#quantizeddecoding 搜索结果
Coarsely Quantized Decoding and Construction of Polar Codes Using the Information Bottleneck Method mdpi.com/1999-4893/12/9… #informationbottleneckmethod #polarcodes #quantizeddecoding #codeconstruction #algorithms #openaccess


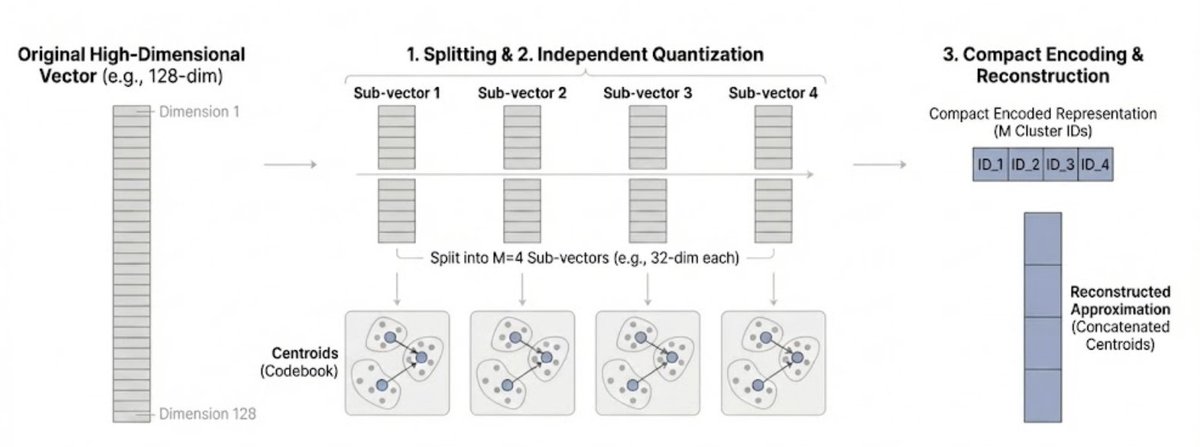
However, AI embeddings aren't single numbers; they're vectors (long lists of numbers). This is where Product Quantization (PQ), comes in. It's specifically designed to compress these vectors. It "refactors" similar embeddings to reduce duplication by using k-means clustering.…
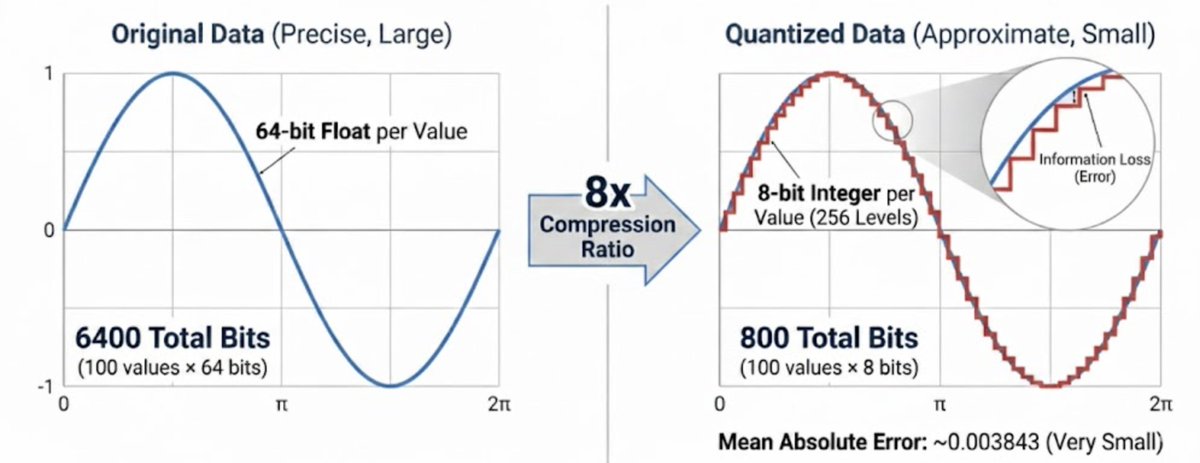
In the simplest form, quantization is a bit like rounding numbers. You give up precision to save space. With scalar quantization, instead of storing a full 64-bit number, you can store an 8-bit code representing its approximate value (8x compression ratio).

