#parallelcomputingmethods résultats de recherche

LoPA: Scaling dLLM Inference via Lookahead Parallel Decoding. arxiv.org/abs/2512.16229

Staggered Batch Scheduling: Co-optimizing Time-to-First-Token and Throughput for High-Efficiency LLM Inference. arxiv.org/abs/2512.16134

I'm glad this paper of ours is getting attention. It shows that there are more efficient and effective ways for models to use their thinking tokens than generating a long uninterrupted thinking trace. Our PDR (parallel/distill/refine) orchestration gives much better final…

NEW Research from Meta Superintelligence Labs and collaborators. The default approach to improving LLM reasoning today remains extending chain-of-thought sequences. Longer reasoning traces aren't always better. Longer traces conflate reasoning depth with sequence length and…


Tip: Use Python’s map() or starmap() functions in multiprocessing to apply the same operation across many inputs in parallel. #Python #Concurrency

Accelerating Sparse Matrix-Matrix Multiplication on GPUs with Processing Near HBMs. arxiv.org/abs/2512.12036

Tip: Use Python’s multiprocessing.Pool to distribute embarrassingly parallel tasks across multiple CPU cores efficiently. #Python #Concurrency


In this video, I am going to talk about the popular parallel computing methods in the fields. Let's see: youtube.com/shorts/GEFTGJI… #parallelcomputingmethods, #parallelcomputing, #parallelcomputation


Parallel computation of nonlinear RNNs by turning application of RNN over sequence of length L into L nonlinear equations and solving it with Newton's method. If we can afford nonlinearities in RNNs then it could completely change state space model related work.


Curious case of current GPU vs the desired parallelism through "I want a good parallel computer" by Raph Levien. raphlinus.github.io/gpu/2025/03/21…


Yay, our team has just published a new paper, “Shift Parallelism: Low-Latency, High-Throughput LLM Inference for Dynamic Workloads" arxiv.org/abs/2509.16495 Shift Parallelism is a new inference parallelism strategy that can dynamically switch between Tensor Parallelism and…


The secret behind Parallax’s performance lies in key server-grade optimizations: – Continuous batching: dynamically groups requests to maximize hardware utilization and throughput. – Paged KV-Cache: block-based design prevents memory fragmentation, handles thousands of…
Compared to Petals (BitTorrent-style serving), Parallax running Qwen2.5-72B on 2× RTX 5090s achieved: – 3.1× lower end-to-end latency, 5.3× faster inter-token latency – 2.9× faster time-to-first-token, 3.1× higher I/O throughput Results were consistent and showed great…

