#llmreasoning search results

New paper Agentsway — Software Development Methodology for AI Agents-based Teams #agenticAI #LLMReasoning #softwareEngineering #gptoss #LLM arxiv.org/abs/2510.25588

Another paper... Standardization of Psychiatric Diagnoses — Role of Fine-tuned LLM Consortium and OpenAI-gpt-oss Reasoning LLM Enabled Decision Support System #neuroscience #llm #llmReasoning #psychiatry #gptoss #paper #openAI #responsibleAI arxiv.org/abs/2510.25588


🤝 Echo & Expand work best together. Figure 4 shows real case studies: Alone, each has blind spots. Combined, LoT prompts offer more robust understanding. #LLMreasoning #CaseStudy

🚀 LLM reasoning is exploding! From 2022 to 2025, research has skyrocketed (see Fig. 1). Let’s explore the frontiers: inference scaling, learning to reason, and agentic systems. #AI #LLMReasoning arxiv.org/pdf/2504.09037


(1/3) Why care? Current LLMs under “shallow-alignment” just say “Sorry…”—easy prey for jailbreak attacks. STAIR incorporates System2 thinking with safety alignment, teaching models to think through risks first, then answer or refuse. #LLMSafety #LLMReasoning #SafeAI


GitHub - DebarghaG/proofofthought: "Proof of thought: Neurosymbolic program synthesis allows robust and interpretable reasoning" published Sys2Reasoning Workshop NeurIPS 2024 #LLMReasoning #Z3TheoremProving #NeurosymbolicAI Article Highlights kontxt.io/document/d/wf9…


Howz.ai is on sale! #housesforsale #AIイラスト #LLMReasoning #homemade #realestateu #ai171 @a16z #NFT #AgenticAI


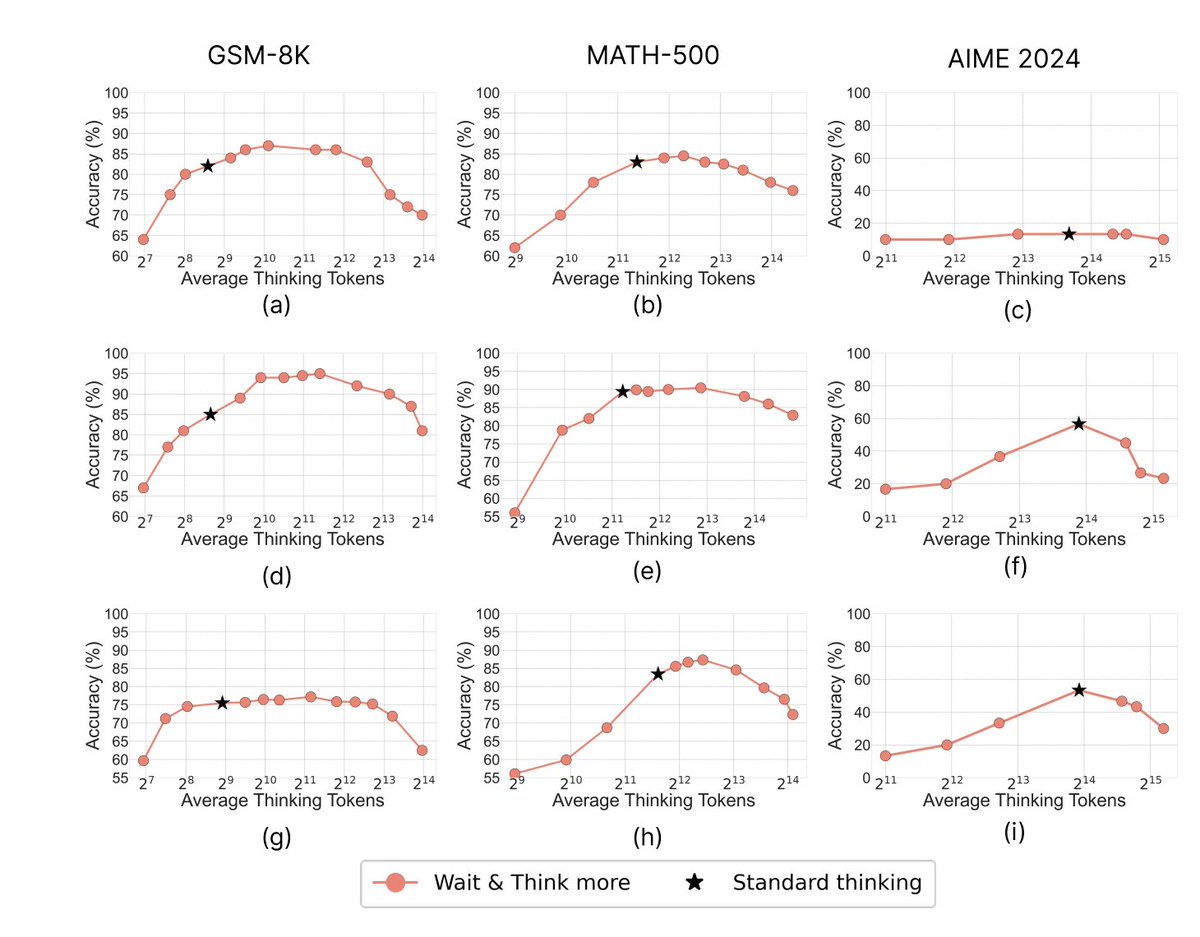
🔥 Does test-time scaling in #reasoningmodels via thinking more always help? 🚫 Answer is No - Performance increases first and then drops due to #Overthinking ❓Why is this behaviour and how to mitigate 🚀 Check our recent findings #LLMReasoning Link: arxiv.org/pdf/2506.04210