Quantization = compressing a model by lowering the precision of numbers, making it smaller, faster, and cheaper to run, often with only a small drop in accuracy. ajeetraina.com/understanding-…

✅ Bookmark : [Very Important LLM System Design #18] Quantization in LLMs: How It Actually Works naina0405.substack.com/p/very-importa…
![NainaChaturved8's tweet image. ✅ Bookmark : [Very Important LLM System Design #18] Quantization in LLMs: How It Actually Works
naina0405.substack.com/p/very-importa…](https://pbs.twimg.com/media/G65RsHtXgAALUHZ.jpg)


Hi, these are quantized version of that model, from 2bit to 16bit (original, no quant). If by original model you mean the original, then these are quant and can be used in llama.cpp and lmstudio on cheaper resources. If you mean the original quants, qwen team only releases FP8,…


You can now quantize LLMs to 4-bit and recover 70% accuracy via Quantization-Aware Training. We teamed up with @PyTorch to show how QAT enables: • 4x less VRAM with no inference overhead • 1-3% increase in raw accuracy (GPQA, MMLU Pro) Notebook & Blog: docs.unsloth.ai/new/quantizati…


Quantization in the era of reasoning models: How does quantization impact the reasoning capabilities of DeepSeek-R1 models across distilled Llama and Qwen families? 👇 Check the thread for two surprising findings in evaluations of these models!


was studying about quantization and came across this beautiful article... newsletter.maartengrootendorst.com/p/a-visual-gui…

Want to serve the LLaMA-7B with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system 🔥 🗞️ Paper - "KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization" 📌 The existing problem - LLMs are seeing…