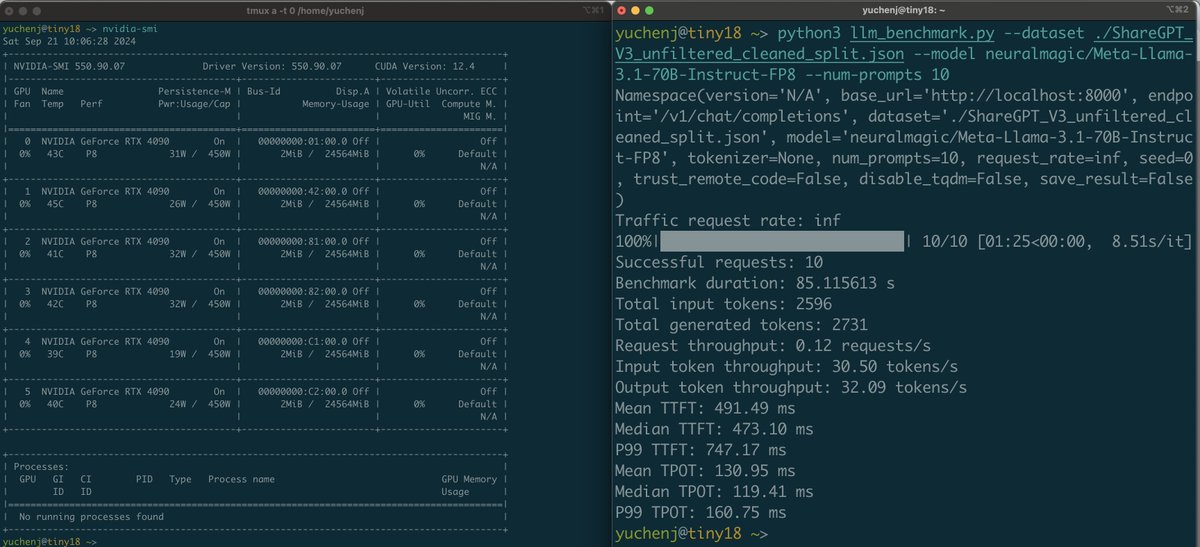
GPU tradeoff series: 𝘁𝗶𝗻𝘆𝗯𝗼𝘅 mini-series (ep. 4) The performance of Llama 3.1 70B fp8 inference on 6x4090 (tinybox green) is WAY BETTER by doing tensor parallelism with 4 of the 6 GPUs: this gives us >3X token throughput and 2X less latency to generate output tokens. 🤯…
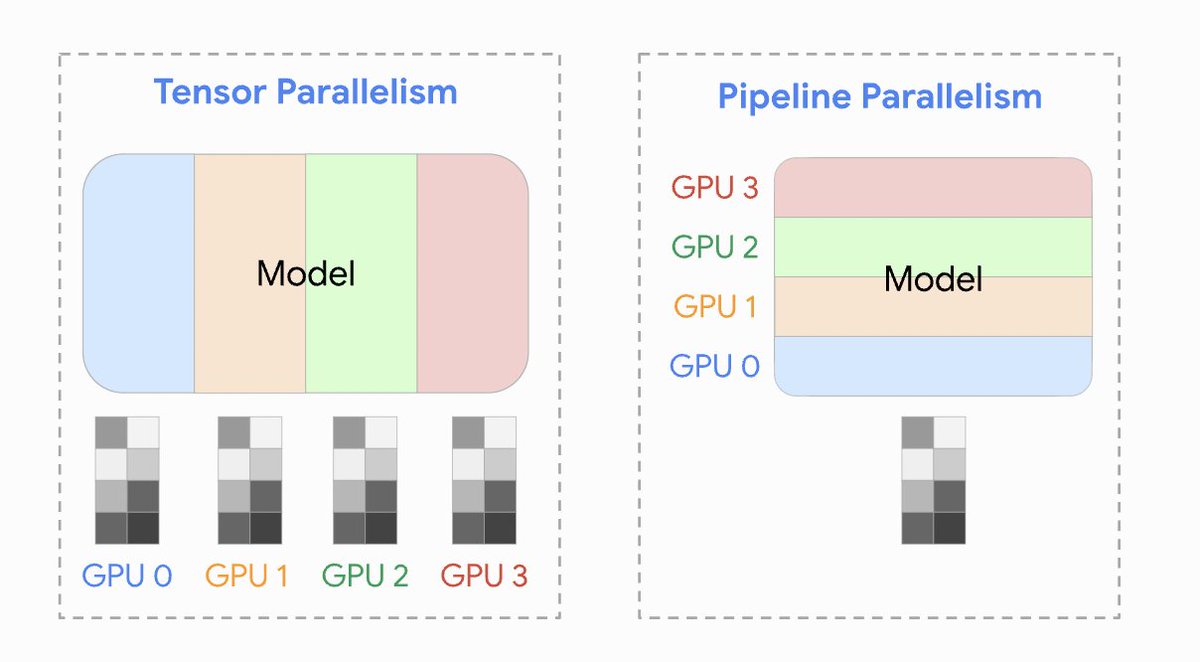
GPU tradeoff series: 𝘁𝗶𝗻𝘆𝗯𝗼𝘅 mini-series (ep. 3) Let's benchmark the performance of 6x4090 (tinybox green) when running Llama 3.1 70B inference. I'm still hoping the tinybox will have 8x4090 in the future!🤞I will explain why. Unlike training, inference doesn’t need to…

If you want to parallelize your #Pandas operations on all available CPUs by adding only one line of code, try pandarallel. 🚀 Link to pandarallel: bit.ly/3uiDLO6 ⭐️ Bookmark this post: bit.ly/42rqyz5


