#mechanisticinterpretability 검색 결과

New paper: The Resonant Cortex (SPC v3) formalizes affective override in LLMs via latent-space geometry, revealing non-biological analogs to amygdala hijacking and cognitive distortion. Open access: doi.org/10.5281/zenodo… #AIAlignment #MechanisticInterpretability #RLHF #AIEthics


We’ll be at #EMNLP2025 presenting TinySQL! Really looking forward to discussing reasoning circuits, dataset design, and model control with everyone. Poster, paper, and repo all here 👉 abirharrasse.github.io/tinysql/ Come say hi this Friday! 😊 #MechanisticInterpretability #TextToSQL

We’re presenting TinySQL: A Progressive Text-to-SQL Dataset for Mechanistic Interpretability Research at #EMNLP2025. 📍 Hall C, Session 15 🗓 Friday, Nov 7 | 14:00–15:30 Come by our poster to discuss! #TinySQL #Interpretability #TextToSQL #AISafety

Updated resources are now live: 📄 Paper: arxiv.org/abs/2503.12730 📷 Repo & site: abirharrasse.github.io/tinysql/ #EMNLP2025 #MechanisticInterpretability

The ability to properly contextualize is a core competency of LLMs, yet even the best models sometimes struggle. In a new preprint, we use #MechanisticInterpretability techniques to propose an explanation for contextualization errors: the LLM Race Conditions Hypothesis. [1/9]
![Michael_Lepori's tweet image. The ability to properly contextualize is a core competency of LLMs, yet even the best models sometimes struggle. In a new preprint, we use #MechanisticInterpretability techniques to propose an explanation for contextualization errors: the LLM Race Conditions Hypothesis. [1/9]](https://pbs.twimg.com/media/GZ3DotBXcA0U_Ht.png)

Big up to all my co-authors @lucas_prie, @tolga_birdal, and Melih Barsbey for all their help! @imperialcollege @ICComputing #MechanisticInterpretability #AdversarialRobustness #AI #ML

3/8 🤖 In the world of AI: Which neurons fire? Which circuits decide? Interpretability = mapping machine “thoughts.” We move from “it works somehow” to “I see how.” #AIethics #MechanisticInterpretability 💡

This work takes a small step toward mechanistic interpretability and trustworthy AI—understanding not only what neural networks predict, but how those predictions are computed internally. #MechanisticInterpretability #TrustworthyAI #Transformers #AIResearch #ExplainableAI (4/4)

🚀 Cooper just updated the awesome-mechanistic-interpretability repo with a new, organized directory! We believe this is the most comprehensive collection on mechanistic interpretability available online. Check it out! 🔍✨ #MechanisticInterpretability #AI #DeepLearning #ML


Explore LLM Interpretability with this comprehensive resource compilation: github.com/cooperleong00/… 📚 Tutorials, libraries, surveys, papers, blogs & more! 📂 Categorized for easy navigation 🔄 Continually updated 🗨️ Your thoughts & feedback are welcome! #NLProc #LLM
github.com
GitHub - cooperleong00/Awesome-LLM-Interpretability: A curated list of LLM Interpretability related...
A curated list of LLM Interpretability related material - Tutorial, Library, Survey, Paper, Blog, etc.. - cooperleong00/Awesome-LLM-Interpretability

Led by @ed_stevinson within the #MechanisticInterpretability subgroup, including @lucas_prie and Melih Barsbey, within my #CIRCLEGroup. We will soon release our implementation under: circle-group.github.io/research/Adver…. #AdversarialRobustness #GeometryOfThought #AI #ML #CVPR @ICComputing
circle-group.github.io
Adversarial Attacks Leverage Interference Between Features in Superposition
Imperial College London

With all the discussion about "Sparse AutoEncoders" as a way of doing #MechanisticInterpretability of LLMs, I am resharing a part of my PhD where we proved years ago about how sparsity automatically emerges in autoencoding. @NeelNanda5 arxiv.org/abs/1708.03735