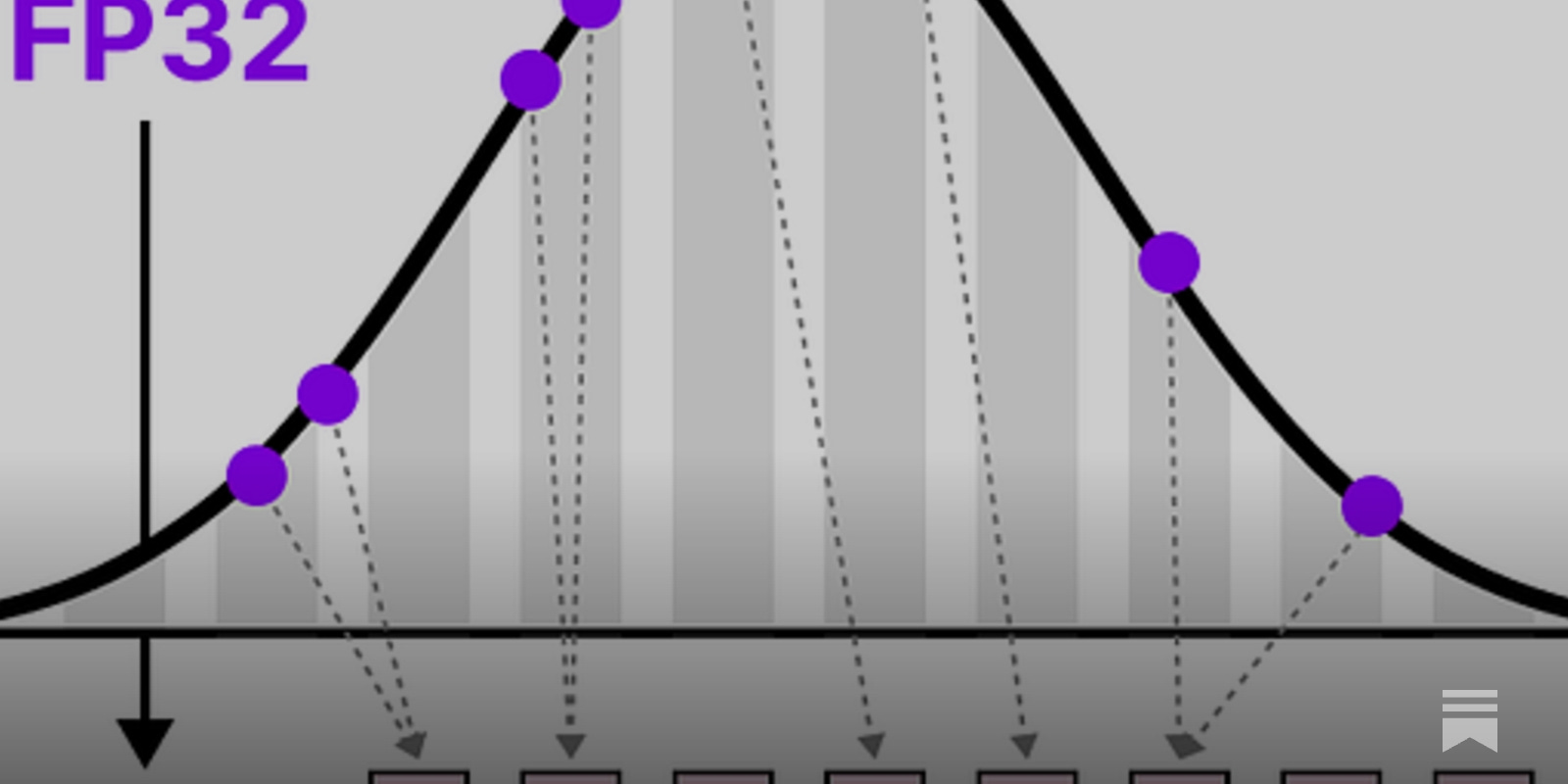
Quantization Is All You Need SOTA LLMs are too large to run on laptops. Quantization is a technique used to reduce LLMs' computational and memory requirements and create a smaller version of the model. Quantization is central to OSS progress It involves converting the model's…


Beautiful visual guide to quantization, which is becoming a super important technique for compressing LLMs. This is such a fun guide with lots of visuals to build intuition about quantization. Highly recommended!