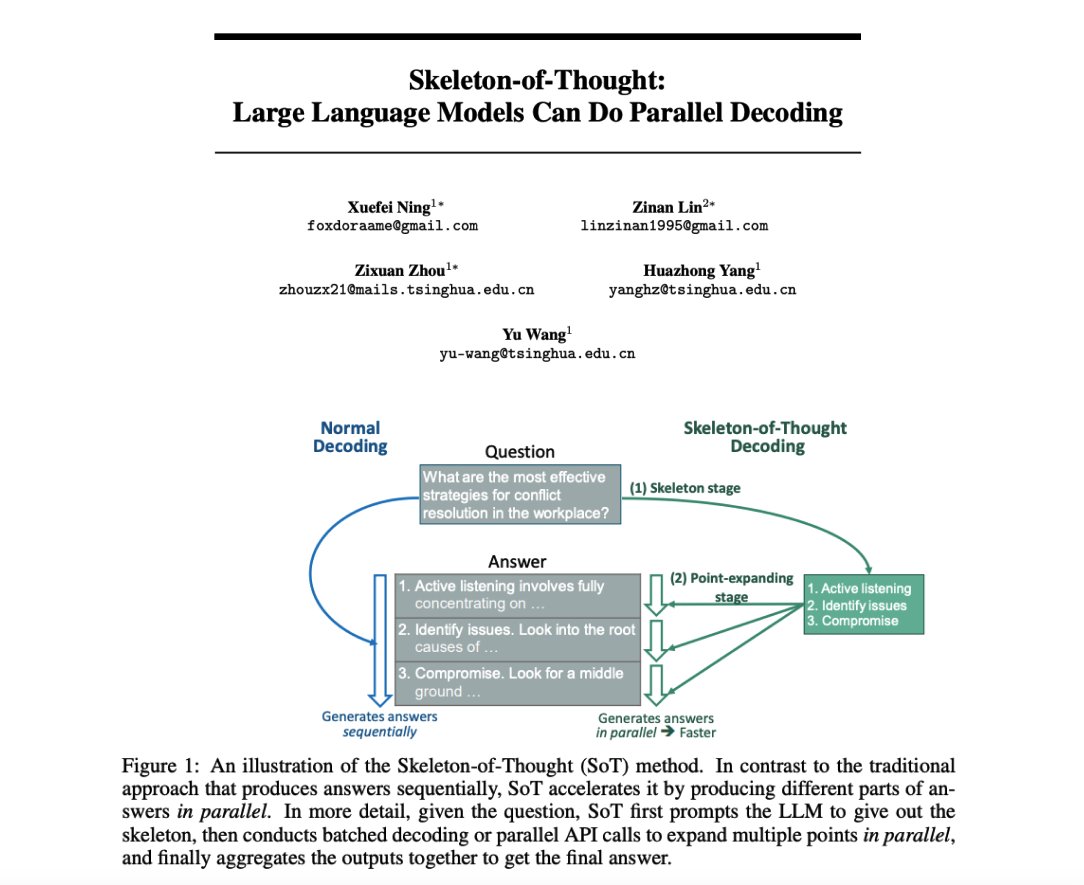
Skeleton-of-Thought: LLMs can do parallel decoding Interesting prompting strategy which firsts generate an answer skeleton and then performs parallel API calls to generate the content of each skeleton point. Reports quality improvements in addition to speed-up of up to 2.39x.…