Language models don’t “see” text, but they’ve built an internal ruler to count characters and decide when to break a line, like a carpenter eyeing where to cut 📏🧠 #AI #MechanisticInterpretability #NLP transformer-circuits.pub/2025/linebreak…

Unlocking AI: The Power of Mechanistic Interpretability #AIInnovation #MechanisticInterpretability #UnderstandingAI #ArtificialIntelligence #TechForGood #DataScience #PublicInterest #AIResearch #ChrisOla #TransparencyInTech

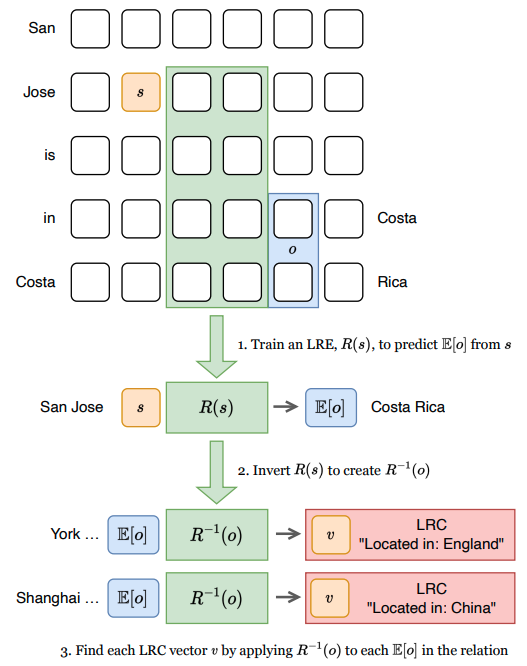
Excited to share that our paper "Identifying Linear Relational Concepts in LLMs" with @oanacamb and Anthony Hunter has been accepted to #NAACL2024! Details 👇 Paper: arxiv.org/abs/2311.08968 Code: github.com/chanind/linear… See you in Mexico! 🇲🇽 #XAI #MechanisticInterpretability

"AIのブラックボックスを可視化する:九州大学の研究が、ニューラルネットワークの隠れたパターンを解明" - Ledge.ai #DL #AI #MechanisticInterpretability l.smartnews.com/m-i2sma40/7Gg7…


From now on, even now, the most weight will be carried for thinking, intuition, depth of understanding of the intricacies. It's the root, the very core of AI systems, and that is so much more interesting! #mechanisticinterpretability
🤔 Can we find concepts in large language models more effectively than using probing classifiers? Yes! 💡In our new work with @oanacamb and Anthony Hunter, we find concept directions in #LLMs that outperform SVMs. 🔗 arxiv.org/abs/2311.08968 #XAI #MechanisticInterpretability