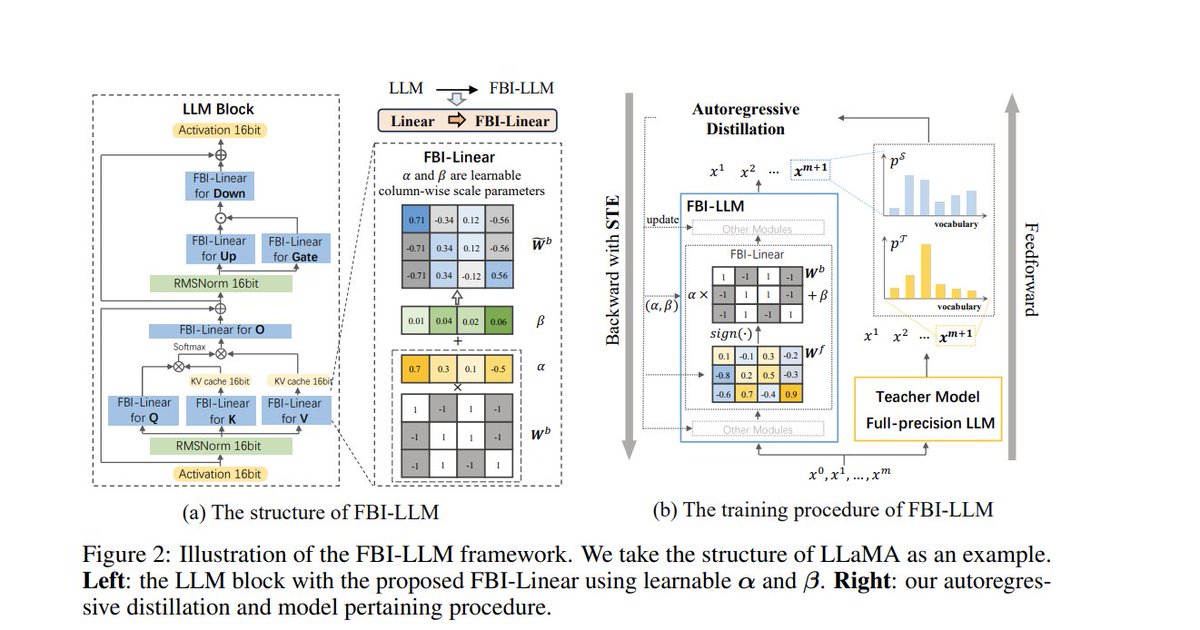
well 1bit quantization is possible now Interesting things > quantization is between -1,1 (this is a key) > need train with distillation so teacher model is required :) > column scaler instead singular scaler values > no pre norm like bitnet arxiv.org/pdf/2407.07093

Have you used quantization with an open source machine learning library, and wondered how quantization works? How can you preserve model accuracy as you compress from 32 bits to 16, 8, or even 2 bits? In our new short course, Quantization in Depth, taught by @huggingface's…

High quality video on what k-quantization is and how it works (how you fit big model on smol GPU) youtube.com/watch?v=2ETNON…
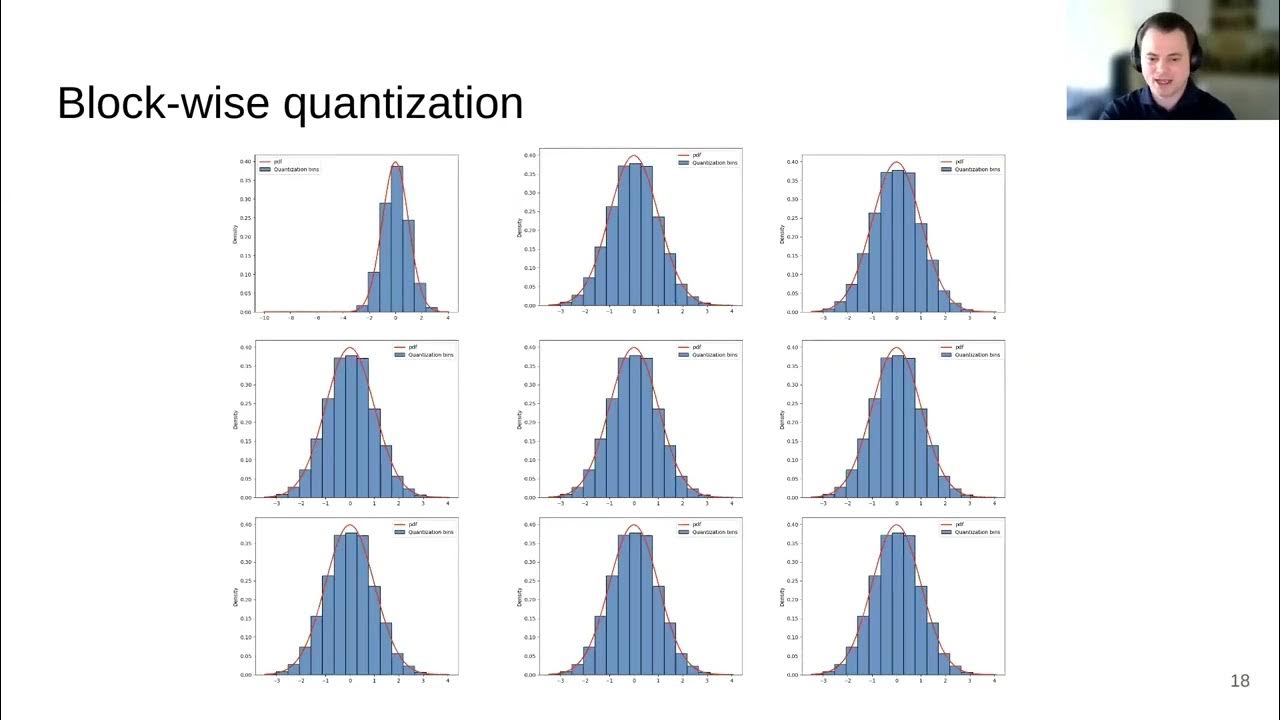
youtube.com
YouTube
8-bit Methods for Efficient Deep Learning -- Tim Dettmers (University...