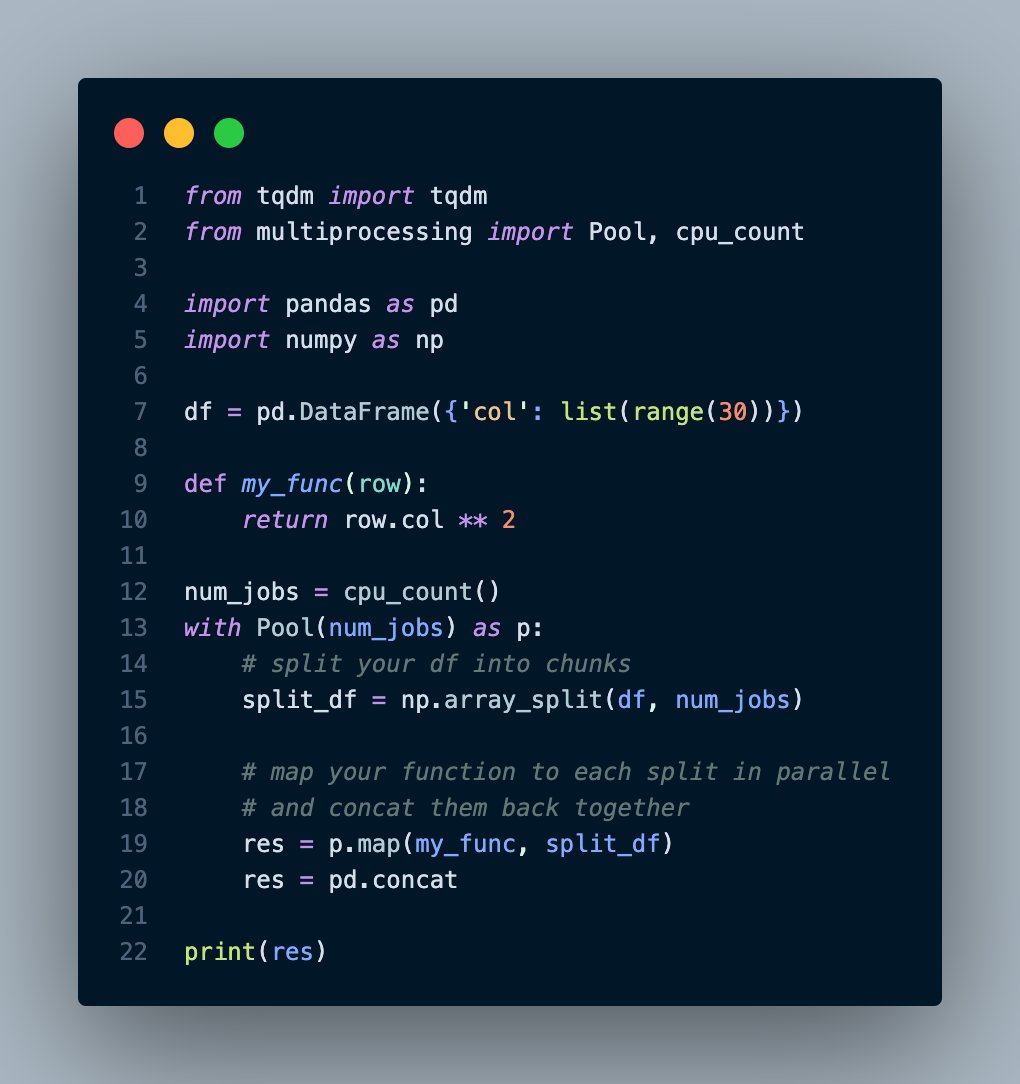
Common Pandas problem: You have a big dataframe and a function that can't be easily vectorized. So, you want to run it in parallel. Surprisingly, most answers on StackOverflow just point you to a different library. So here's a little recipe I use:

New blog post: training neural nets in parallel with JAX willwhitney.com/parallel-train… Small MLPs are 40000x smaller than a ResNet-50, but they only train 400x as fast. Training 100 in parallel gives you the missing 100x speedup. This post is a how-to.

Thought it relevant to our current book club (Practice of Programming), so I dug up this article I wrote years ago: gamasutra.com/view/news/1283…

Analyze a computation for potential parallelism, with the parallel stream library in #Java. @BrianGoetz bit.ly/2rUTNsB
Something went wrong.
Something went wrong.
United States Trends
- 1. Steelers 69.9K posts
- 2. Steelers 69.9K posts
- 3. Ravens 25.5K posts
- 4. Derrick Henry 3,657 posts
- 5. Jags 14.6K posts
- 6. Broncos 35.3K posts
- 7. #HereWeGo 8,813 posts
- 8. Goff 8,536 posts
- 9. Aaron Rodgers 8,718 posts
- 10. Contreras 9,717 posts
- 11. Boswell 3,320 posts
- 12. #PITvsDET 4,965 posts
- 13. Henderson 8,971 posts
- 14. #OnePride 5,321 posts
- 15. #DUUUVAL 4,648 posts
- 16. Teslaa 2,990 posts
- 17. Nicki 190K posts
- 18. Mike Tomlin 3,837 posts
- 19. Raiders 27.4K posts
- 20. DK Metcalf 13.5K posts