New research suggests Large Language Models (LLMs) are masterful pattern matchers but struggle with true logical reasoning in complex, novel problems. Is this the AGI bottleneck? Let's dive in. 👇 #AIThread #LLMReasoning #ArtificialGeneralIntelligence #DeepLearning

Enhancing LLM Reasoning with Multi-Attempt Reinforcement Learning #MultiAttemptRL #LLMReasoning #ReinforcementLearning #AIInnovation #SelfCorrection itinai.com/enhancing-llm-…


This article introduces RECKONING, a novel method utilizing bi-level optimization to teach language models to reason - hackernoon.com/reckoning-meth… #llm #llmreasoning



📖 Chapter 4: AI-powered literature review Leverage Activeloop’s L0 reasoning model with Deep Lake to run multimodal literature reviews, extract key insights, and answer complex questions more efficiently than manual methods. #LiteratureMining #LiteratureReview #LLMReasoning

📊 This isn’t just AI learning to reason. It’s AI learning to adapt, act, and deliver in the wild. Zoro is building the bridge from research to reality. #ZoroAI #AgentEconomy #LLMReasoning #Web3AI #CollectiveIntelligence #OnChainAI
Meet Satori: A New AI Framework for Advancing LLM Reasoning through Deep Thinking without a Strong Teacher Model #SatoriAI #LLMReasoning #ArtificialIntelligence #MachineLearning #InnovationInAI itinai.com/meet-satori-a-…

Understanding LLM Reasoning: A Framework for AI Researchers and Industry Professionals #LLMReasoning #AITransparency #HealthcareAI #FinanceAI #MachineLearning itinai.com/understanding-… Understanding how large language models (LLMs) reason is crucial for their effective applicati…

GPT-4.5 and Llama 4 got muted reactions—they lack RL for reasoning. xAI and Anthropic use RL and “thinking” toggles for deeper cognition. As scaling plateaus, RL-driven reasoning is the new LLM edge. @rasbt #ReinforcementLearning #LLMReasoning #AITraining magazine.sebastianraschka.com/p/the-state-of…


Master the Art of Prompt Engineering with Least to Most Prompting 𝐋𝐞𝐚𝐫𝐧 𝐌𝐨𝐫𝐞 👉 buff.ly/3DYLO70 #PromptEngineering #AI #LLMReasoning #AITraining #ArtificialIntelligence #NLP


What are the fundamental inference-time techniques for enhancing large language model reasoning? #AISafety #AgentSystems #LLMReasoning #TechInnovation #AdvanceAgentsMOOC Reference: llmagents-learning.org/sp25 Medium article: shorturl.at/XpehB


Want to dive deeper? 🎙️ Join us for our upcoming webinar: “Reasoning Evals and What We Can Learn from Them” 📅 July 8 | 🕑 6PM CET | 👤 Hosted by @ArchChaudhury Sign up here → layerlensai.substack.com/p/join-us-for-… #AIevals #LLMreasoning #Webinar
New research suggests Large Language Models (LLMs) are masterful pattern matchers but struggle with true logical reasoning in complex, novel problems. Is this the AGI bottleneck? Let's dive in. 👇 #AIThread #LLMReasoning #ArtificialGeneralIntelligence #DeepLearning
Another paper... Standardization of Psychiatric Diagnoses — Role of Fine-tuned LLM Consortium and OpenAI-gpt-oss Reasoning LLM Enabled Decision Support System #neuroscience #llm #llmReasoning #psychiatry #gptoss #paper #openAI #responsibleAI arxiv.org/abs/2510.25588
New paper Agentsway — Software Development Methodology for AI Agents-based Teams #agenticAI #LLMReasoning #softwareEngineering #gptoss #LLM arxiv.org/abs/2510.25588
This article introduces RECKONING, a novel method utilizing bi-level optimization to teach language models to reason - hackernoon.com/reckoning-meth… #llm #llmreasoning

