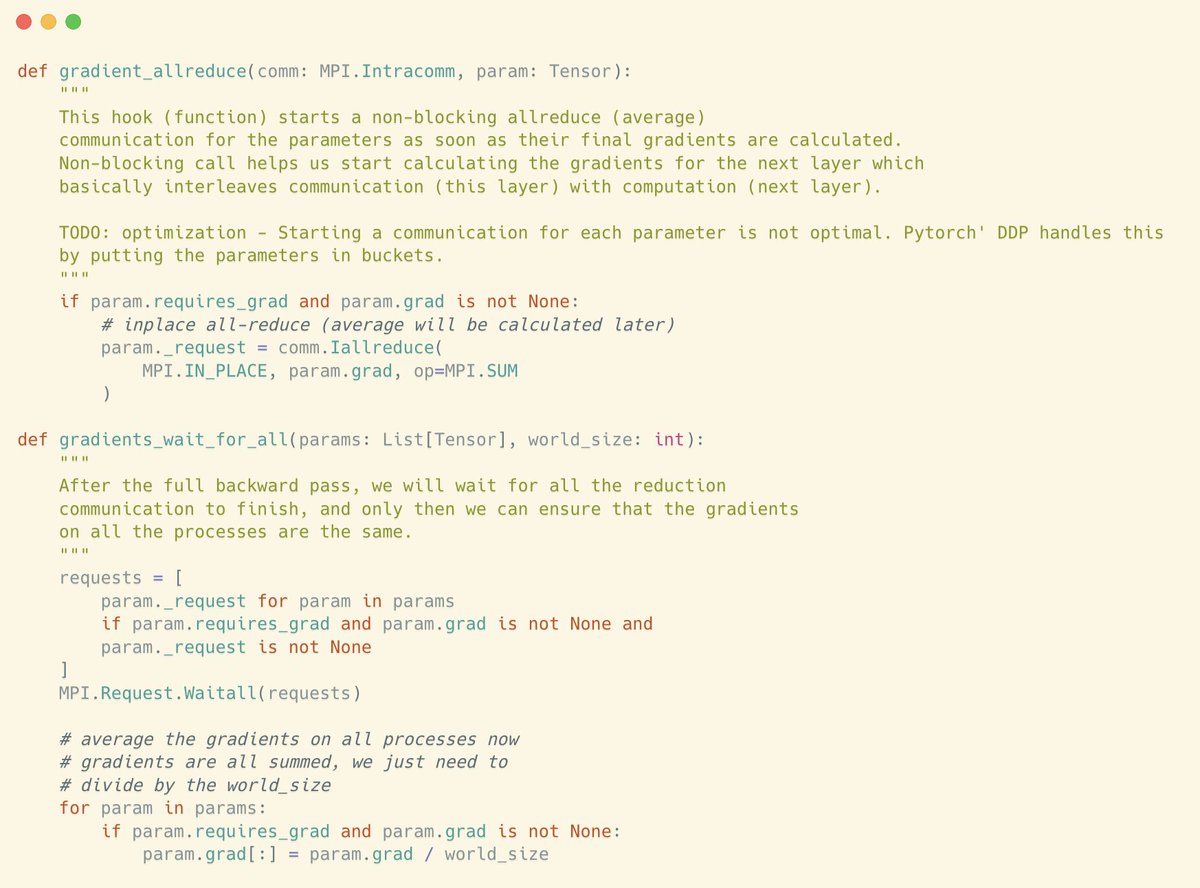
understanding DDP is easy: these two functions are technically all you need to implement Distributed Data Parallel (DDP) model similar to PyTorch, from scratch.

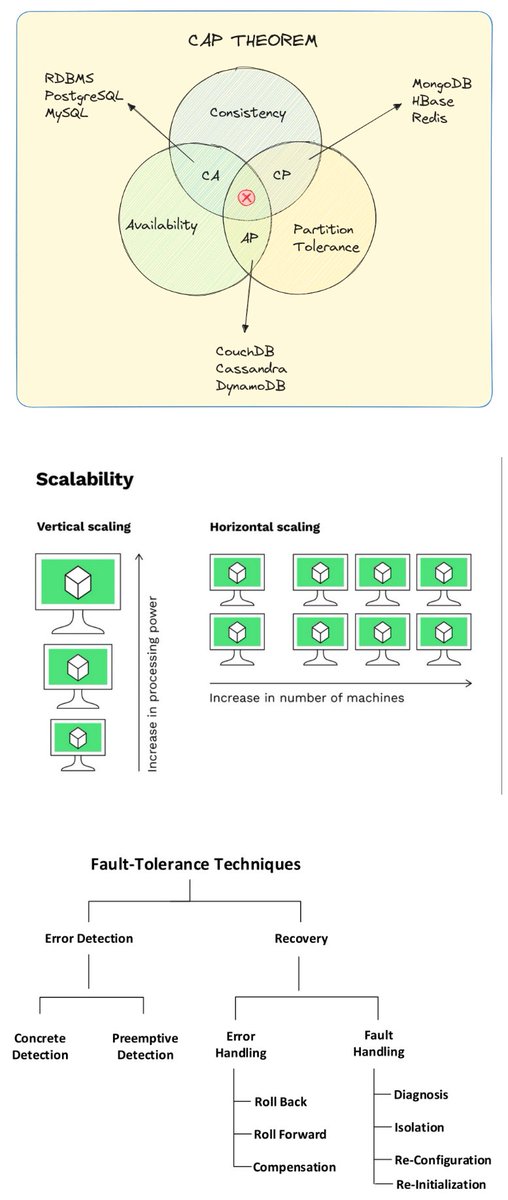

We’re deep in R&D on Poseidon Subnets – specialized data pipelines that coordinate how AI domains collect, curate, and license real-world data. Think of them as high-throughput lanes in the world’s first decentralized data highway. More to come 🔱