What is 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗺𝗼𝗱𝗲𝗹 𝗖𝗼𝗺𝗽𝗿𝗲𝘀𝘀𝗶𝗼𝗻 and why you might need it. When you deploy Machine Learning models to production you need to take into account several operational metrics that are in general not ML related. Today we talk about two of…


One weird trick for learning disentangled representations in neural networks: quantize (arrows) the latent space into codes (circles) combinatorially constructed from per-dimension learnable scalar values (ticks). We call this latent quantization. [1/11]
![kylehkhsu's tweet image. One weird trick for learning disentangled representations in neural networks: quantize (arrows) the latent space into codes (circles) combinatorially constructed from per-dimension learnable scalar values (ticks). We call this latent quantization.
[1/11]](https://pbs.twimg.com/media/FxbFad8aYAE9FaM.jpg)

Training with QuantNoise allows to strongly compress neural networks: 80.0% accuracy on ImageNet in 3.3MB, 82.5MB accuracy on MNLI in 14MB. Blog: ai.facebook.com/blog/training-… Paper: arxiv.org/abs/2004.07320

We are releasing code and sharing details for Quant-Noise, a new technique to enable extreme compression of state-of-the-art #NLP and computer vision models without significantly affecting performance. ai.facebook.com/blog/training-…

You can now do quantization-aware training of your tf.keras models: blog.tensorflow.org/2020/04/quanti… 8-bit integer quantization leads to models that up to 4x smaller, 1.5x-4x faster, with reduced power consumption on CPU & Edge TPU. At very little loss of accuracy.
blog.tensorflow.org
Quantization Aware Training with TensorFlow Model Optimization Toolkit - Performance with Accuracy
Quantization Aware Training with TensorFlow Model Optimization Toolkit - Performance with Accuracy
Coarsely Quantized Decoding and Construction of Polar Codes Using the Information Bottleneck Method mdpi.com/1999-4893/12/9… #informationbottleneckmethod #polarcodes #quantizeddecoding #codeconstruction #algorithms #openaccess
Something went wrong.
Something went wrong.
United States Trends
- 1. Kalani 5,611 posts
- 2. REAL ID 6,979 posts
- 3. Vanguard 12.4K posts
- 4. Milagro 29.9K posts
- 5. Penn State 8,945 posts
- 6. TOP CALL 11.9K posts
- 7. Cyber Monday 60.3K posts
- 8. Admiral Bradley 10.9K posts
- 9. MRIs 4,655 posts
- 10. Hartline 3,848 posts
- 11. #OTGala11 137K posts
- 12. Merry Christmas 50.7K posts
- 13. #GivingTuesday 4,100 posts
- 14. Jason Lee 2,362 posts
- 15. Shakur 8,353 posts
- 16. Jay Hill N/A
- 17. Brent 10.1K posts
- 18. MSTR 34.9K posts
- 19. Geraldo 1,084 posts
- 20. #jimromeonx N/A