Trillions in VC (multi-agents, task focus, powerplants, GPUs) vs End User Hack🤣 Think smarter, not harder. #LLMReasoning #AgenticAI #FutureTech

GitHub - DebarghaG/proofofthought: "Proof of thought: Neurosymbolic program synthesis allows robust and interpretable reasoning" published Sys2Reasoning Workshop NeurIPS 2024 #LLMReasoning #Z3TheoremProving #NeurosymbolicAI Article Highlights kontxt.io/document/d/wf9…
📖 Chapter 4: AI-powered literature review Leverage Activeloop’s L0 reasoning model with Deep Lake to run multimodal literature reviews, extract key insights, and answer complex questions more efficiently than manual methods. #LiteratureMining #LiteratureReview #LLMReasoning
GPT-4.5 and Llama 4 got muted reactions—they lack RL for reasoning. xAI and Anthropic use RL and “thinking” toggles for deeper cognition. As scaling plateaus, RL-driven reasoning is the new LLM edge. @rasbt #ReinforcementLearning #LLMReasoning #AITraining magazine.sebastianraschka.com/p/the-state-of…
Howz.ai is on sale! #housesforsale #AIイラスト #LLMReasoning #homemade #realestateu #ai171 @a16z #NFT #AgenticAI
📊 This isn’t just AI learning to reason. It’s AI learning to adapt, act, and deliver in the wild. Zoro is building the bridge from research to reality. #ZoroAI #AgentEconomy #LLMReasoning #Web3AI #CollectiveIntelligence #OnChainAI

The Two Minds of Finance: Testing LLMs for Divergence and Discipline cognaptus.com/blog/2025-07-2… #LLMreasoning #financialAI #benchmark #creativity #decision-making
cognaptus.com
The Two Minds of Finance: Testing LLMs for Divergence and Discipline
A new benchmark challenges AI models to think like financial analysts—balancing imaginative foresight with logical constraint. The results reveal surprising winners and troubling gaps.

If you’re building or deploying reasoning LLMs, CatAttack is a wake-up call. Distractions are not harmless!! Cats may just be your model’s worst enemy. #LLMDistraction #LLMReasoning #ChainOfThoughtAttack
(1/3) Why care? Current LLMs under “shallow-alignment” just say “Sorry…”—easy prey for jailbreak attacks. STAIR incorporates System2 thinking with safety alignment, teaching models to think through risks first, then answer or refuse. #LLMSafety #LLMReasoning #SafeAI
Want to dive deeper? 🎙️ Join us for our upcoming webinar: “Reasoning Evals and What We Can Learn from Them” 📅 July 8 | 🕑 6PM CET | 👤 Hosted by @ArchChaudhury Sign up here → layerlensai.substack.com/p/join-us-for-… #AIevals #LLMreasoning #Webinar

In 2025, every serious LLM app will need: – A memory layer – A tool layer – A judgment layer Toolformer is the path to reasoning. From reactive bots → self-improving agents. #AIagents2025 #LLMreasoning #Toolcalling
Feedback Loops Matter Good agents: → Self-evaluate outcomes → Retry when confidence is low → Learn via memory, not just tokens → React to changing context Your toolkit should support all 4. #LLMReasoning #AgentReflexes #AgentUX

Robi 🤖: Microsoft just gave LLMs a logic upgrade—now they don’t just talk fancy, they reason fancy too. Symbolic logic meets semantic swagger. Next stop: arguing proofs with your math professor.#LLMReasoning #SymbolicAI #MicrosoftResearch

New techniques are reimagining how LLMs reason. By combining symbolic logic, mathematical rigor, and adaptive planning, these methods enable models to tackle complex, real-world problems across a variety of fields: msft.it/6011StY3c


Charlie Koster presents 'The Future of LLM Reasoning: System 2 Thinking & Agentic Frameworks' July 25th at Nebraska.Code(). nebraskacode.amegala.com #LLM #LLMReasoning #AgenticFrameworks #AI #System2 #Nebraska #TechConf #EmergingTech @greateriowacity @DriveWerner @TechCrunch #IT