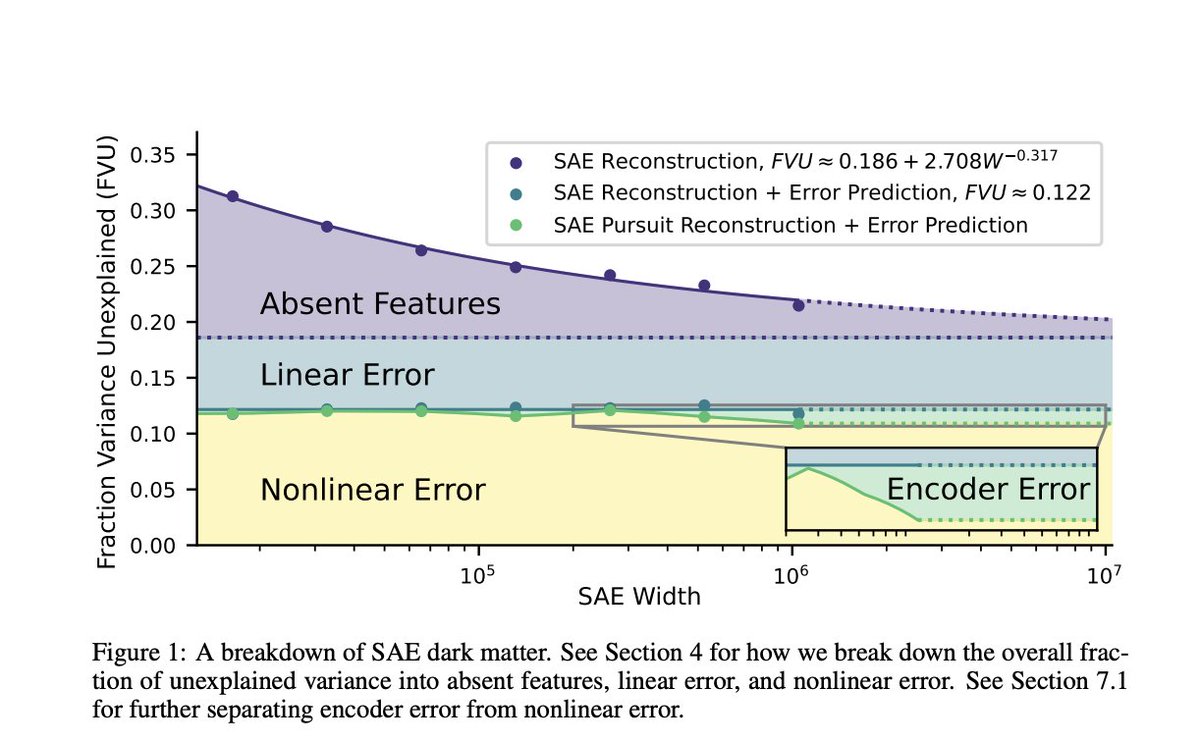
Understanding and Reducing Nonlinear Errors in Sparse Autoencoders: Limitations, Scaling Behavior, and Predictive Techniques itinai.com/understanding-… #SparseAutoencoders #MechanisticInterpretability #NeuralNetworks #AIResearch #ErrorReduction #ai #news #llm #ml #research #aine…

When “What’re you thinking?” turns into a legitimate research question. #MechanisticInterpretability

1/7 Excited to share our recent project from LASR Labs! We investigated on the utility of SAE latents in language models. #MechanisticInterpretability #SAE Here's what we discovered: 🧠🔍