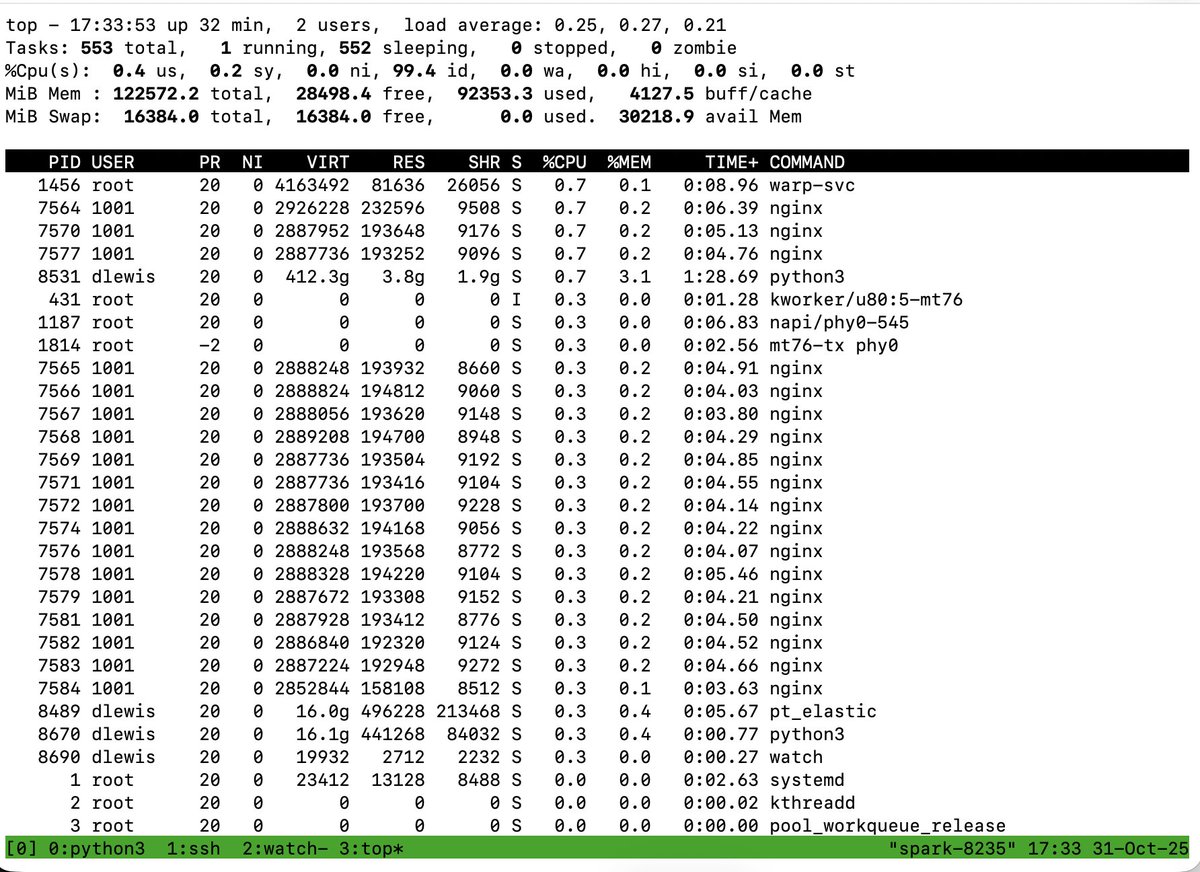
You probably wouldn't know it from this top output, but I have a FSDP training run going on the DGX Spark cluster. No wasted CPU time spent processing interrupts or copying between buffers. RDMA networking is a wonderful thing.







Something went wrong.
Something went wrong.
United States Trends
- 1. VMIN 25.7K posts
- 2. Good Saturday 20.6K posts
- 3. #SaturdayVibes 3,210 posts
- 4. Nigeria 468K posts
- 5. Chovy 13K posts
- 6. seokjin 237K posts
- 7. #LoVeMeAgain 35.5K posts
- 8. VOCAL KING TAEHYUNG 37.9K posts
- 9. Social Security 45.3K posts
- 10. New Month 303K posts
- 11. #SaturdayMotivation 1,123 posts
- 12. Spring Day 57.3K posts
- 13. Big Noon Kickoff N/A
- 14. GenG 21.8K posts
- 15. Merry Christmas 11.8K posts
- 16. #saturdaymorning 1,481 posts
- 17. #AllSaintsDay 1,276 posts
- 18. IT'S GAMEDAY 1,473 posts
- 19. Game 7 79.5K posts
- 20. Shirley Temple 1,165 posts