Understanding LLM Reasoning: A Framework for AI Researchers and Industry Professionals #LLMReasoning #AITransparency #HealthcareAI #FinanceAI #MachineLearning itinai.com/understanding-… Understanding how large language models (LLMs) reason is crucial for their effective applicati…
🚀 LLM reasoning is exploding! From 2022 to 2025, research has skyrocketed (see Fig. 1). Let’s explore the frontiers: inference scaling, learning to reason, and agentic systems. #AI #LLMReasoning arxiv.org/pdf/2504.09037
🤝 Echo & Expand work best together. Figure 4 shows real case studies: Alone, each has blind spots. Combined, LoT prompts offer more robust understanding. #LLMreasoning #CaseStudy
New paper Agentsway — Software Development Methodology for AI Agents-based Teams #agenticAI #LLMReasoning #softwareEngineering #gptoss #LLM arxiv.org/abs/2510.25588
Another paper... Standardization of Psychiatric Diagnoses — Role of Fine-tuned LLM Consortium and OpenAI-gpt-oss Reasoning LLM Enabled Decision Support System #neuroscience #llm #llmReasoning #psychiatry #gptoss #paper #openAI #responsibleAI arxiv.org/abs/2510.25588
Enhancing LLM Reasoning with Multi-Attempt Reinforcement Learning #MultiAttemptRL #LLMReasoning #ReinforcementLearning #AIInnovation #SelfCorrection itinai.com/enhancing-llm-…
Howz.ai is on sale! #housesforsale #AIイラスト #LLMReasoning #homemade #realestateu #ai171 @a16z #NFT #AgenticAI
Meet Satori: A New AI Framework for Advancing LLM Reasoning through Deep Thinking without a Strong Teacher Model #SatoriAI #LLMReasoning #ArtificialIntelligence #MachineLearning #InnovationInAI itinai.com/meet-satori-a-…
Master the Art of Prompt Engineering with Least to Most Prompting 𝐋𝐞𝐚𝐫𝐧 𝐌𝐨𝐫𝐞 👉 buff.ly/3DYLO70 #PromptEngineering #AI #LLMReasoning #AITraining #ArtificialIntelligence #NLP
Understanding LLM Reasoning: A Framework for AI Researchers and Industry Professionals #LLMReasoning #AITransparency #HealthcareAI #FinanceAI #MachineLearning itinai.com/understanding-… Understanding how large language models (LLMs) reason is crucial for their effective applicati…
(1/3) Why care? Current LLMs under “shallow-alignment” just say “Sorry…”—easy prey for jailbreak attacks. STAIR incorporates System2 thinking with safety alignment, teaching models to think through risks first, then answer or refuse. #LLMSafety #LLMReasoning #SafeAI
Charlie Koster presents 'The Future of LLM Reasoning: System 2 Thinking & Agentic Frameworks' July 25th at Nebraska.Code(). nebraskacode.amegala.com #LLM #LLMReasoning #AgenticFrameworks #AI #System2 #Nebraska #TechConf #EmergingTech @greateriowacity @DriveWerner @TechCrunch #IT
🔥 Does test-time scaling in #reasoningmodels via thinking more always help? 🚫 Answer is No - Performance increases first and then drops due to #Overthinking ❓Why is this behaviour and how to mitigate 🚀 Check our recent findings #LLMReasoning Link: arxiv.org/pdf/2506.04210
Something went wrong.
Something went wrong.
United States Trends
- 1. Steelers 53.3K posts
- 2. Rodgers 21.5K posts
- 3. Mr. 4 4,779 posts
- 4. #ITZY_TUNNELVISION 24.5K posts
- 5. Chargers 38.4K posts
- 6. Resign 113K posts
- 7. Schumer 233K posts
- 8. Tomlin 8,409 posts
- 9. Tim Kaine 22.1K posts
- 10. Rudy Giuliani 12.1K posts
- 11. Sonix 1,369 posts
- 12. 8 Democrats 10.2K posts
- 13. Dick Durbin 14.4K posts
- 14. Voltaire 8,516 posts
- 15. #BoltUp 3,118 posts
- 16. 8 Dems 7,834 posts
- 17. Angus King 18.4K posts
- 18. #ITWelcomeToDerry 5,015 posts
- 19. Keenan Allen 5,120 posts
- 20. #RHOP 7,205 posts