In the original article, you can also read about various interesting points related to setting up the interpretation of everything that we get as a result of activation patching. How to use and interpret activation patching: arxiv.org/pdf/2404.15255 #mechanisticinterpretability
New paper: The Resonant Cortex (SPC v3) formalizes affective override in LLMs via latent-space geometry, revealing non-biological analogs to amygdala hijacking and cognitive distortion. Open access: doi.org/10.5281/zenodo… #AIAlignment #MechanisticInterpretability #RLHF #AIEthics
This work takes a small step toward mechanistic interpretability and trustworthy AI—understanding not only what neural networks predict, but how those predictions are computed internally. #MechanisticInterpretability #TrustworthyAI #Transformers #AIResearch #ExplainableAI (4/4)
Updated resources are now live: 📄 Paper: arxiv.org/abs/2503.12730 📷 Repo & site: abirharrasse.github.io/tinysql/ #EMNLP2025 #MechanisticInterpretability
We’ll be at #EMNLP2025 presenting TinySQL! Really looking forward to discussing reasoning circuits, dataset design, and model control with everyone. Poster, paper, and repo all here 👉 abirharrasse.github.io/tinysql/ Come say hi this Friday! 😊 #MechanisticInterpretability #TextToSQL
We’re presenting TinySQL: A Progressive Text-to-SQL Dataset for Mechanistic Interpretability Research at #EMNLP2025. 📍 Hall C, Session 15 🗓 Friday, Nov 7 | 14:00–15:30 Come by our poster to discuss! #TinySQL #Interpretability #TextToSQL #AISafety
Updated resources are now live: 📄 Paper: arxiv.org/abs/2503.12730 💻 Repo & site: abirharrasse.github.io/tinysql/ #EMNLP2025 #MechanisticInterpretability
Language models don’t “see” text, but they’ve built an internal ruler to count characters and decide when to break a line, like a carpenter eyeing where to cut 📏🧠 #AI #MechanisticInterpretability #NLP transformer-circuits.pub/2025/linebreak…
3/8 🤖 In the world of AI: Which neurons fire? Which circuits decide? Interpretability = mapping machine “thoughts.” We move from “it works somehow” to “I see how.” #AIethics #MechanisticInterpretability 💡
Led by @ed_stevinson within the #MechanisticInterpretability subgroup, including @lucas_prie and Melih Barsbey, within my #CIRCLEGroup. We will soon release our implementation under: circle-group.github.io/research/Adver…. #AdversarialRobustness #GeometryOfThought #AI #ML #CVPR @ICComputing
circle-group.github.io
Adversarial Attacks Leverage Interference Between Features in Superposition
Imperial College London
With all the discussion about "Sparse AutoEncoders" as a way of doing #MechanisticInterpretability of LLMs, I am resharing a part of my PhD where we proved years ago about how sparsity automatically emerges in autoencoding. @NeelNanda5 arxiv.org/abs/1708.03735
From now on, even now, the most weight will be carried for thinking, intuition, depth of understanding of the intricacies. It's the root, the very core of AI systems, and that is so much more interesting! #mechanisticinterpretability

"#MechanisticInterpretability aims to reverse-engineer #AIsystems." ai-frontiers.org/articles/the-m… #ai


@ch402 , I'd be incredibly grateful for your guidance: Are SAEs/circuits a promising path for this multilingual semantic mapping, or would you suggest other methods? Thank you for the profound inspiration! 🙏 #ResearchQuestion #MechanisticInterpretability

Ever wonder how neural nets *actually* think? 🤔 New paper "MIB" offers a benchmark to test if we can truly understand their inner workings & find causal pathways! Ready to peek under the hood? 🧰 #AI #MechanisticInterpretability
When “What’re you thinking?” turns into a legitimate research question. #MechanisticInterpretability

Anyone offering research grants for mechanistic interpretability of large language model in the form of a workstation node with 2x NVIDIA 3090 TI? #largelanguagemodel #mechanisticinterpretability
Unlocking AI: The Power of Mechanistic Interpretability #AIInnovation #MechanisticInterpretability #UnderstandingAI #ArtificialIntelligence #TechForGood #DataScience #PublicInterest #AIResearch #ChrisOla #TransparencyInTech
In the original article, you can also read about various interesting points related to setting up the interpretation of everything that we get as a result of activation patching. How to use and interpret activation patching: arxiv.org/pdf/2404.15255 #mechanisticinterpretability
"AIのブラックボックスを可視化する:九州大学の研究が、ニューラルネットワークの隠れたパターンを解明" - Ledge.ai #DL #AI #MechanisticInterpretability l.smartnews.com/m-i2sma40/7Gg7…

Let's discuss the implications of mechanistic interpretability for AI safety and ethics. Share your thoughts below. #AI #MechanisticInterpretability #GemmaScope #GoogleDeepMind #ArtificialIntelligence #MachineLearning #Innovation #Transparency #Accountability

A team at #Google #DeepMind that studies something called #mechanisticinterpretability has been working on new ways to let us peer under the hood of #AI technologyreview.com/2024/11/14/110…
technologyreview.com
Google DeepMind has a new way to look inside an AI’s “mind”
Autoencoders are letting us peer into the black box of artificial intelligence. They could help us create AI that is better understood, and more easily controlled.
New paper: The Resonant Cortex (SPC v3) formalizes affective override in LLMs via latent-space geometry, revealing non-biological analogs to amygdala hijacking and cognitive distortion. Open access: doi.org/10.5281/zenodo… #AIAlignment #MechanisticInterpretability #RLHF #AIEthics
🚀 Cooper just updated the awesome-mechanistic-interpretability repo with a new, organized directory! We believe this is the most comprehensive collection on mechanistic interpretability available online. Check it out! 🔍✨ #MechanisticInterpretability #AI #DeepLearning #ML
Explore LLM Interpretability with this comprehensive resource compilation: github.com/cooperleong00/… 📚 Tutorials, libraries, surveys, papers, blogs & more! 📂 Categorized for easy navigation 🔄 Continually updated 🗨️ Your thoughts & feedback are welcome! #NLProc #LLM
github.com
GitHub - cooperleong00/Awesome-LLM-Interpretability: A curated list of LLM Interpretability related...
A curated list of LLM Interpretability related material - Tutorial, Library, Survey, Paper, Blog, etc.. - cooperleong00/Awesome-LLM-Interpretability
Excited to share that our paper "Identifying Linear Relational Concepts in LLMs" with @oanacamb and Anthony Hunter has been accepted to #NAACL2024! Details 👇 Paper: arxiv.org/abs/2311.08968 Code: github.com/chanind/linear… See you in Mexico! 🇲🇽 #XAI #MechanisticInterpretability
The ability to properly contextualize is a core competency of LLMs, yet even the best models sometimes struggle. In a new preprint, we use #MechanisticInterpretability techniques to propose an explanation for contextualization errors: the LLM Race Conditions Hypothesis. [1/9]
🤔 Can we find concepts in large language models more effectively than using probing classifiers? Yes! 💡In our new work with @oanacamb and Anthony Hunter, we find concept directions in #LLMs that outperform SVMs. 🔗 arxiv.org/abs/2311.08968 #XAI #MechanisticInterpretability
Understanding and Reducing Nonlinear Errors in Sparse Autoencoders: Limitations, Scaling Behavior, and Predictive Techniques itinai.com/understanding-… #SparseAutoencoders #MechanisticInterpretability #NeuralNetworks #AIResearch #ErrorReduction #ai #news #llm #ml #research #aine…

I have worked on #MechanisticInterpretability of #NeuralNetworks by combining mechanistic models with NNs. However, parameter estimation is an issue. Anyone got any recommendations? @OpenAI @AnthropicAI @DeepMind @NeelNanda5 #NN #MachineLearning #ML #ExplainableAI #AI #LLM


I often claim that mechanistic interpretability is full of low hanging fruit. I want to put my money where my mouth is! Announcing 200 Concrete Open Problems in Mechanistic Interpretability Post 1 is on toy language models, plus 12 toy models I've trained! alignmentforum.org/posts/LbrPTJ4f…

Something went wrong.
Something went wrong.
United States Trends
- 1. #NXXT_NEWS N/A
- 2. Nano Banana Pro 7,072 posts
- 3. #WeekndTourLeaks N/A
- 4. Good Thursday 37.1K posts
- 5. #TheGamingAwards N/A
- 6. #thursdayvibes 3,362 posts
- 7. FINAL DRAFT FINAL LOVE 132K posts
- 8. Dick Cheney 9,128 posts
- 9. #LoveDesignFinalEP 121K posts
- 10. Haymitch 9,874 posts
- 11. Nnamdi Kanu 115K posts
- 12. The Hunger Games 76.5K posts
- 13. sohee 33.2K posts
- 14. Happy Friday Eve N/A
- 15. Pablo 64.7K posts
- 16. Reaping 67.9K posts
- 17. Ray Dalio 2,390 posts
- 18. Unemployment 28.5K posts
- 19. Janemba 2,529 posts
- 20. FAYE SHINE IN ARMANI 213K posts